
Azure AI services consist of several embeddings that offer different ways to understand and respond to user queries in a contextually relevant and efficient manner. These embeddings allow us to query our knowledge bases for relevant documents using semantic search. The embedding-ada-002, for instance, converts textual data into vector counterparts, which can be used for implementing similarity metrics such as cosine similarity. In this article, we will understand and implement the different embedding models offered in Azure AI Hub.
Table of Contents
Embeddings are high-dimensional vectors where each dimension represents a semantic feature. Words or phrases that are semantically similar in terms of meaning or logic are grouped, making it easy for AI algorithms to perform tasks such as semantic search. The distance between two vectors measures their relevance; a smaller distance corresponds to a higher degree of similarity or relevance.
Embeddings are generated based on the model training of a large textual corpus or image data. The training proceeds by altering vector representations to minimise the loss function, which measures how well the model can classify text or make a prediction. Once the training is finished, the generated embeddings can be used to transform the data into numerical vectors, which can be used in generative AI models such as GPT 3.5-Turbo for different tasks or for computing similarities between texts. Embedding-ada-002 is one of the most prominent text embedding algorithms developed by OpenAI and is available in Azure AI Hub’s embedding for generative AI application development. This embedding can be utilised for different tasks such as similarity searching, textual searching and code searching.
Embeddings have the following advantages:
Different use cases of embeddings are listed below:
Azure AI Portal hosts a multitude of embeddings that users can use for their generative AI application development. These embeddings can be used for tasks based in text, images or multimodal data.
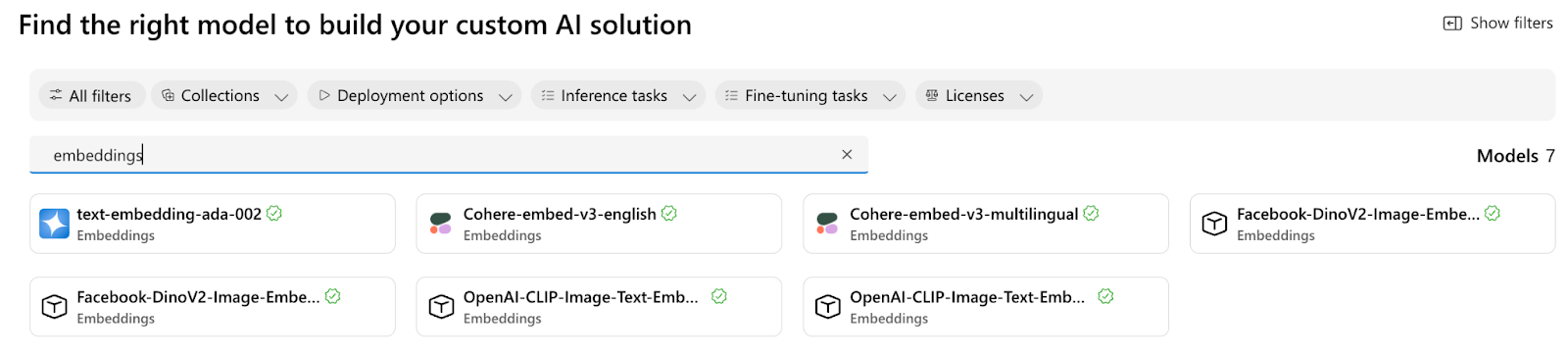
Azure AI Hub Embeddings (Model Catalog)
Similarity embeddings aim to capture the overall semantic similarity between different chunks of text. Users can use these types of embeddings to identify and compare different texts in meaning. Applications of these embeddings can include text summarisation, finding similar text chunks or documents, plagiarism detection, etc.
The idea behind text search embedding is to retrieve relevant text based on the user query. These embeddings are optimised for fast search in large amounts of text data. They consider both the semantic meaning and keywords in the user query. These embeddings are used in tasks such as information retrieval, search engine optimisation, QA systems, and recommendation engines.
Users can find relevant code snippets based on natural language queries using code search embeddings. These embeddings understand the code syntaxes and structure with the natural language used in user queries. Users can use it in code development applications and testing.
