
Knowledge graphs have traditionally been pivotal in structuring and reasoning about complex information using textual data, depicting entities and their relationships in a graph format. However, with the exponential growth and diversity of digital content, there arises a need for more inclusive representations. Enter multimodal knowledge graphs, which go beyond text-only formats by incorporating data from various modalities such as images, videos, and audio. This integration aims to provide a more holistic view of entities and their interactions, enhancing the capabilities of knowledge-driven systems across diverse domains.
These graphs have several benefits including:
Here are the top challenges faced in constructing these graphs:
Researchers have made significant strides in overcoming these challenges, developing innovative techniques and frameworks:
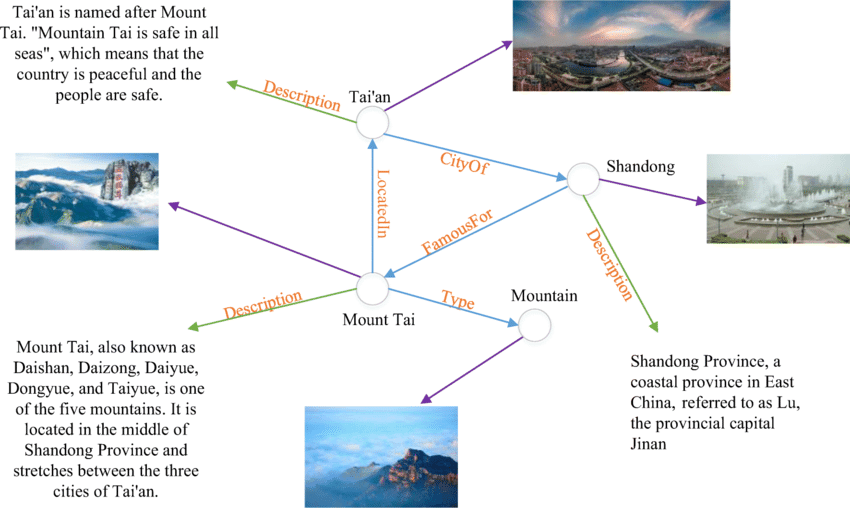
A Simple Example of Multimodal Knowledge Graph; Source: ResearchGate
MMKGs hold immense potential across various domains:
While current advancements are promising, several research directions remain:
Multimodal knowledge graphs represent a significant leap in the evolution of knowledge representation and reasoning systems. By integrating textual, visual, and other data modalities, multimodal knowledge graphs enable richer, more nuanced understanding of entities and their relationships. Despite challenges in data integration and scalability, recent advancements in deep learning and multimodal fusion techniques have paved the way for practical applications in healthcare, education, and beyond. As research continues to progress, the future of multimodal knowledge graphs holds promise in revolutionizing how we interact with and harness complex real-world knowledge.





