LLM Fine-Tuning is a critical process that allows these models to adapt to specific tasks and domains, enhancing their performance significantly. As organizations increasingly rely on LLMs for various applications—ranging from customer service to content generation—the need for effective fine-tuning strategies becomes paramount. This article explores the intricate process of fine-tuning LLMs, highlighting essential tools, techniques, and the challenges practitioners may encounter.
Table of Contents
What is LLM Fine-Tuning?
Essential Tools and Frameworks
Techniques for Effective Fine-Tuning
Practical Use Cases
Key Challenges and Solutions
What is LLM Fine-Tuning?
Fine-tuning is essential when deploying LLMs in specialized environments. While pre-trained models possess a broad understanding of language, they often lack the specificity required for particular tasks. Fine-tuning adjusts these models by training them on smaller, task-specific datasets, allowing them to better understand unique terminologies and contexts.
The importance of fine-tuning cannot be overstated; it transforms general-purpose models into tailored solutions that meet the nuanced demands of specific applications. For instance, a model like GPT-3 can be fine-tuned to excel in medical documentation or legal text analysis, making it far more effective than its out-of-the-box version.
Transforming LLMs for Specific Tasks
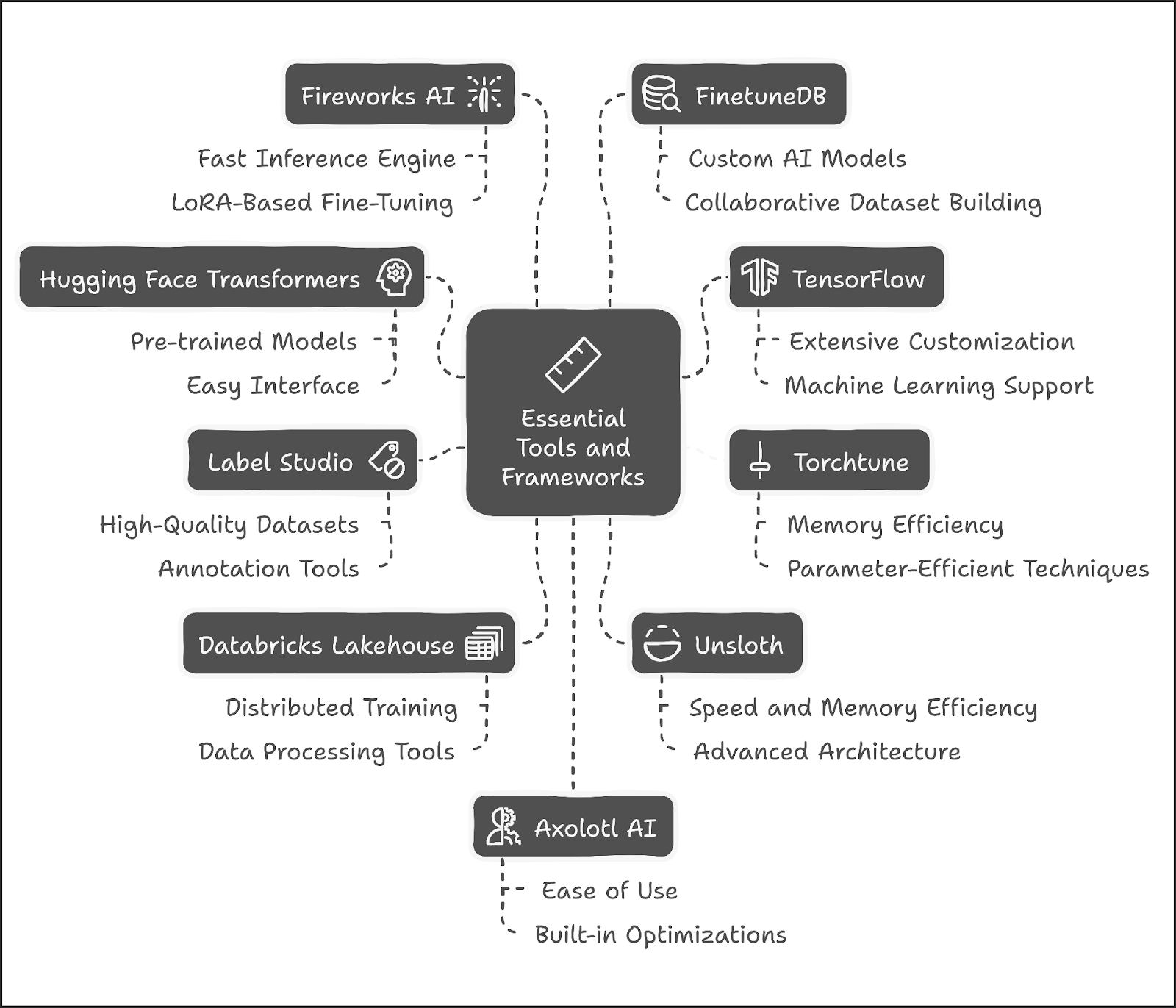
Essential Tools and Frameworks
Several tools and frameworks facilitate the fine-tuning of LLMs:
Hugging Face Transformers: This library provides pre-trained models and an easy-to-use interface for fine-tuning various architectures, including BERT and GPT variants.
