
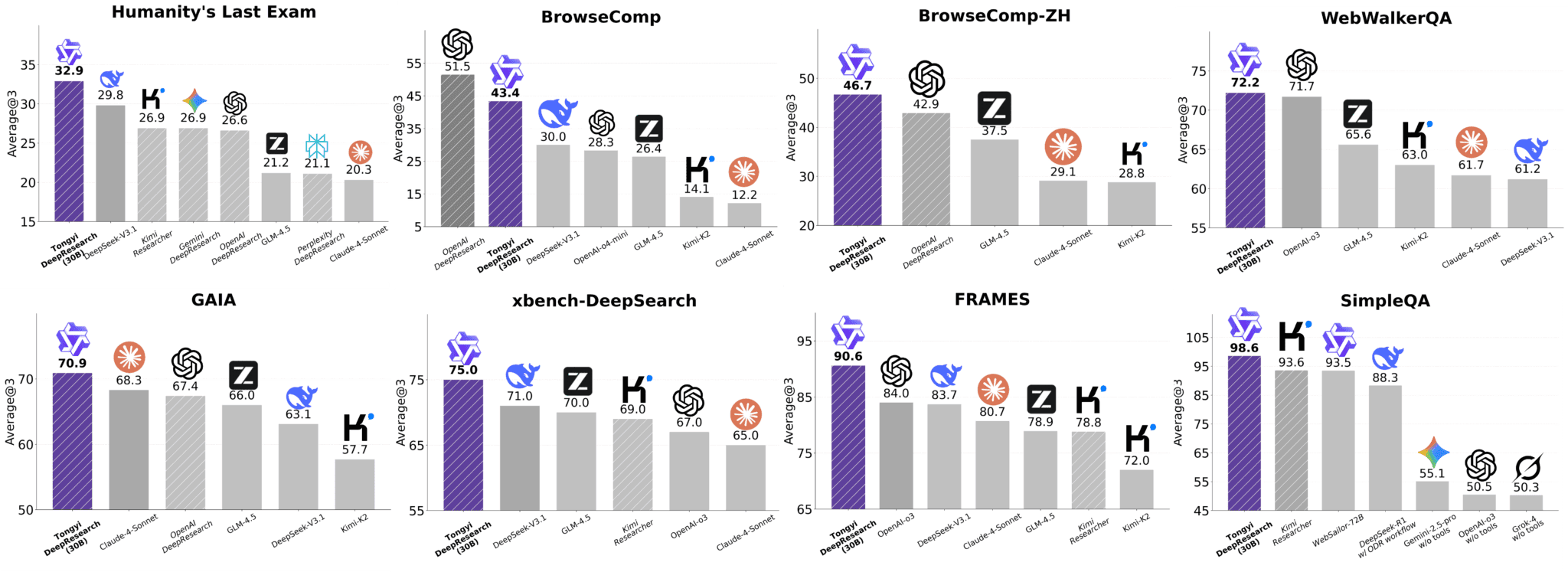
What if an open-source AI agent could rival proprietary giants like OpenAI in complex web-based research? Enter Tongyi DeepResearch, the first fully open-source Web Agent to match OpenAI’s DeepResearch across major benchmarks. Designed for long-horizon, multi-step reasoning over dynamic web environments, it scores 32.9 on Humanity’s Last Exam and 75 on xbench-DeepSearch. Beyond raw performance, its novel synthetic data pipeline and end-to-end training framework redefine how agentic AI is built and democratized. This article explores its architecture, features, use cases, and technical pipeline helping you understand how to master this new era of agentic AI.
Tongyi DeepResearch is not just another LLM, it’s a fully autonomous web agent trained to navigate, reason, and synthesize information from the open web. Unlike chatbots, it doesn’t just respond it plans, searches, validates, and reports. Built on a 30B-scale MoE architecture, it supports two inference modes: native ReAct for lightweight tasks and “Heavy Mode” for PhD-level research. Its training leverages 100% synthetic data, enabling scalable, human-free development while outperforming both open and closed competitors. It proves that open-source models, when trained with the right methodology, can compete with and even surpass proprietary systems in agentic reasoning.
