
Reasoning capability is at the core of advancements in Large Language Models (LLMs). However, enhancing reasoning remains a challenge, especially when relying on supervised fine-tuning (SFT), which is resource-intensive and limits scalability. The DeepSeek research team introduces DeepSeek-R1, a groundbreaking model leveraging pure reinforcement learning (RL), with promising reasoning performance across diverse benchmarks.
This article explores the architecture, methodologies, and real-world applications of DeepSeek-R1, which rivals state-of-the-art models like OpenAI’s o1 series.
Let us begin by understanding what DeepSeek-R1 is.
DeepSeek-R1 evolves from its predecessor, DeepSeek-R1-Zero, which relies solely on RL without any pre-existing SFT data. While R1-Zero exhibits emergent reasoning behaviors, it faces challenges like language mixing and limited readability. To address these, DeepSeek-R1 employs a multi-stage training pipeline that integrates a small amount of “cold-start” data, combining RL with SFT for enhanced performance and user-friendly outputs.
The family also includes distilled models (ranging from 1.5B to 70B parameters) derived from DeepSeek-R1 to empower smaller, efficient architectures with reasoning capabilities.
It employs the Group Relative Policy Optimization (GRPO) algorithm, which optimizes policy updates by leveraging group rewards without relying on a separate critic model. This reduces training overhead while maintaining performance.
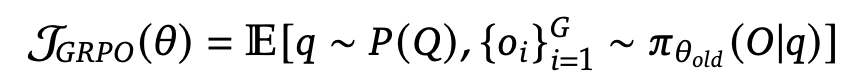
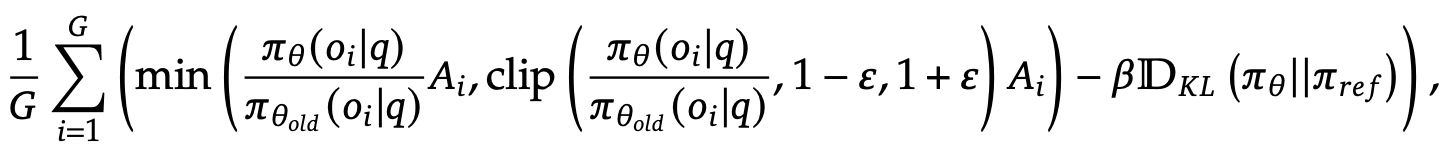
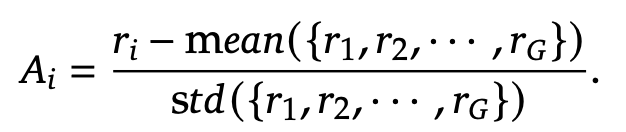
Reward Modeling:
Cold-Start Initialization:
Pretraining with carefully curated long Chain-of-Thought (CoT) data prevents instabilities observed in pure RL phases, allowing the model to start training from a robust baseline.
Rejection Sampling and Iterative SFT:
Post-RL checkpoints generate new high-quality data, refining reasoning and general-purpose capabilities.

Distillation
It extends its reasoning capabilities to smaller models using distillation. This process fine-tunes open-source models like Qwen2.5 and Llama-3 using 800,000 samples curated from DeepSeek R1 outputs, achieving exceptional benchmark performance with significantly fewer parameters.
Reinforcement Learning Without SFT
DeepSeek-R1-Zero validates that reasoning can emerge solely from RL, eliminating the dependency on large-scale labeled datasets.
Enhanced Readability and Language Consistency
Integration of language-consistency rewards during RL ensures coherent and user-friendly outputs.
Benchmark Excellence
It achieves near-parity with OpenAI-o1-1217 on reasoning tasks like AIME-2024 (79.8% Pass@1) and MATH-500 (97.3% Pass@1).