Let’s understand and deploy Azure OpenAI embedding-ada-002 and check its utility based on different data sources.
Step 1: Visit Azure AI Studio (https://ai.azure.com) and create a new project.
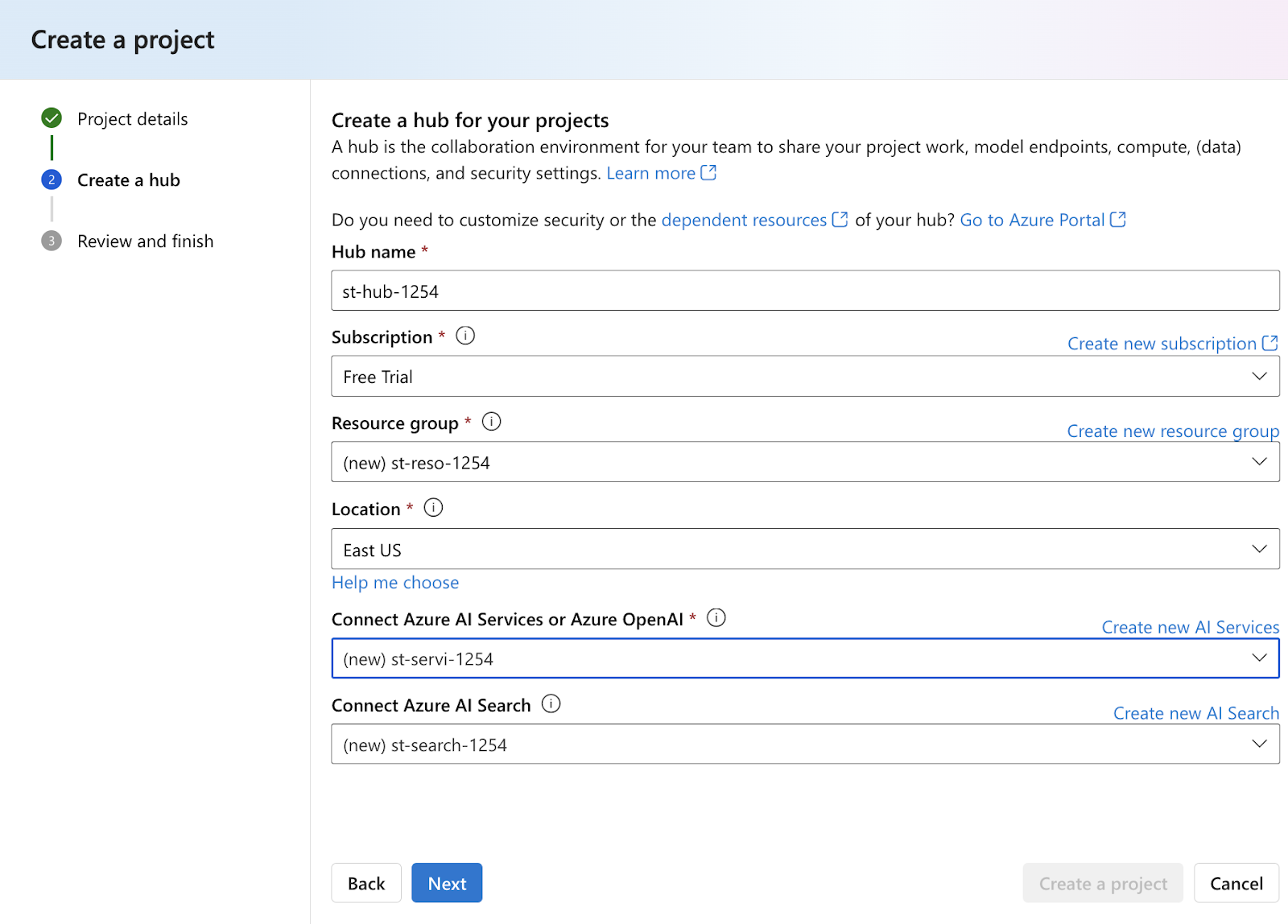
Step 2: The project requires Azure AI Hub for resource management and collaboration, so we will set up an Azure AI Hub for our project using the create project dialogue box. Make sure to create the related Azure services during Hub creation – AI Search, AI Services, Resource Group,
Step 3: Once the project and hub set-up are complete, visit the deployment section using the left panel to deploy the OpenAI embedding model. We will deploy the GPT 3.5-Turbo and embedding-ada-002 models for our chat application.