TensorFlow: A robust machine learning framework that supports extensive customization during the fine-tuning process.
Torchtune: It is a PyTorch-native library for easily fine-tuning large language models with customizable workflows and support for consumer-grade GPUs
Label Studio: This tool aids in data annotation, ensuring high-quality datasets for training.
Databricks Lakehouse: A platform that integrates data processing and machine learning tools, streamlining the fine-tuning process with distributed training capabilities.
Essential Tools and Frameworks
In addition to these popular tools, several advanced platforms stand out for their unique capabilities:
Unsloth
Unsloth is a cutting-edge tool that significantly enhances the fine-tuning of LLMs, achieving remarkable efficiency.
Key Features:
Speed and Memory Efficiency: Unsloth allows fine-tuning to be completed up to 2x faster while using 70% less memory compared to traditional methods. This is particularly beneficial for users with limited computational resources.
Advanced Architecture: Built on OpenAI’s Triton language, Unsloth employs a custom backpropagation engine that accelerates training without sacrificing accuracy. It supports models like Llama-3 and Mistral.
User-Friendly: With comprehensive documentation and easy installation, Unsloth is accessible for both beginners and experienced developers. It integrates well with platforms like Google Colab for enhanced training capabilities.
Parameter-Efficient Fine-Tuning (PEFT): Utilizes techniques like Low-Rank Adaptation (LoRA) to optimize model performance while minimizing resource usage.
Fireworks AI offers a high-performance platform optimized for generative AI, fine-tuning, and fast model deployment. It enables enterprises and startups to build production-ready AI systems with cutting-edge technologies, offering a smooth path from prototype to production AI.
Key Features:
Fastest Inference Engine: Provides up to 9x faster retrieval-augmented generation (RAG) and 6x faster image generation.
Blazing Fast Inference: Supports 100+ models like Llama3 and Mixtral with FireAttention, a custom CUDA kernel, for unmatched speed and throughput.
LoRA-Based Fine-Tuning: Cost-efficient and scalable fine-tuning service with instant deployment and model switching.
Multimodal AI Systems: Supports the composition of AI systems using text, audio, image, embeddings, and external tools for comprehensive automation and domain-specific tasks.
FinetuneDB
FinetuneDB is a powerful AI fine-tuning platform designed to enable the rapid creation of custom LLMs by training models on your own data. With features to manage multiple models and datasets, it allows AI teams to fine-tune models efficiently and collaboratively at scale.
Key Features:
Custom AI Models: Create proprietary fine-tuning datasets to optimize model performance for specific business needs.
Collaborative Dataset Building: Teams can collaborate seamlessly using a shared editor to create and refine fine-tuning datasets.
Automated Evaluation and Improvement: Copilot automates the evaluation and improvement process, ensuring consistent model enhancement.
Integration Flexibility: Easy integration with production applications via SDKs, Web API, and Langchain support.
Axolotl AI
Axolotl is an Open Source tool designed to simplify the fine-tuning of LLMs
Key Features:
Ease of Use: It serves as a wrapper around Hugging Face libraries, allowing users to focus on data rather than technical intricacies.
Built-in Optimizations: Axolotl comes with default configurations that enhance training efficiency, such as sample packing, which improves batch processing during training.
Compatibility: It supports various models available on Hugging Face, including LLaMA and Pythia, making it versatile for different applications.
