The VDR-2B-Multi-V1 model represents a new milestone in visual document retrieval, enabling efficient and multilingual search without the need for OCR, data extraction pipelines, or chunking. Designed to encode visually rich document pages into dense single-vector embeddings, this model is a game-changer for multilingual and domain-specific applications.
Trained on a cutting-edge dataset of multilingual query-image pairs, VDR-2B-Multi-V1 significantly enhances cross-lingual retrieval, inference speed, and resource efficiency. This blog explores its architecture, training methodologies, evaluation results, and the future possibilities it unlocks.
The vdr-2b-multi-v1 model is a multilingual embedding framework optimized for visual document retrieval across diverse languages and domains. Built on MrLight/dse-qwen2-2b-mrl-v1, it incorporates advancements in Matryoshka Representation Learning (MRL), low VRAM usage, and faster inference times. The model supports five languages—Italian, Spanish, English, French, and German—and enables cross-lingual document retrieval, such as querying German documents with Italian text.
vdr-2b-multi-v1 excels in cross-lingual search scenarios, outperforming previous models in multilingual benchmarks.
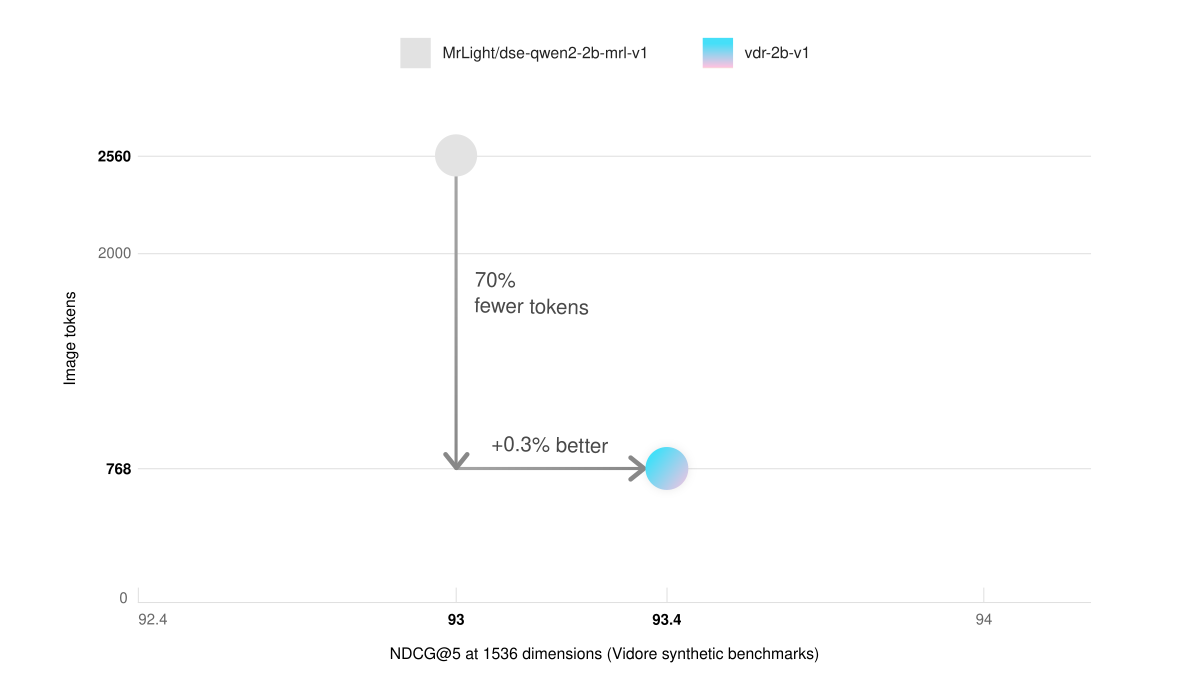
With only 768 image tokens compared to the base model’s 2560, It delivers 3x faster inference and significantly reduced VRAM usage.
MRL enables dimensional reduction, maintaining 98% of embedding quality with 3x smaller vectors, improving retrieval speed and storage efficiency.
Built on 500k samples, the dataset includes multilingual query-image pairs, curated for high diversity and quality.
Inference Comparison
The training dataset comprises 500k query-image pairs across five languages, curated using public PDFs and advanced layout analysis models.
| Language | Filtered Queries | Unfiltered Queries |
| English | 53,512 | 94,225 |
| Spanish | 58,738 | 102,685 |
| Italian | 54,942 | 98,747 |
| German | 58,217 | 100,713 |
| French | 55,270 | 99,797 |
Queries were generated using Gemini-1.5-pro and Qwen2-VL-72B, which were tasked with producing both general and specific queries for improved information retrieval.
A meticulous cleaning and filtering process ensured high-quality queries. Hard negatives were mined using voyage-3, refining the dataset to improve model robustness.