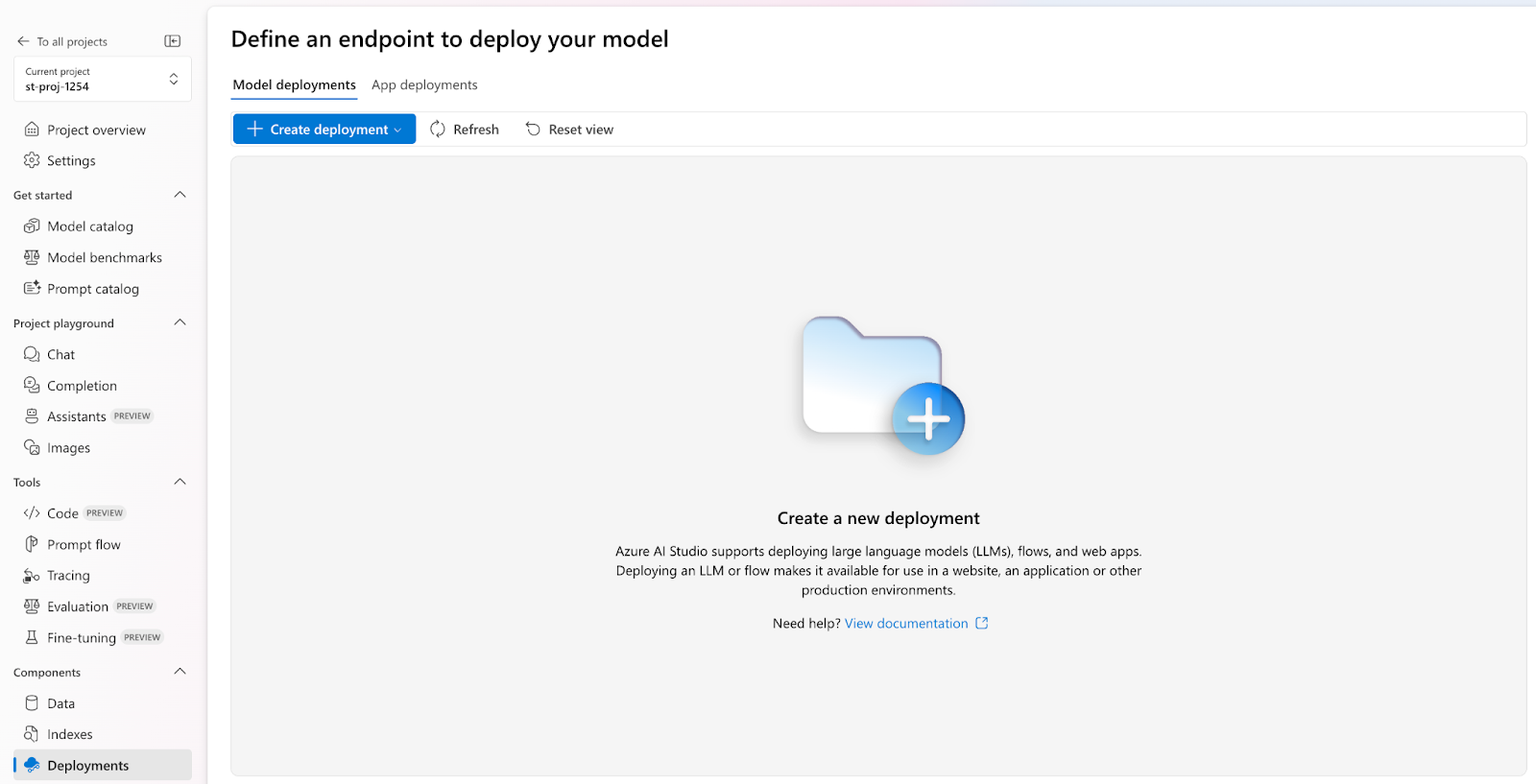
