
Large Language Models (LLMs) have revolutionized how we interact with technology, offering unprecedented capabilities in natural language processing and generation. While cloud-based AI services are popular, there’s a growing trend towards local AI deployment for enhanced privacy, control, and customization. In this guide, we’ll explore how to run LLMs locally on your CPU using Dify and Ollama. This approach allows you to harness the power of AI without relying on cloud services, giving you more control over your data and reducing costs. Running LLMs locally allows for greater privacy, customization, and offline capabilities compared to cloud-based solutions.
Let us start with understanding the local deployment of LLMs.
Local LLM deployment brings the power of advanced AI to your personal computer. By using tools like Dify which is an open-source platform for building AI applications and Ollama which is an open-source project to run LLMs on local machines, you can create custom AI applications without relying on external APIs or cloud services. This approach offers several advantages such as enhanced privacy and data security, Reduced operational costs, Customization and fine-tuning capabilities, Offline functionality, Learning opportunities for AI enthusiasts and developers
Running an LLM locally is like having a personal AI assistant living on your computer. Here is an analogy to help you understand the concept: Consider an example Personal Library vs. Public Library: Running LLMs locally is like having a personal library at home. You have immediate access to all the information, but it takes up space in your house (computer). Cloud-based LLMs are like public libraries – vast resources, but you need to go there (connect to the internet) to access them.
Step 1: Install Ollama
