
Dense retrieval has revolutionized research and question answering systems by leveraging deep neural models. However, large language models (LLMs) excel in generalization but are computationally expensive at inference time. Smaller dense retrievers offer efficiency yet often struggle with complex, multilingual data. Enter DRAMA Diverse Augmentation from Large Language Models to Smaller Dense Retrievers. This innovative framework harnesses LLM based data augmentation and strategic pruning to bridge the gap between performance and efficiency. By generating high quality training triplets and repurposing pruned LLM backbones, DRAMA paves the way for robust, scalable retrieval systems.
Lets first start by understanding what DRAMA is.
DRAMA stands at the intersection of data augmentation and model efficiency. The framework leverages diverse LLM strategies from generating cropped sentence queries to synthetic query production to enrich training data for dense retrievers. It also employs a novel pruning approach that repurposes large decoder-only models into smaller, efficient backbones. This dual strategy not only enhances generalization across languages and contexts but also dramatically reduces inference time. By shifting heavy computational costs to the training phase, DRAMA makes real time deployment of dense retrievers more feasible in resource constrained environments.
The backbone of DRAMA is built on pruned variants of LLMs such as Llama3.18B. The pruning process reduces model size to scales comparable to BERT base and XLM RoBERTa Large, while still retaining multilingual and long context capabilities. During training, the model is augmented with three types of data: queries from cropped sentences, synthetic queries generated by instruction tuned LLMs, and additional relevance judgments via listwise reranking.

Architecture Overview
Contrastive learning with the InfoNCE loss is employed to optimize the similarity between queries and documents. Importantly, enabling bi directional attention transforms a decoder-only architecture into a potent dense retriever, blurring the lines between traditional encoder and decoder models.
DRAMA offers several standout features:
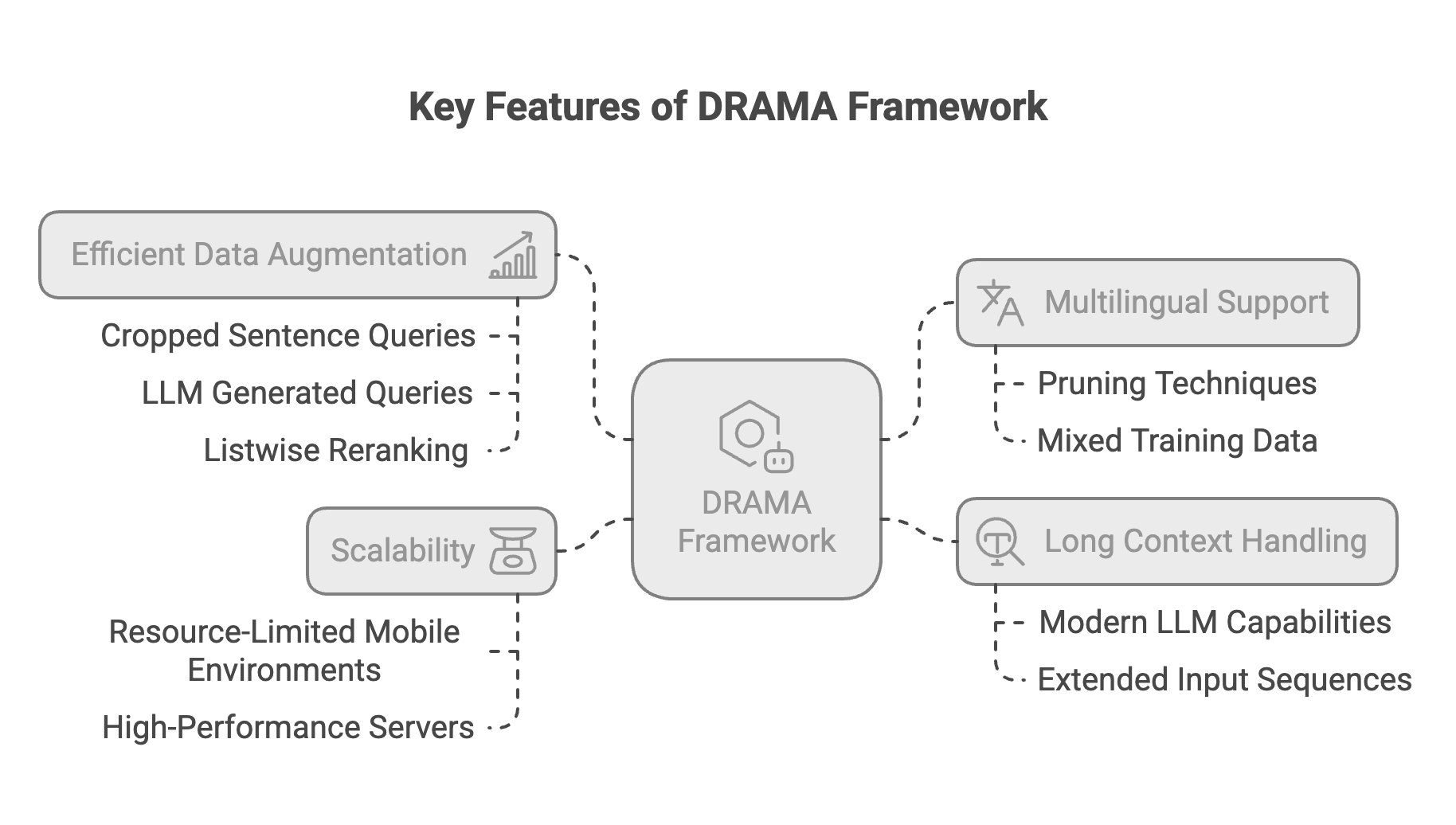
Key Features of DRAMA
The advances in DRAMA may be used right away in a variety of fields:
DRAMA begins by creating a diverse augmentation dataset. For each document in a large corpus, random sentence cropping extracts pseudo queries. Concurrently, an instruction tuned LLM generates synthetic queries that mimic real world search behavior. Additionally, listwise reranking refines candidate document selection, ensuring that the top ranked document is truly relevant. This multi pronged approach results in high quality query–document pairs used for training.