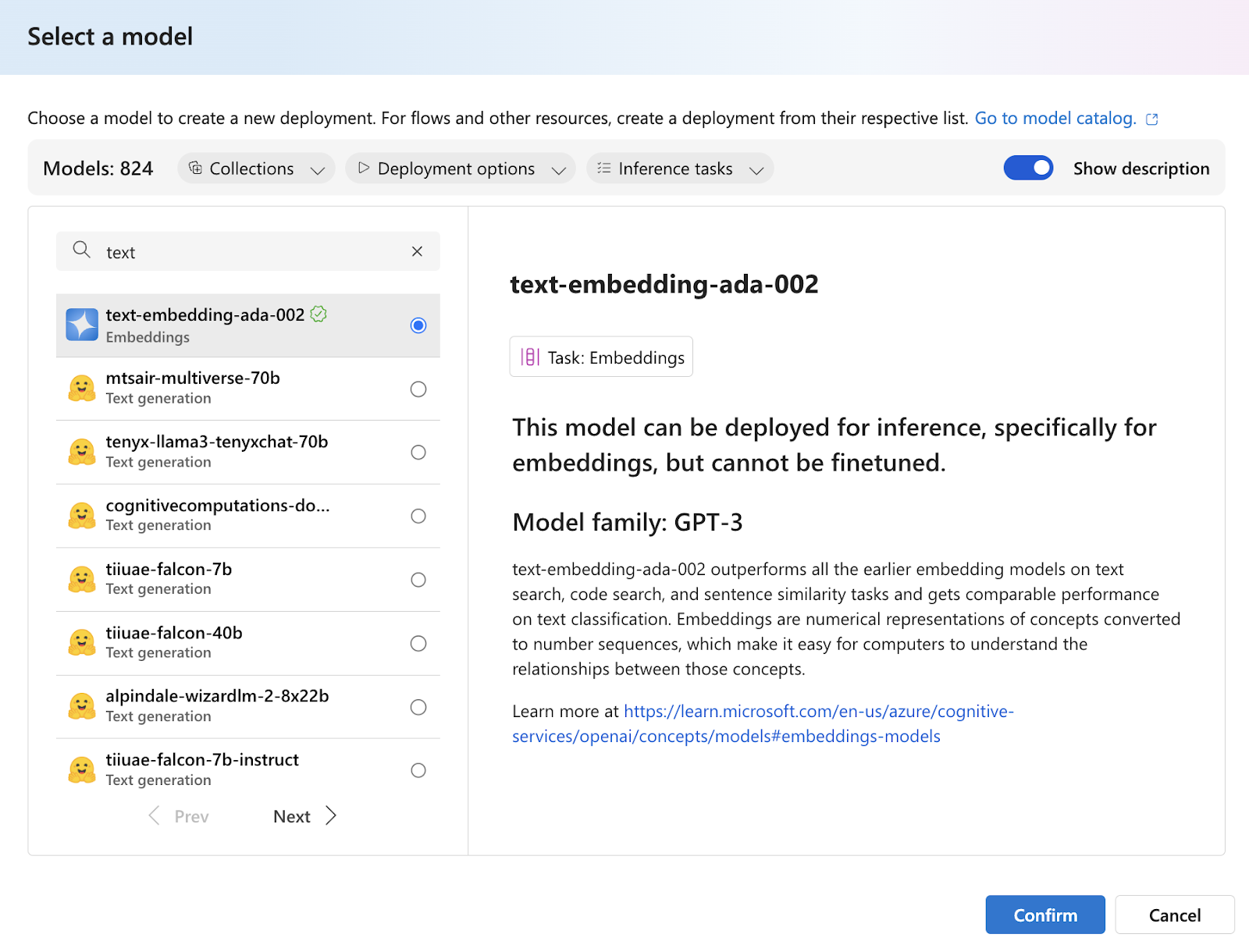
