
AI agents’ abilities are becoming more and more dependent on how well they communicate with the internet as they develop. The goal of the open-source Python library Browser-Use is to enable LLM-based agents to access and utilize websites. It allows agents to complete complicated activities like job applications, lead generation, form-filling, and research automation with only natural language instructions, bridging the gap between AI reasoning and browser execution.
Let’s start by understanding what Browser-use is.
Browser-Use empowers AI agents to control browsers using Playwright. It interprets user-defined tasks, plans execution, navigates web elements, and performs actions like clicks, form submissions, and downloads. The tool provides programmatic access to web interfaces and supports both simple scripting and advanced memory-enabled workflows. The project is actively maintained by an open-source community and provides both local and cloud-hosted execution options for immediate deployment.
Agents are defined using a simple API that includes a task string and an LLM backend. Internally, the system:
Abstraction Layer
The core idea of “browser-use” implies an abstraction layer. This layer likely sits between the AI agent (powered by an LLM) and the web browser itself. It translates the agent’s instructions into browser actions (clicking, typing, scrolling) and extracts information from the browser in a way the agent can understand.
LLM Integration
The system is designed to work with various Language Learning Models (LLMs). This suggests a modular architecture where different LLMs can be plugged in as the “brain” of the agent.
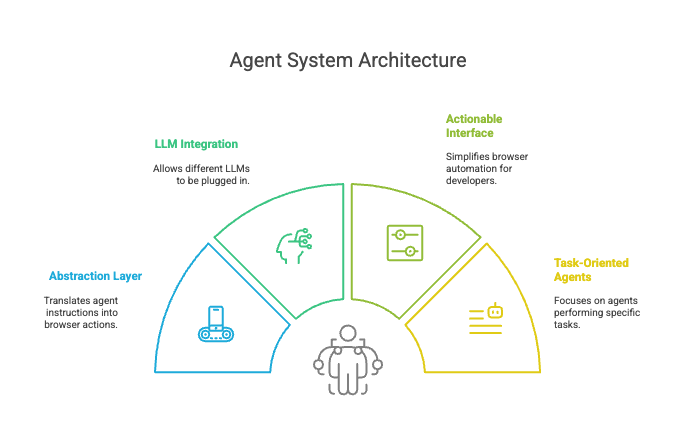
Actionable Interface
“Browser-use” provides a simplified interface for browser automation. This hints at a design that hides the complexities of direct browser manipulation (e.g., JavaScript execution, DOM manipulation) from the agent developer.
Task-Oriented Agents
The examples and descriptions focus on agents performing specific tasks (e.g., job applications, data collection). This suggests an agent design that is driven by goals or instructions The DOM extraction layer provides semantic understanding of page structures. With custom memory modules and recorded workflows, agents can execute repeatable tasks, even when the web layout changes.
%pip install uv
%pip install "browser-use[memory]"
uv pip install browser-use
uv run patchright installThis sets up a clean Python environment using uv and installs the browser-use library with memory support.
Set your Google Gemini API key in the environment
import getpass
import os
os.environ["GEMINI_API_KEY"] = "AIza..."Load the AI model integration library, browser agent module, and environment variables.
from langchain_google_genai import ChatGoogleGenerativeAI
from browser_use import Agent
from dotenv import load_dotenv
load_dotenv()Create a Gemini-powered language model to serve as the brain of your agent.
llm = ChatGoogleGenerativeAI(model='gemini-2.0-flash-exp')Define your task (e.g., “search news”, “monitor product prices”) and connect it to the Gemini model.
agent = Agent(
task="Show cheapest flight from bengaluru to nagpur",
llm=llm
)Run the agent to perform the task autonomously in a browser-powered, memory-aware context.
await agent.run()Output



The library supports a range of real-world tasks:
Browser-Use offers an essential toolkit for transforming AI agents into real-world web workers. Its modular design, multi-provider support, and ongoing roadmap make it a cornerstone of the AI-agent ecosystem. Whether you’re automating tedious workflows or building intelligent UI agents, Browser-Use provides a foundation to scale with confidence.




![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