First, let’s get Ollama up and running on your PC. Follow the instructions from the ADaSci’s blog’s “Hands-On Guide to Running LLMs Locally using Ollama“. Once you’ve completed the installation successfully, Ollama should be running on your PC. You’ll be able to interact with it locally through your command prompt.
After installation, it should look something like this:
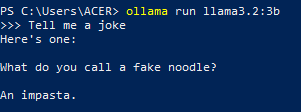
Step 2: Install Docker
Next, we’ll install Docker. Why Docker? It’s a game-changer for several reasons:
First, let’s know what exactly it is. Docker is an open-source containerization platform. Consider it like a box(Container) where we can package an app and everything it needs, like libraries and dependencies, to run. So, it can work the same no matter where you run it.
Head over to the official Docker website to download and install it.
Step 3: Fetch Dify using Git
Now, let’s get Dify on your PC. Open your command prompt and use Git to clone the Dify repository:
:
Step 4: Configure Docker
Time to get Docker configured. Run the following command:

This process might take several minutes, so be patient. Once it’s done, all the necessary Docker processes should be up and running.
Step 5: Setting up Dify
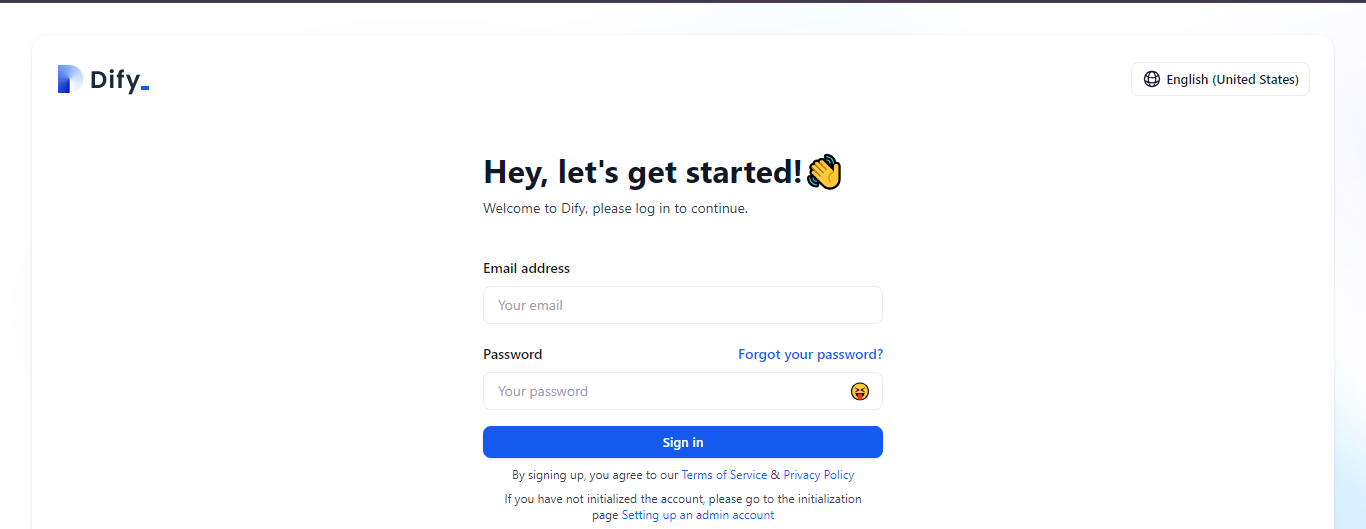
You’re almost there! Now you need to set up an admin account for Dify. Use http://localhost/install to set up an admin account. After successfully signing up, you can log in using your credentials. You should see a screen similar to this:
Pro tip: If you ever forget your password, you can reset it using the command prompt with this command:
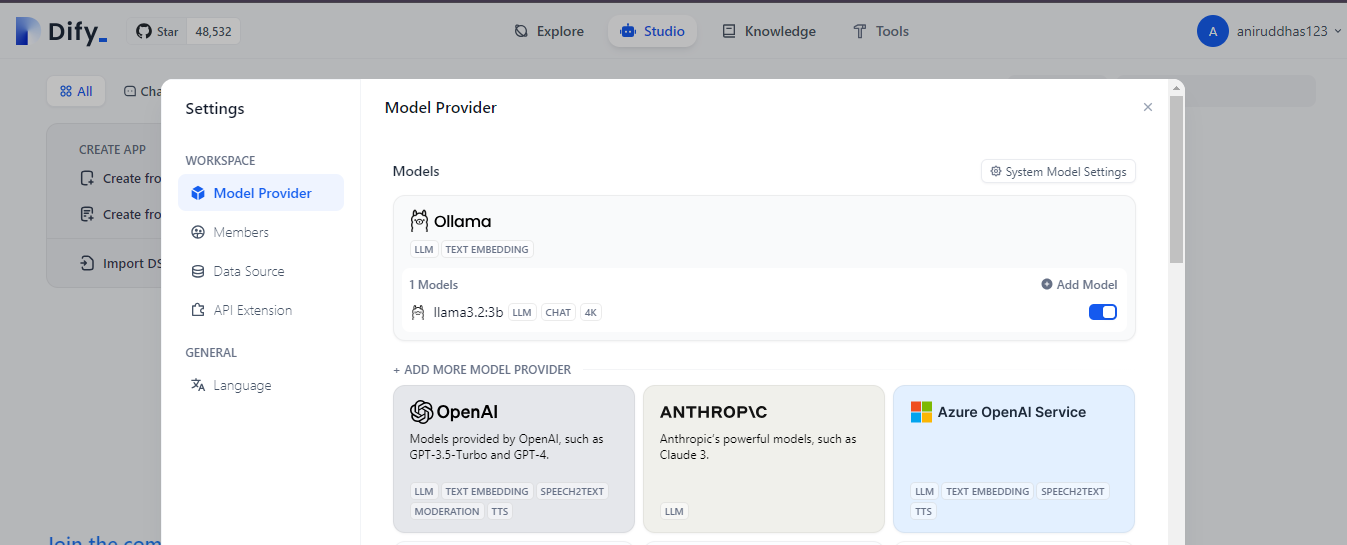
docker exec -it docker-api-1 flask reset-passwordAfter signing in, click on the top right corner of the screen. A user profile will appear; click on “Settings” there. In the Settings menu, navigate to “Model Provider” and select Ollama from the list of available models.