The agent’s architecture follows a three-stage training pipeline: Agentic Continual Pre-training (CPT) → Supervised Fine-Tuning (SFT) → Reinforcement Learning (RL).
CPT leverages AgentFounder, a powerful synthetic data engine that transforms raw documents, knowledge graphs, and historical tool interaction logs into structured, entity-anchored QA pairs and multi-step action trajectories. This stage pre-trains the model to understand the “language of tools” how to decompose goals, invoke functions, and interpret outputs all within a simulated open-world environment. By anchoring knowledge to real-world entities and relationships, CPT ensures the model builds a coherent, navigable memory for downstream reasoning tasks.
SFT jumpstarts the agent’s capabilities using rejection-sampled trajectories derived from two frameworks: classic ReAct and the novel IterResearch. ReAct instills disciplined, turn-based reasoning (Thought → Action → Observation), while IterResearch dynamically trims and reconstructs context at each step to prevent cognitive overload during long-horizon tasks. This dual approach ensures the model not only follows structured formats but also learns to plan, reflect, and adapt its workspace mimicking how human researchers iteratively refine their focus.
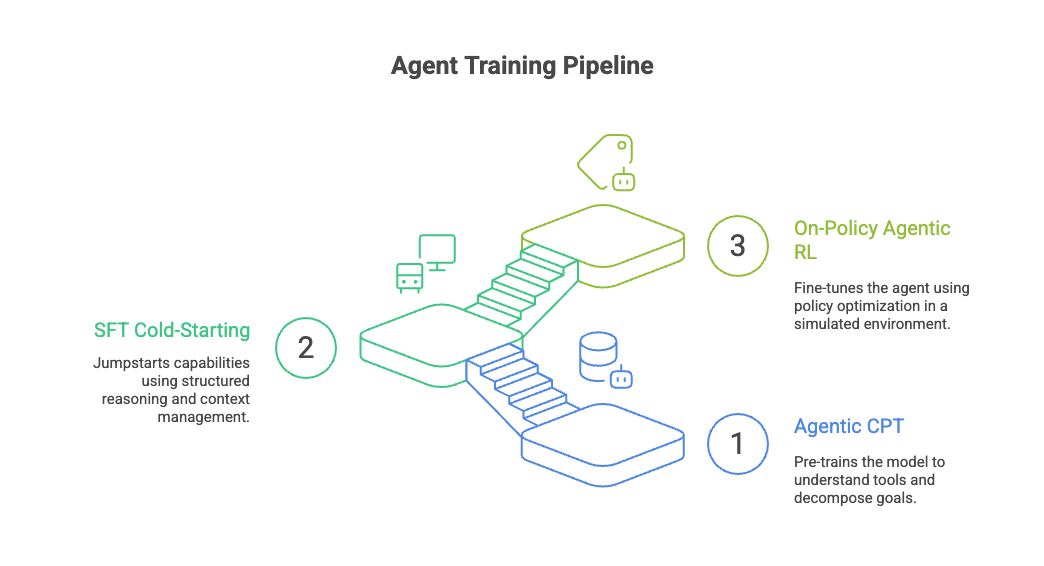
Tongyi’s three-stage training pipeline
The RL stage fine-tunes the agent using a custom Group Relative Policy Optimization (GRPO) algorithm, featuring token-level policy gradients and leave-one-out advantage estimation to reduce training variance. Negative samples are conservatively filtered excluding incomplete or truncated rollouts to avoid format collapse and ensure stable convergence. Training runs inside a simulated Wikipedia sandbox with cached tools, enabling fast, deterministic, and cost-efficient iteration while preserving real-world complexity.
The agent supports two rollout modes:
ReAct Mode operates as a pure, unmodified Thought → Action → Observation loop, requiring zero prompt engineering making it the cleanest test of the model’s intrinsic reasoning ability. With a 128K context window, it can sustain dozens of interaction rounds, scaling naturally with task complexity. Its minimalism reflects “The Bitter Lesson”: that general, scalable methods outperform brittle, hand-crafted heuristics and it serves as the baseline for measuring training efficacy.