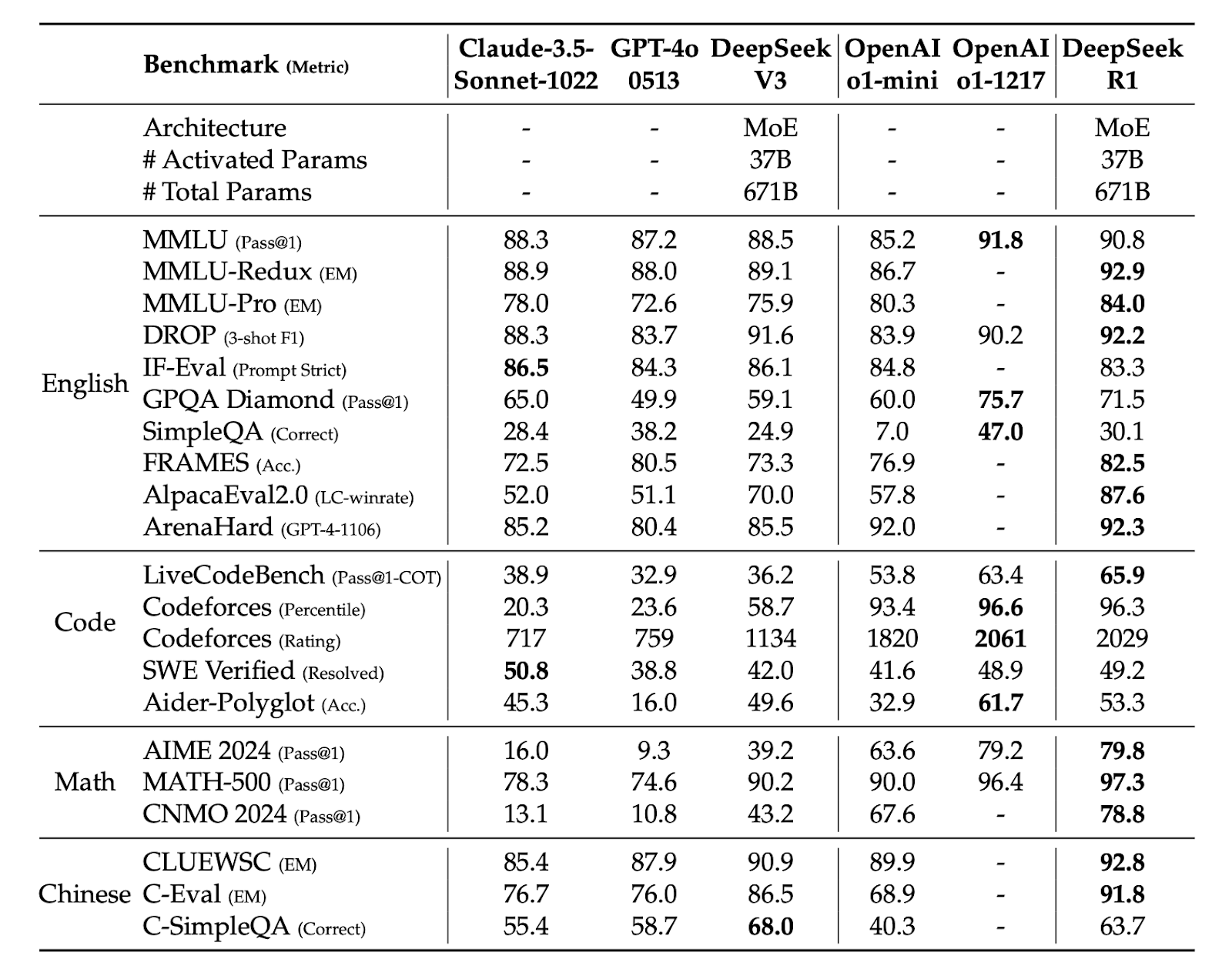
Comparison between DeepSeek R1 and other representative models
Scalability via Distillation
Distilled models outperform many larger counterparts, proving the efficiency of reasoning-focused fine-tuning.