Noteworthy Platforms for Data Annotation and Experimentation
Data Annotation and Experimentation are critical components of the fine-tuning process. High-quality, accurately labeled datasets are essential for training LLMs to perform specific tasks. Additionally, systematic experiment tracking ensures that fine-tuning efforts are optimized, providing insights into the effectiveness of different techniques and configurations.
Kili specializes in high-quality data annotation, crucial for fine-tuning LLMs. It integrates seamlessly into workflows and offers active learning features to help prioritize annotation tasks.
Key Features:
Collaborative Annotation: Team-based annotation for faster data labeling.
Active Learning: Prioritizes annotation of uncertain or underrepresented data.
Labelbox offers a comprehensive solution for data labeling, model iteration, and management. It ensures a smooth data annotation workflow, supporting cloud-agnostic environments.
Key Features:
Integrated Pipeline: Data collection, model iteration, and training management in one platform.
Scalable Annotation: Suited for both small and large datasets.
SuperAnnotate provides a comprehensive platform for dataset management and model fine-tuning. It features a powerful mix of manual and AI-assisted annotation tools, making it suitable for teams of all sizes.
Key Features:
AI-Assisted Annotation: Includes auto-annotation and tracking.
Data Governance: Strong integrations for model iteration and governance.
Collaboration Tools: Features like project management and quality assurance for teams.
W&B is essential for experiment tracking, collaboration, and model management. It helps teams monitor training progress, fine-tune hyperparameters, and visualize model performance.
Key Features:
Experiment Tracking: Monitor all aspects of model training.
Collaborative Tools: Share findings with teams in real-time.
Data annotation ensures that LLMs receive the correct and relevant data for fine-tuning, while experimentation platforms allow teams to track and optimize the fine-tuning process, enhancing the overall efficiency and effectiveness of the model.
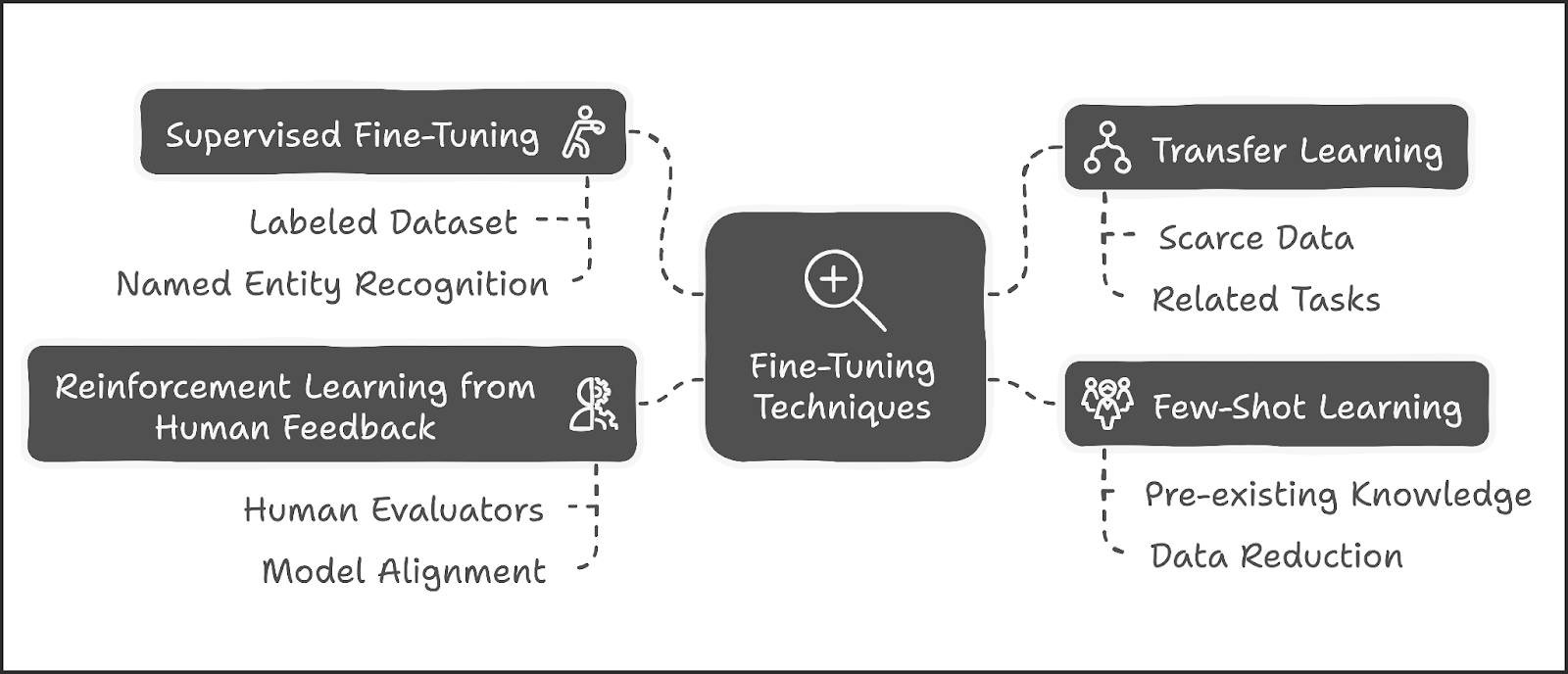
Techniques for Effective Fine-Tuning
Fine-tuning can be approached through various techniques, each suited for different scenarios:
Supervised Fine-Tuning: Involves training on a labeled dataset where input-output pairs are provided. This method is effective for tasks like sentiment analysis or named entity recognition.
