
Cohere for AI announced Aya 23, a family of large language models focusing on multilingual capabilities based on 23 languages. Aya 23 model was released in 2 variants by Cohere – Aya 23 8B and 35B. Aya 23 model family is primarily based on Cohere’s Command models, which are pre-trained using a data mixture comprising 23 languages, and Aya multilingual instruction style collection.
Aya 23 is a SOTA expansion based on the Aya 101 model. Aya 23’s variants – 8B and 35B parameter sizes, outperform previous multilingual language models such as Aya 101, Gemma, Mistral and Mixtral based on an extensive range of discriminative and generative tasks. Cohere4AI released the open weights for both 8B and 35B Aya 23 models on Hugging Face for experimentation, research and audit (https://huggingface.co/spaces/CohereForAI/aya-23?ref=cohere-ai.ghost.io).
The Aya 23 models are trained on data from 23 languages using a standard decoder-only transformer architecture having key features such as SwiGLU activation function, Rotary positional embeddings (ROPE) for better context, 256k vocabulary size BPE(Byte-Pair Encoding) tokenizer trained on a balanced subset of pre-training data. These pre-trained models are then instruction fine-tuned on a mixture of multilingual data.
The Aya initiative consists of 3 Models – Aya 23-8B, Aya 23-35B and Aya 101. The Aya 101 launched in Feb’2024 has a core strength of handling 101 languages. Aya 101 model is a finetuned 13B mT5 model using an instruction mixture based on data sourced from a variety of sources such as:
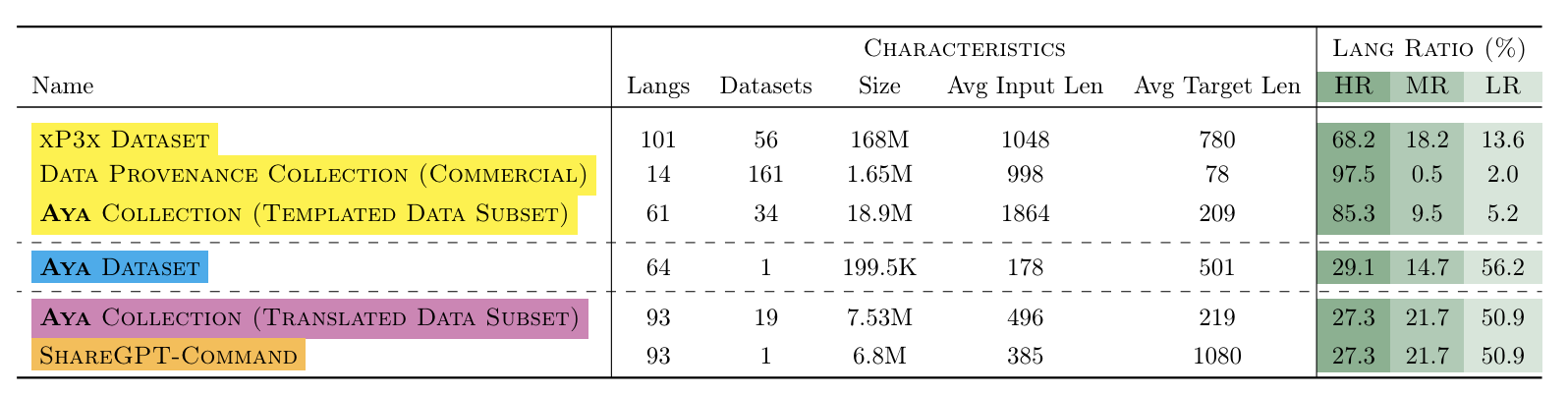
Training Data Sources used for instruction finetuning Aya (yellow shows multilingual templates, blue shows human annotations, orange is synthetic data and pink shows machine translation-based data.