The framework initializes with a large decoder only model, such as Llama3.18B. Through a structured pruning process, the model is reduced to smaller sizes (e.g., 0.1B or 0.3B parameters). A learned parameter mask selectively trims redundant weights, followed by continuous pretraining to recover performance. Crucially, bi directional attention is enabled post pruning, allowing the model to capture context in both directions.
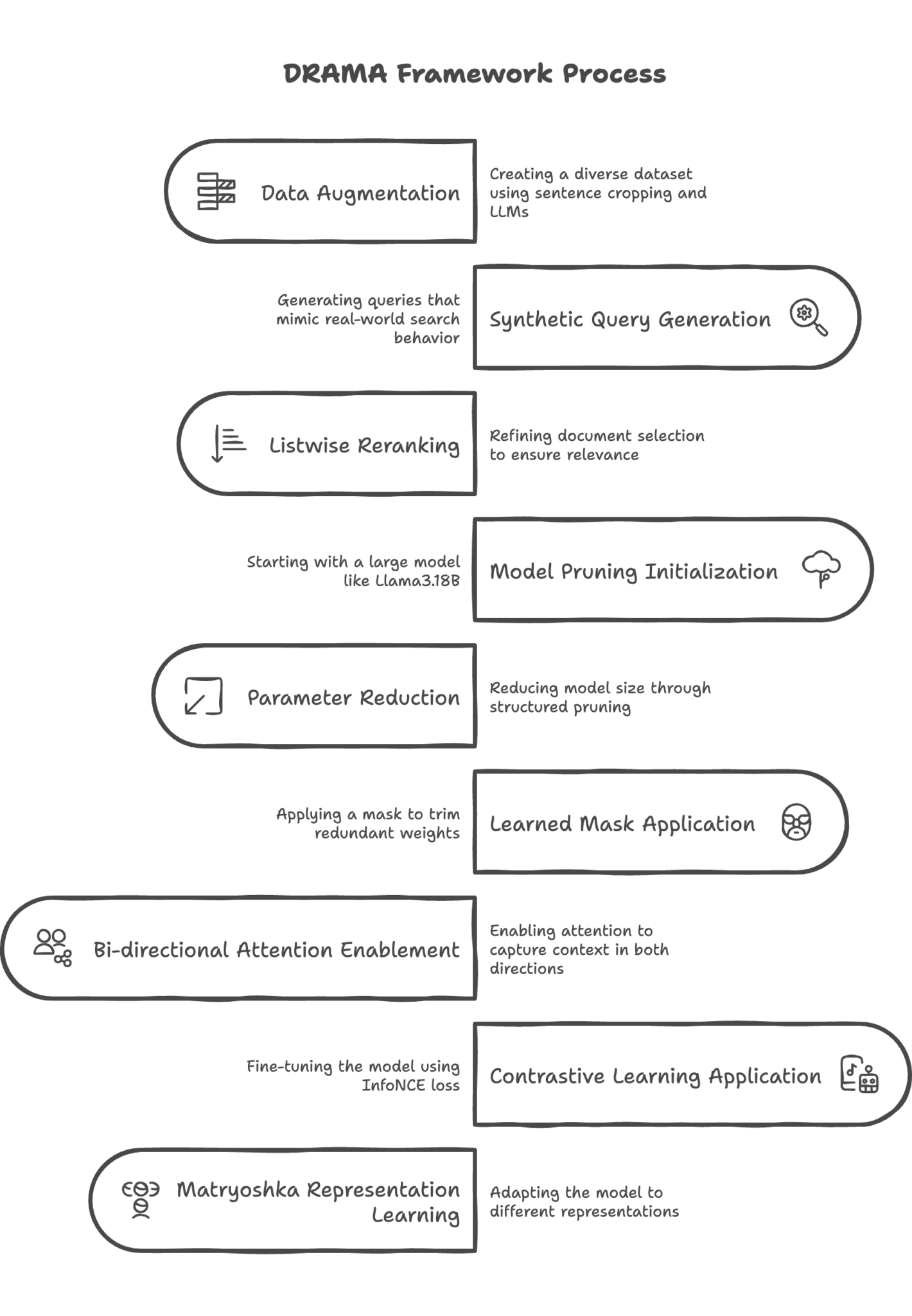
DRAMA Framework Process
Techniques from contrastive learning are used to fine-tune the trimmed model. The InfoNCE loss, which is used in training, minimizes the similarity between a query and its hard negative document while maximizing that between a query and its positive document. Matryoshka Representation Learning enhances this procedure by adapting the model to different representation dimensions, guaranteeing that the retriever continues to function even when memory is limited.
Lastly, a supervised fine tuning dataset (like the E5 fine tuning data) is combined with the enhanced training data. Several GPUs are used to train the model, balancing performance and efficiency. Comprehensive tests on benchmarks including BEIR, MIRACL, and MLDR show that DRAMA regularly performs better than traditional methods, particularly in tasks involving multilingual and extended context retrieval.
The dense retrieval field has advanced significantly with DRAMA. It strikes a good balance between efficiency and performance by taking use of the advantages of large language models and carefully trimming them. From online search to multilingual information retrieval, the framework’s creative data augmentation techniques and adaptable design make it a useful tool for a variety of applications.
References