Transfer Learning: Utilizes knowledge gained from one task to improve performance on another related task. This approach is particularly useful when labeled data is scarce.
Few-Shot Learning: Allows models to learn from a limited number of examples by leveraging pre-existing knowledge. This technique can significantly reduce the amount of data needed for effective training.
Reinforcement Learning from Human Feedback (RLHF): Involves training models based on feedback from human evaluators, aligning model outputs more closely with human preferences.
Techniques for Effective Fine-Tuning
Each technique has its strengths and weaknesses, making it crucial to select the appropriate method based on the specific requirements of the task at hand.
Practical Use Cases for Fine-Tuned LLMs
Fine-tuned LLMs can be leveraged in specialized, high-impact domains:
Legal Document Drafting: Automate contract creation and legal document review using models trained on legal texts to ensure compliance and accuracy.
Medical Diagnosis: Train models on medical data to assist in diagnosing diseases and recommending treatments based on clinical data and literature.
Financial Risk & Fraud Detection: Detect fraudulent transactions and assess financial risks by analyzing historical data, improving decision-making.
Personalized Education: Create tailored learning experiences and adaptive assessments by training models on student performance and curricula.
Crisis Management: Predict and manage responses to disasters by analyzing real-time data from multiple sources to optimize resource allocation.
Creative Industries: Assist in scriptwriting, storytelling, and game development by generating plots, dialogues, and narratives in specific genres.
These use cases demonstrate how fine-tuned LLMs can deliver substantial improvements in performance over general-purpose models.
Key Challenges and Solutions
While fine-tuning offers numerous benefits, practitioners often face several challenges:
Data Quality Issues: Poorly labeled or insufficient data can lead to suboptimal model performance. Ensuring high-quality datasets through rigorous preprocessing and validation is essential.
Computational Resource Constraints: LLM Fine-tuning requires significant computational power. Techniques such as Gradient Checkpointing or Low-Rank Adaptation can help mitigate memory usage without sacrificing performance.
Overfitting: The risk of a model becoming too specialized on the training data can lead to poor generalization. Implementing strategies like dropout regularization and monitoring validation loss can help prevent this issue.
By proactively addressing these challenges, practitioners can enhance the effectiveness of their fine-tuning efforts.
Final Thoughts
LLM Fine-tuning large language models is a complex yet rewarding endeavor that significantly enhances their applicability across various domains. By understanding the key tools, techniques, and challenges involved in this process, Engineers can optimize their models for specific tasks effectively. As you embark on your own fine-tuning projects, consider experimenting with different approaches to discover what works best for your unique requirements.
Aniruddha Shrikhande
Aniruddha Shrikhande is an AI enthusiast and technical writer with a strong focus on Large Language Models (LLMs) and generative AI. Committed to demystifying complex AI concepts, he specializes in creating clear, accessible content that bridges the gap between technical innovation and practical application. Aniruddha's work explores cutting-edge AI solutions across various industries. Through his writing, Aniruddha aims to inspire and educate, contributing to the dynamic and rapidly expanding field of artificial intelligence.
The Chartered Data Scientist
Designation
Achieve the highest distinction in the data science profession.