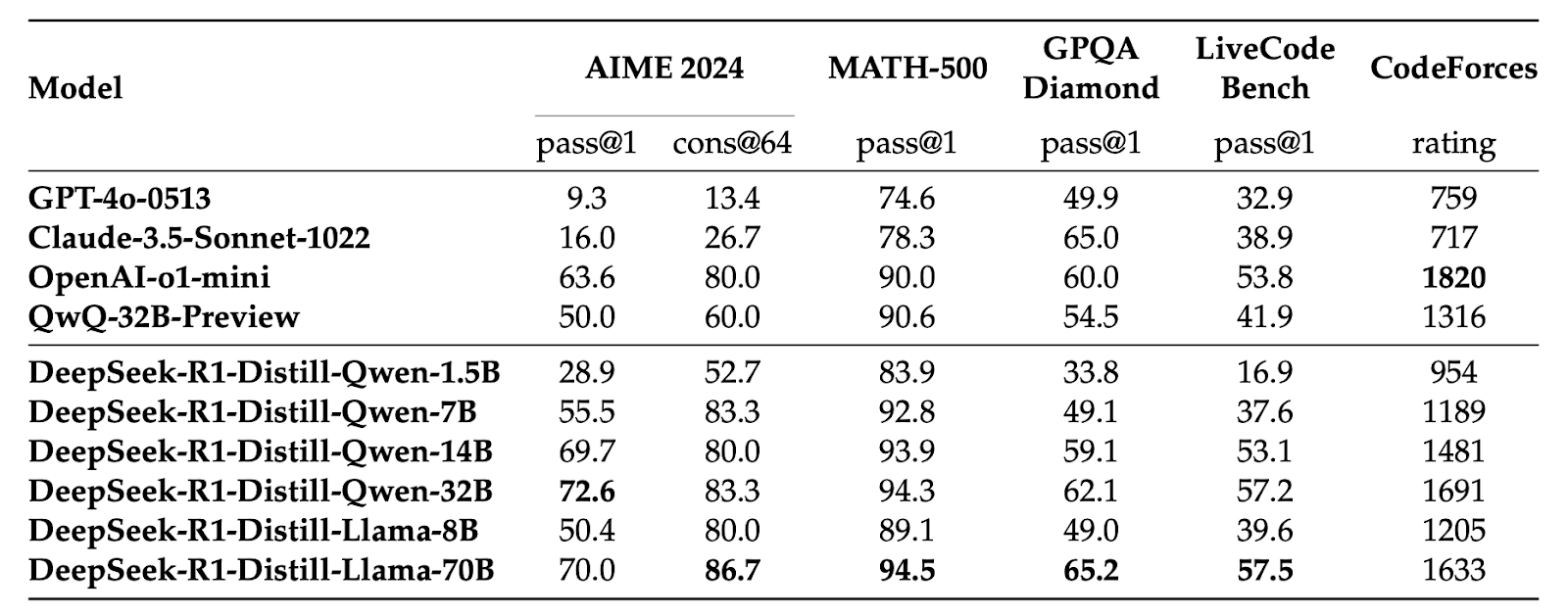
Comparison of DeepSeek R1 distilled models and other comparable models
DeepSeek-R1’s ability to handle long-context problems makes it ideal for STEM applications, achieving top-tier performance on benchmarks like AIME-2024.
Codeforces evaluations highlight it’s utility in solving competitive programming tasks, with a percentile rank of 96.3%.
The model excels in knowledge-intensive tasks such as MMLU and GPQA benchmarks, showcasing its ability to analyze complex, structured data.
Here’s a high-level implementation of DeepSeek-R1’s pipeline:
Base Model Initialization
Uses a pretrained foundation model (e.g., DeepSeek-V3-Base or Qwen2.5).
Cold-Start Fine-Tuning
Fine-tunes the model on a small dataset of structured CoT examples to establish a stable initialization.
Reinforcement Learning
Rejection Sampling
Filters RL outputs using rule-based criteria to generate high-quality supervised training data.
Iterative SFT
Merges reasoning and non-reasoning datasets to enhance general-purpose capabilities.
Distillation (Optional)
Fine-tunes smaller models using the curated dataset to create lightweight reasoning engines.
DeepSeek-R1 demonstrates the potential of RL to drive advancements in reasoning without the computational burden of large-scale SFT. Its multi-stage pipeline sets a new benchmark for combining scalability with performance. For researchers and practitioners, It offers a robust, open-source platform to explore reasoning-focused AI solutions, paving the way for the next generation of intelligent systems.