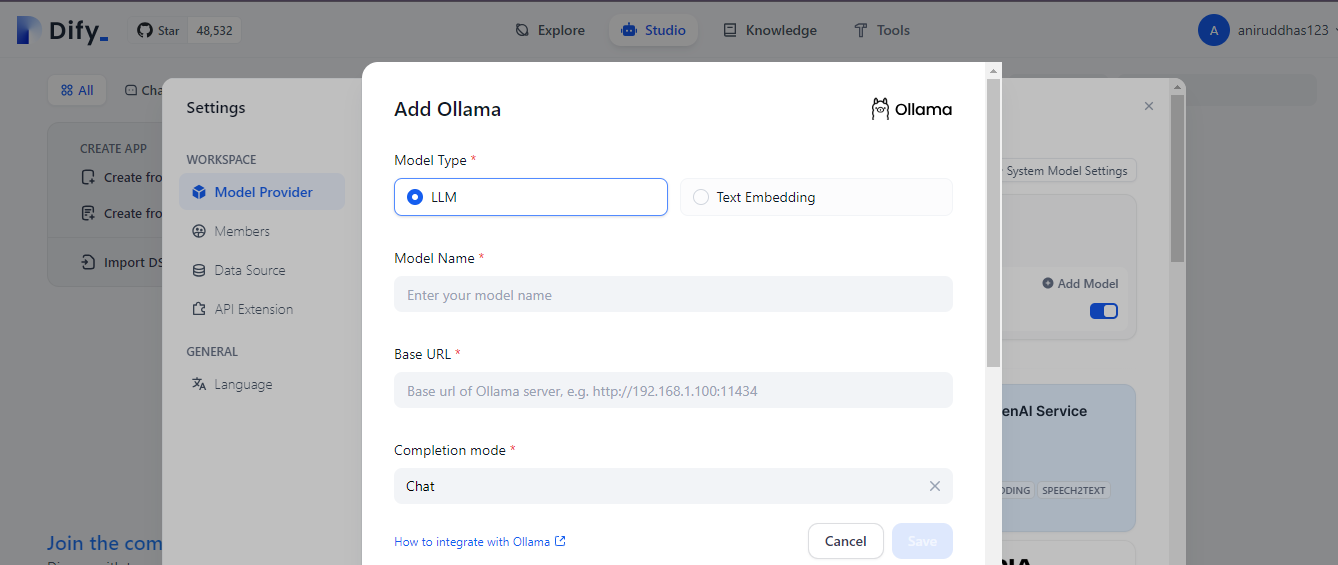
You’ll need to add some details here:
Model Name: Use the same model name that you installed using Ollama on your local PC. To find the available models, use this command:

This will give you a list of available models and their respective names. Copy the name you want to use.

As in this case, the model name is llama 3.2:3b. The same should be provided while adding ollama as the model provider.
Base URL: Use `http://host.docker.internal:11434`
After successfully adding Ollama as a model provider, it should look like this:
Now you’re ready to create an app! On the homepage, choose the “Create from blank” option.
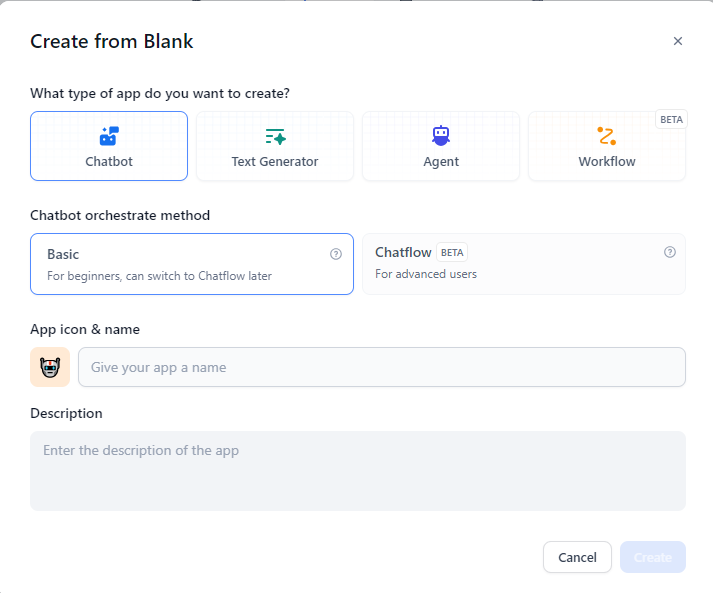
A dialog box will open. Add your app name and icon, then click the “Create” button. For this demonstration, let’s create a “Demo App”.
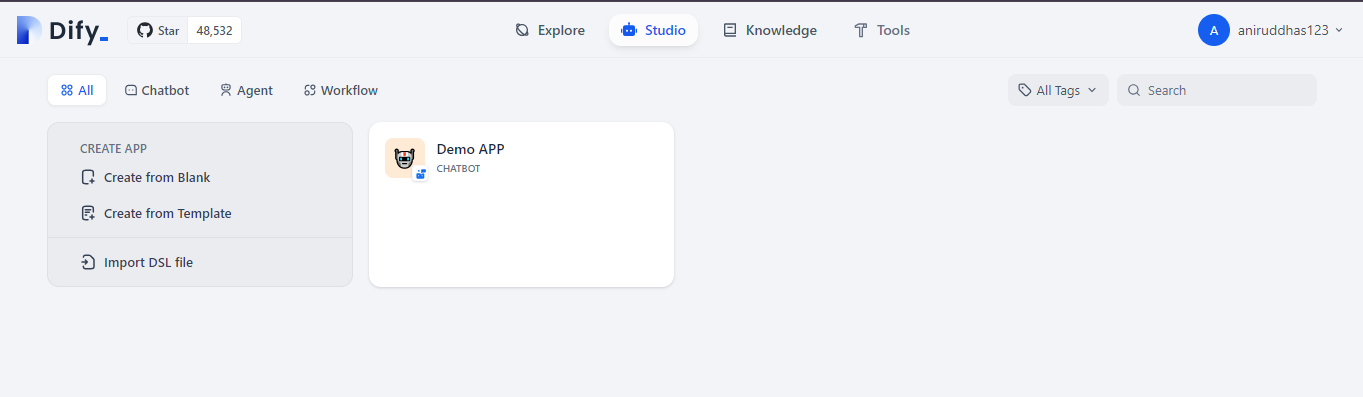
Click on your newly created Demo App. In the top right corner, you’ll see a “Publish” option – click on it.
