
In the series of Simplifying Seminal AI Papers by The Association of Data Scientists, we present in this article one of the breakthrough research papers in Generative AI. This paper, “High-Resolution Image Synthesis with Latent Diffusion Models” by Robin Rombach and the team, introduced a new method for high-resolution image synthesis using latent diffusion models.
Diffusion models (DMs) are powerful generative models that excel in image data generation. They decompose the image creation process using denoising autoencoders, allowing for image generation from noise and control over the process without retraining. DMs are computationally expensive due to their direct operation in pixel space. To overcome this, latent diffusion models (LDMs) are proposed. LDMs are trained on the latent space of a powerful pre-trained autoencoder, achieving state-of-the-art results in image synthesis while greatly reducing computational requirements. LDMs are versatile, performing tasks like text-to-image synthesis, super-resolution, and unconditional image generation.
Image synthesis is a rapidly evolving field in computer vision, but requires significant computational resources. High-resolution synthesis of natural scenes is dominated by likelihood-based models with billions of parameters or limited GANs. Diffusion models, built from denoising autoencoders, offer impressive results in image synthesis and beyond, including state-of-the-art class-conditional image synthesis and super-resolution. They can also be applied to tasks such as inpainting and colourization, without mode-collapse or training instabilities. By exploiting parameter sharing, diffusion models can model complex natural image distributions without requiring billions of parameters.
Democratizing High-Resolution Image Synthesis
Likelihood-based DMs often allocate excessive resources to model imperceptible data details, and the reweighted variational objective only partially solves this. Training and evaluating DMs are computationally demanding, often taking hundreds of GPU days and causing a carbon footprint. Evaluating a trained model is also expensive due to the sequential running of the model architecture for a large number of steps. To increase accessibility and reduce resource consumption, a method is needed to reduce the computational complexity for training and sampling without impairing performance. Addressing this is essential to enhance DMs’ accessibility.
Departure to Latent Space
To reduce the computational complexity of training diffusion models for high-resolution image synthesis, we first analyze already trained models in pixel space, identifying a perceptually equivalent but more computationally suitable space. The researchers train an autoencoder to provide a lower-dimensional, perceptually equivalent space, which we then use to train Latent Diffusion Models (LDMs). This approach allows for efficient image generation and reusability of the universal autoencoding stage for multiple DM training or different tasks. Additionally, they design an architecture for text-to-image tasks that connects transformers to the DM’s UNet backbone.
Generative modelling of high-dimensional images poses unique challenges. Generative Adversarial Networks (GANs) provide an efficient sampling of high-quality images but are difficult to optimize and struggle with capturing the full data distribution. Likelihood-based methods, such as Variational autoencoders (VAE) and flow-based models, emphasize good density estimation but fall short in sample quality. Autoregressive models perform well in density estimation but are limited to low-resolution images due to their computationally demanding architecture. To address these limitations, a two-stage approach has been developed, combining the strengths of different methods. The researchers proposed Latent Diffusion Models (LDMs) work on a compressed latent space, allowing for computationally cheaper training and faster inference with almost no reduction in synthesis quality.
The researchers propose a way to reduce the computational demands of training high-resolution image synthesis using diffusion models. By introducing an autoencoding model that learns a space equivalent to the image space but with reduced complexity, they obtain computationally efficient DMs that can be used for multiple generative models and other downstream applications.
Perceptual Image Compression
The paper proposes a perceptual compression model based on an autoencoder trained with a combination of a perceptual loss and a patch-based adversarial objective. The model uses downsampling and two different types of regularization to avoid high-variance latent spaces. The model achieves good reconstructions with mild compression rates and preserves details of the original image better than previous works that relied on an arbitrary 1D ordering of the learned space.
Latent Diffusion Models
Diffusion Models learn a data distribution by gradually removing noise from a normally distributed variable. For image synthesis, successful models use a reweighted variant of the variational lower bound on the distribution. The models consist of a sequence of denoising autoencoders trained to predict a denoised version of their input. With trained perceptual compression models, a low-dimensional latent space can be used for likelihood-based generative models. A time-conditional UNet is used as the neural backbone of the model, with the objective focused on the perceptually relevant bits of the data. Samples from the distribution can be decoded to image space with a single pass through the decoder.