The Aya 23 is an experiment in shifting from breadth to depth. While Aya 101 showcased breadth due to its 13-billion parameter model, it had shortcomings – As more languages are added to a multilingual LLM, the performance of individual languages can often decrease. This is known as the Curse of Multilinguality. Aya 23 on the other hand, balances breadth and depth, exploring the impact of allocating more resources to fewer languages to alleviate the issue and lead to better performance over the original Aya 101 and other widely used models such as Gemma, Mistral and Mixtral.
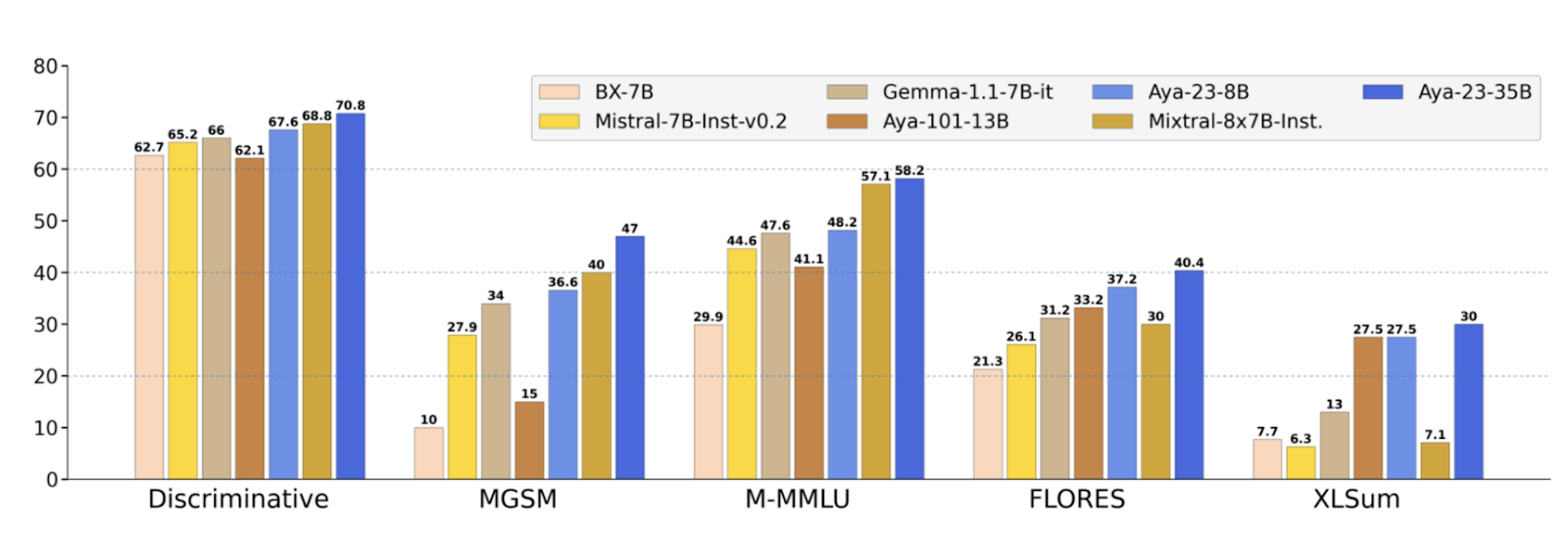
Aya 23-35B outperforms all models in discriminative tasks with an average of 70.8%, In Multilingual MMLU (Massive Multitask Language Understanding) Aya 23-35B achieved an average of 48.2% accuracy across all languages and the highest score in 11 out 14 languages for its class. When it comes to MGSM (Multilingual Mathematical Reasoning), Aya 23 models outperform all-in-class baselines, which indicates strong mathematical reasoning ability across languages. Aya 23-35B achieved a score of 53.7 compared to the Mixtral-8x7B-Instruct-v0.1 model.