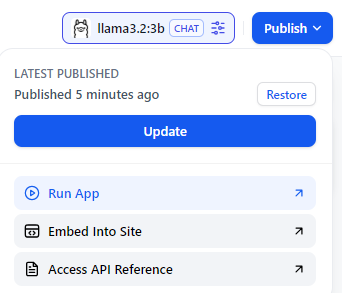
Click on “Start Chat”, and voila! You can now ask anything using this locally running LLM model on your PC.
Let’s try it out! Ask: “What are some interesting facts about India?”
Here’s what the AI might respond with:
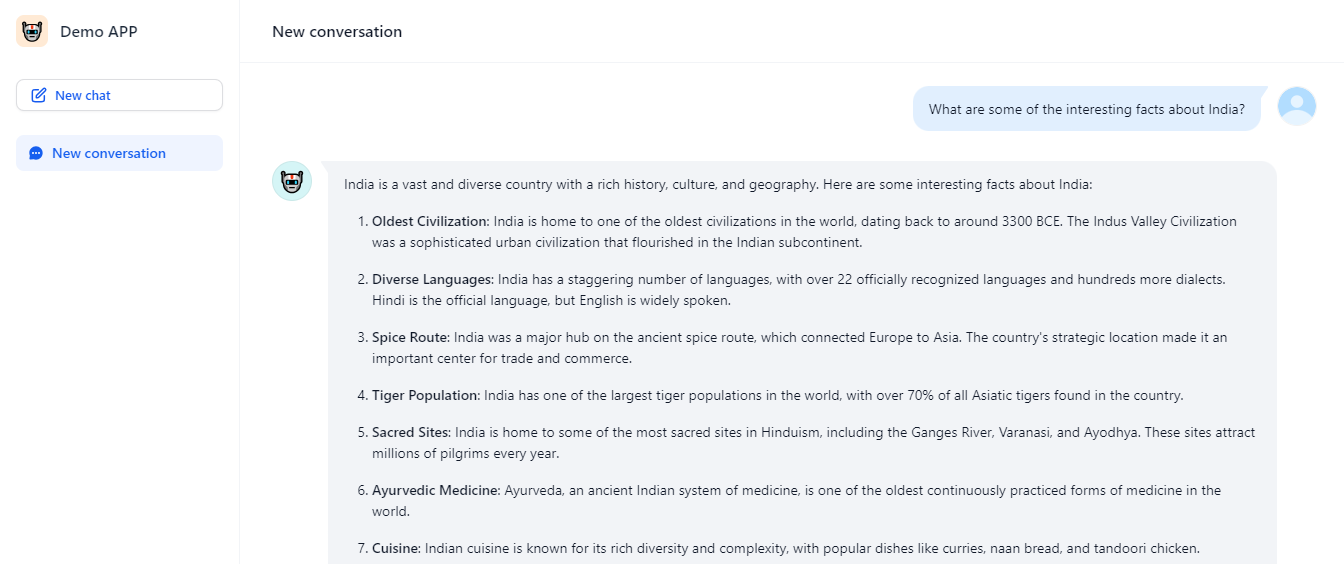
Isn’t it amazing what your locally-run AI can do? Feel free to ask more questions and explore the capabilities of your new setup!
Running LLMs locally on your CPU with Dify and Ollama opens up a world of possibilities for AI enthusiasts, developers, and privacy-conscious users. While it may require some initial setup and patience, the benefits of having a personal AI assistant at your fingertips are immense. As you explore this exciting field, remember to stay curious, experiment with different models and configurations, and share your experiences with the growing community of local LLM users.