Heavy Mode activates the IterResearch + Research-Synthesis framework, where multiple agents explore different research paths in parallel, each maintaining a streamlined, evolving workspace. A final Synthesis Agent then integrates their distilled reports into a comprehensive, citation-backed answer mimicking collaborative expert panels. This mode unlocks the agent’s full potential for PhD-level, multi-source, long-horizon research, where precision, depth, and structure matter more than speed.
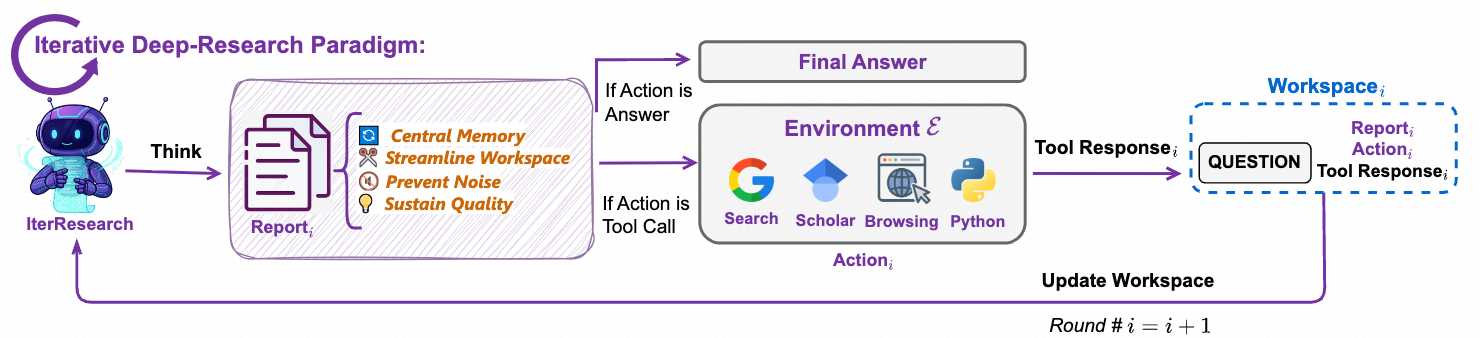
Synthetic Data Flywheel
Tongyi DeepResearch trains entirely on synthetic data and no human labeling. The WebShaper pipeline formalizes QA difficulty using set theory and “atomic operations” (e.g., merging similar entities) to controllably increase complexity. The PhD-QA Engine iteratively upgrades seed questions using web search, academic retrieval, and code execution creating self-improving, superhuman datasets.
IterResearch Paradigm
Traditional agents drown in ever-growing context. IterResearch solves this by rebuilding a minimal workspace each turn, integrating only essential findings into a central report. This maintains focus and reasoning quality over 100+ steps.
RL That Actually Works
Most RL for agents fails due to noisy rewards or unstable environments. Tongyi’s solution? A deterministic sandbox, conservative negative sampling (excluding truncated trajectories), and asynchronous on-policy training via rLLM. Reward curves rise steadily; entropy stays high — proving robust exploration without collapse.
Gaode Mate (Navigation Copilot):
Ask: “Plan a 3-day pet-friendly road trip through Zhejiang with scenic stops.”
Result: Xiao Gao autonomously searches, filters, sequences, and outputs a detailed itinerary — complete with driving times, pet policies, and photo spots.
Tongyi FaRui (Legal Research Agent):
Task: “Find precedents for remote work contract disputes in Shanghai courts post-2020.”
Action: Retrieves statutes, cross-references cases, synthesizes rulings — and cites every source. Functions like a junior attorney, minus the billable hours.
These aren’t demos, they’re deployed products inside Alibaba, proving Tongyi DeepResearch’s enterprise readiness.
Tongyi DeepResearch marks a turning point in open-source AI agents. By combining synthetic data, structured fine-tuning, and robust RL, it delivers performance previously seen only in proprietary systems. While challenges remain such as scaling beyond 30B parameters and extending context windows Tongyi demonstrates that open-source agentic AI can rival the best in the world. For developers, researchers, and enthusiasts, this project offers not only tools but also a blueprint for building the next generation of autonomous AI researchers.




![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