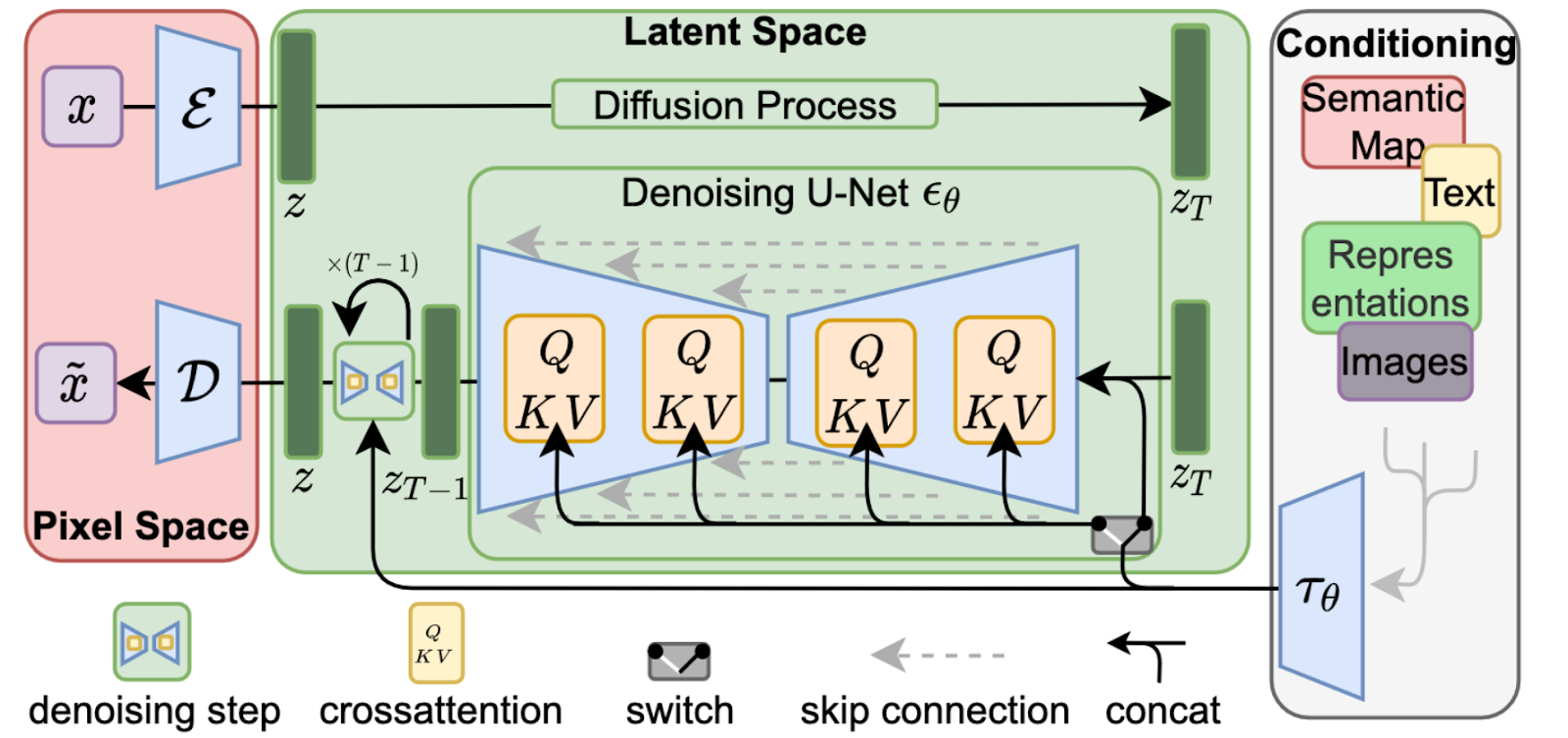
Conditioning Mechanisms
Diffusion models can model conditional distributions with p(z|y) by implementing a conditional denoising autoencoder. This allows for controlling the synthesis process through inputs such as text or semantic maps. However, combining DMs with other types of conditioning beyond class labels or blurred images is an underexplored area. To address this, the UNet backbone is augmented with cross-attention, which preprocesses inputs from various modalities such as language prompts. This conditioning mechanism is flexible, allowing for domain-specific experts like transformers when y is text prompts. The conditional LDM is learned via a joint optimization of the domain-specific encoder and the conditional denoising autoencoder.