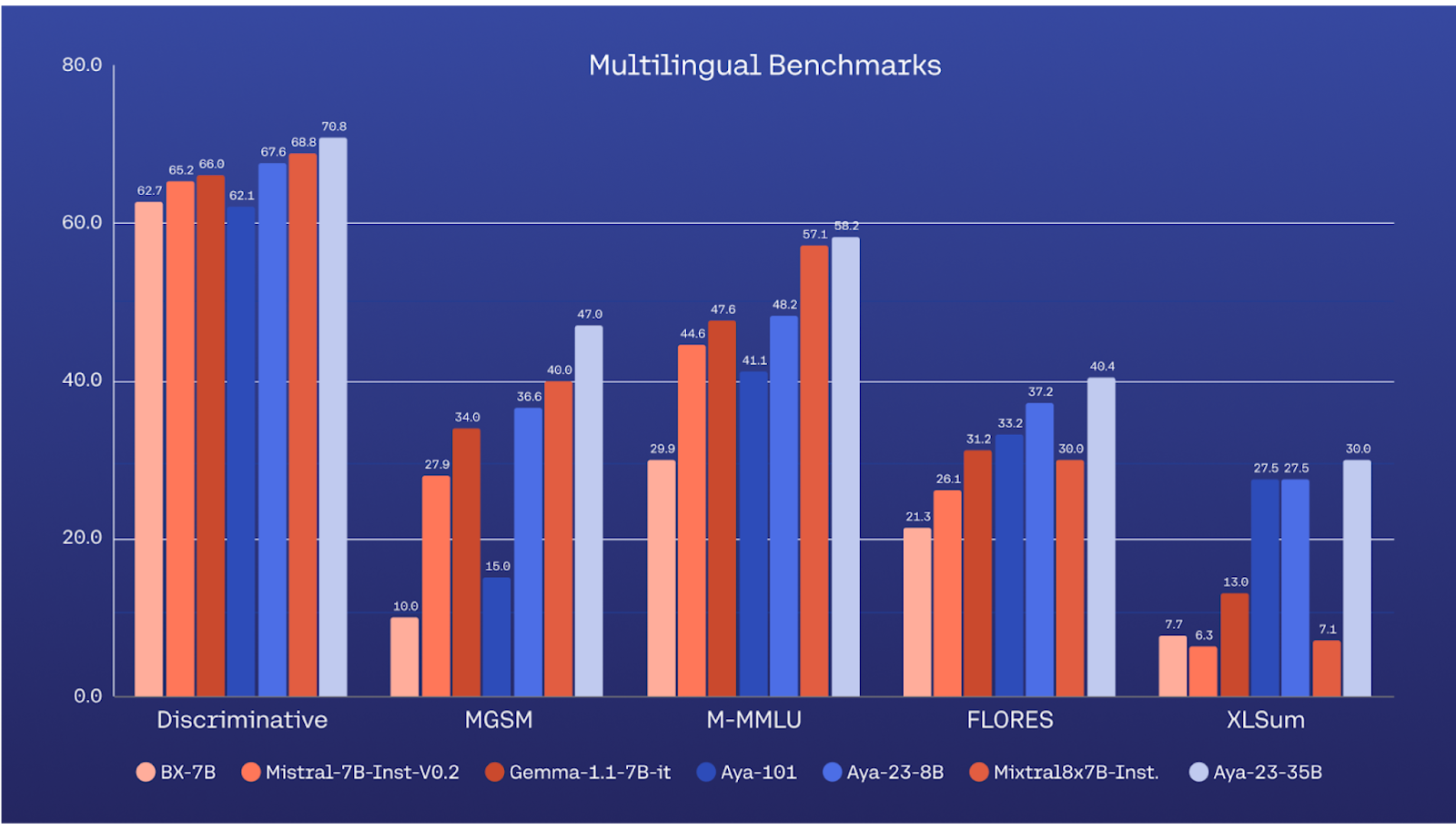
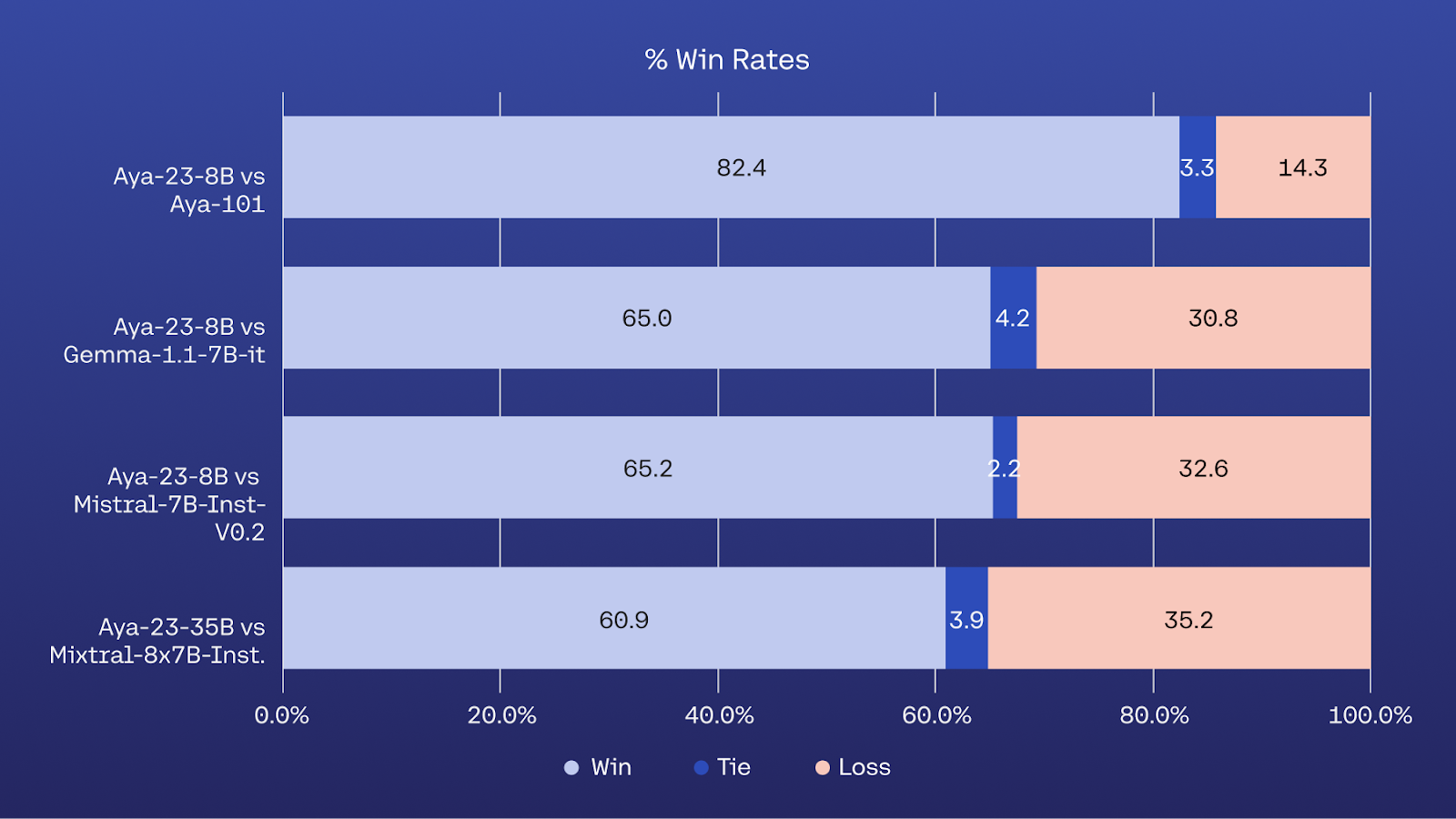
Aya 23 greatly improves the performance for a subset of 23 languages, this gives rise to the multilingual technologies empowering the multilingual world. It’s a significant step towards making AI technology accessible to a wider audience based on a wide array of languages. The extensive evaluation demonstrated the high performance of these models and by releasing the model weights, Cohere has made sure this work can be continued further.








![[Upcoming Webinar] MCP and A2A – The AI Protocols for Next-Gen Agent Ecosystems](https://adasci.org/wp-content/uploads/2025/04/adasci-featured-300x300.png)