Step 1: Install Required Libraries
!pip install -U llama-index-embeddings-huggingfaceStep 2: Load Model
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
model = HuggingFaceEmbedding(
model_name="llamaindex/vdr-2b-multi-v1",
device="cuda", # "mps" for mac, "cuda" for nvidia GPUs
trust_remote_code=True,
)Step 3: Generate Embeddings
image_embedding = model.get_image_embedding("/content/what7.jpg")
query_embedding = model.get_query_embedding("cos'è la garanzia di credito per le MSMEs")Step 4: Print Embeddings
print(image_embedding)
print(query_embedding)Output:

Huggingface Demo Output:
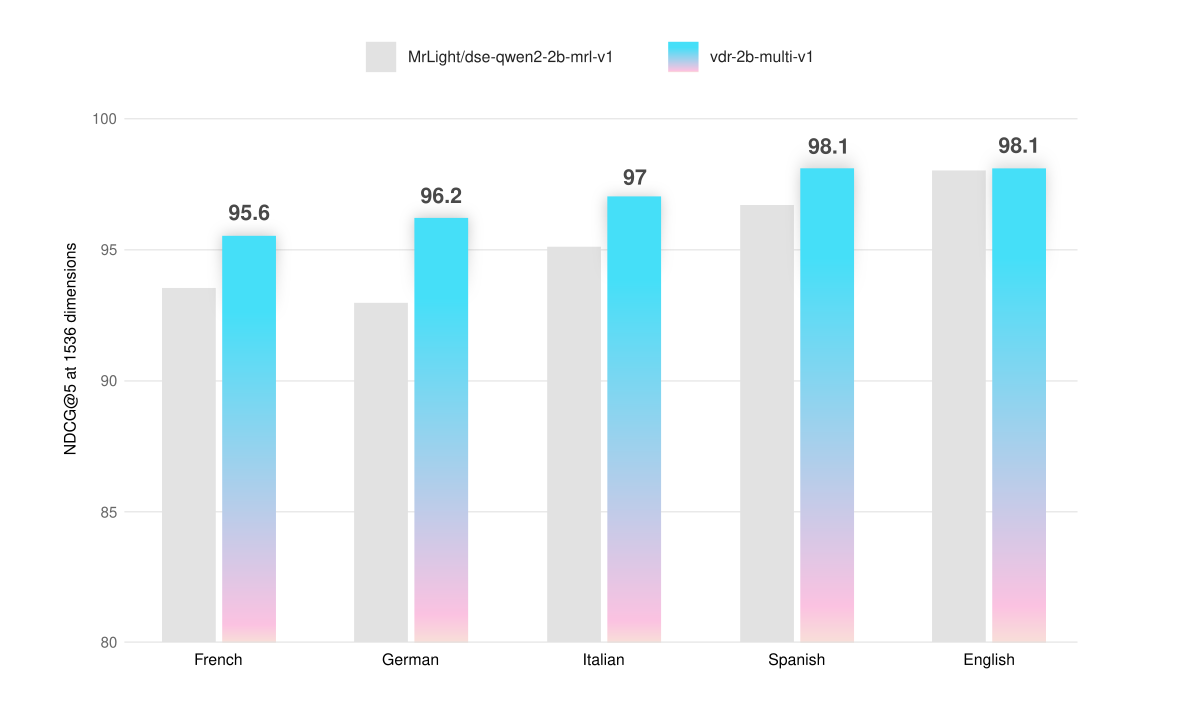
It demonstrated significant performance gains across all tested languages and page types:
| Metric | Base Model (dse-qwen2-2b-mrl-v1) | vdr-2b-multi-v1 | Improvement |
| French (Visual) | 90.8 | 93.3 | +2.2% |
| German (Visual) | 90.0 | 95.7 | +6.3% |
| Italian (Visual) | 94.0 | 96.3 | +2.0% |
| Spanish (Visual) | 94.7 | 96.9 | +2.2% |
| English (Visual) | 98.5 | 99.1 | +0.6% |
The English-only version (vdr-2b-v1) matches the base model’s performance on the ViDoRe benchmark using only 30% of the image tokens.
| Model Variant | Inference Speed | VRAM Usage |
| Base Model (2560 Tokens) | Baseline | High |
| vdr-2b-multi-v1 (768 Tokens) | 3x Faster | Low |
Multilingual Capabilities Comparison
Search for multilingual documents using queries in another language, enabling seamless cross-lingual access to resources such as legal documents, instruction manuals, and scientific papers.
From healthcare to government archives, the model’s adaptability ensures effective retrieval in specialized domains.
The model aids in generating high-quality synthetic datasets, accelerating research in domains where data scarcity is a concern.
The vdr-2b-multi-v1 model redefines the landscape of visual document retrieval, combining multilingual capability, efficiency, and scalability. By leveraging cutting-edge training techniques and datasets, it offers unmatched performance and resource efficiency.