The paper presents a new type of diffusion-based image synthesis called LDMs, which allows for the flexible and high-resolution generation of various image modalities. The researchers analyze the benefits of LDMs compared to pixel-based diffusion models and find that LDMs trained in VQ-regularized latent spaces achieve better sample quality. The paper provides details on the architecture, implementation, training, and evaluation of LDMs.
On Perceptual Compression Tradeoffs
They examine the performance of LDMs with different downsampling factors on the ImageNet dataset, where smaller downsampling factors result in slow training progress and overly large values of f cause fidelity stagnation. LDM-4 and -8 strike a good balance between efficiency and perceptually faithful results, achieving much lower FID (Fréchet Inception Distance) scores than pixel-based LDM-1 while significantly increasing sample throughput. LDM-4 and -8 lie in the best-behaved regime for achieving high-quality synthesis results, especially for complex datasets like ImageNet.
Image Generation with Latent Diffusion
The researchers trained unconditional models on four different datasets and evaluated their performance using FID and Precision-and-Recall metrics. They achieved a new state-of-the-art FID of 5.11 on CelebA-HQ and outperformed prior diffusion-based models on all but one dataset. They also consistently improved upon GAN-based methods in Precision and Recall. The authors avoid the difficulty of weighing reconstruction quality against learning the prior over the latent space by training diffusion models in a fixed space. Qualitative results are shown in the below figure.

Conditional Latent Diffusion
The researchers introduce cross-attention-based conditioning into LDMs, allowing for various previously unexplored conditioning modalities. They train a 1.45B parameter model conditioned on language prompts using a BERT-tokenizer and transformer to infer a latent code, which is mapped into the UNet via cross-attention. The resulting model shows improved text-to-image generation on the MS-COCO validation set compared to powerful AR and GAN-based methods. They also demonstrate the flexibility of the cross-attention-based conditioning mechanism by training models to synthesize images based on semantic layouts on OpenImages, and finetuning on COCO.

In conclusion, they evaluate their top-performing class-conditional ImageNet models and compare them with previous work. Their models outperform the state-of-the-art diffusion model ADM while using fewer resources and parameters.
LDMs can be used as image-to-image translation models by adding spatially aligned conditioning information to the input of the model. This is used for semantic synthesis, super-resolution, and inpainting. For semantic synthesis, landscape images with semantic maps are used, and a downsampled version of the semantic map is concatenated with the latent image representation. The model is trained on 2562 resolution but can generate larger images up to megapixel resolution. The same model is used for super-resolution and inpainting. The signal-to-noise ratio affects the results, and a rescaled version of the latent space is used to improve the results.
Super-Resolution with Latent Diffusion
LDMs can be trained to improve image quality and resolution by directly using low-resolution images as input. For example, we can take a low-resolution image and use it to train a model to create a high-resolution version of that image. In an experiment, they used a model trained on ImageNet to upscale images that were degraded using bicubic interpolation with 4×-downsampling. They found that our model produced better results than a previous method called SR3 in terms of FID, but not in terms of IS. They also conducted a user study that showed that people preferred their method over the previous method. To improve the PSNR and SSIM scores, they used a post-hoc guiding mechanism that used a perceptual loss. They also trained a more general model called LDM-BSR that could handle diverse image degradation.
Inpainting with Latent Diffusion
Inpainting means filling in missing parts of an image with new content, either because they are damaged or to replace unwanted content. They compared their method for creating new content to other state-of-the-art methods for inpainting. They tested different design choices for their method and found that our latent-based diffusion model was at least 2.7 times faster than the pixel-based model and improved the image quality by at least 1.6 times. Their method also outperformed other methods in terms of FID scores and human preference. They trained a larger model with attention layers but noticed a discrepancy in quality at different resolutions, which they fixed by fine-tuning the model.
The researchers introduced latent diffusion models, which can enhance the training and sampling efficiency of denoising diffusion models while maintaining their quality. Together with their cross-attention conditioning approach, their experiments demonstrated promising results for various conditional image synthesis tasks, without requiring specialized architectures.





![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