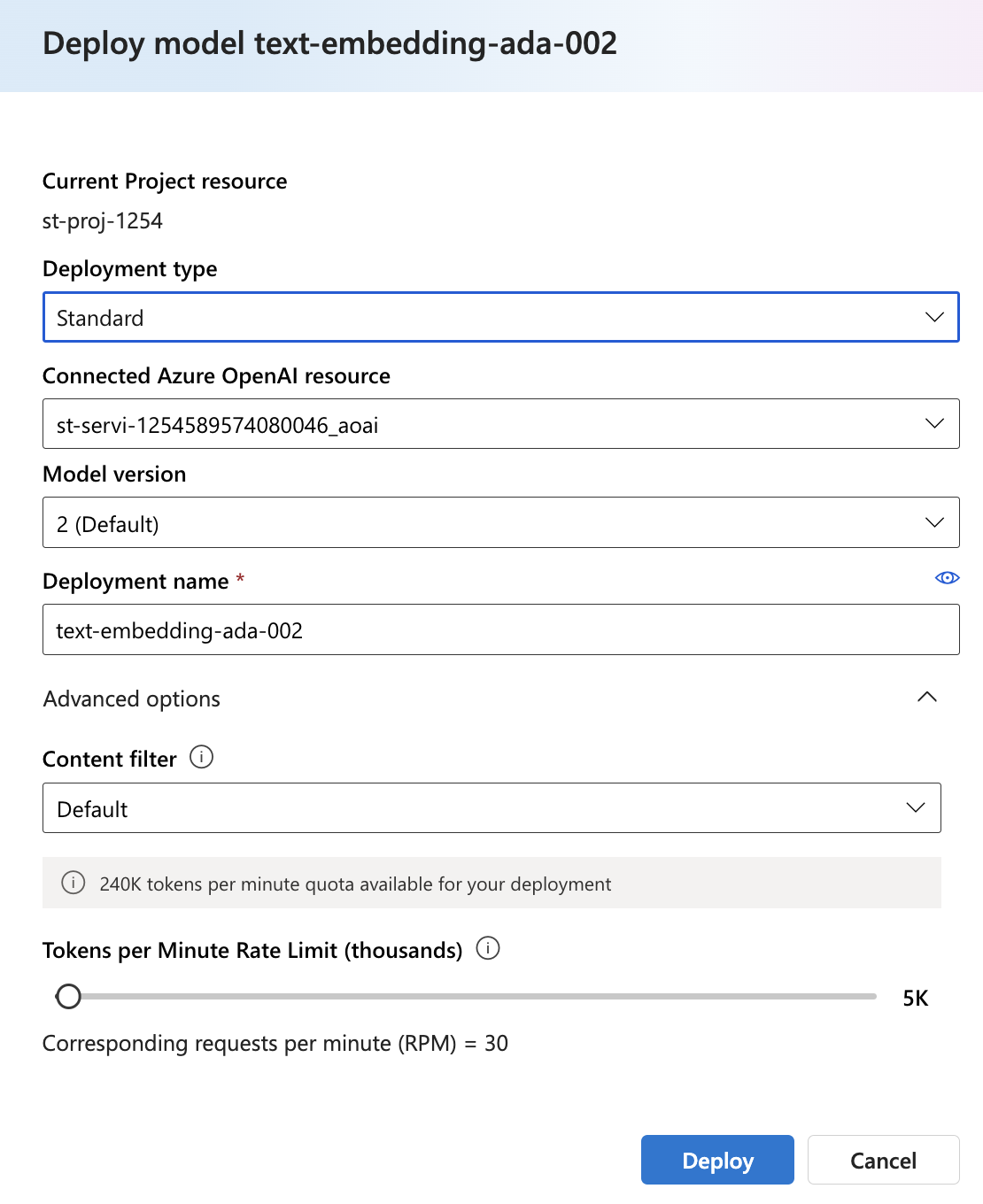
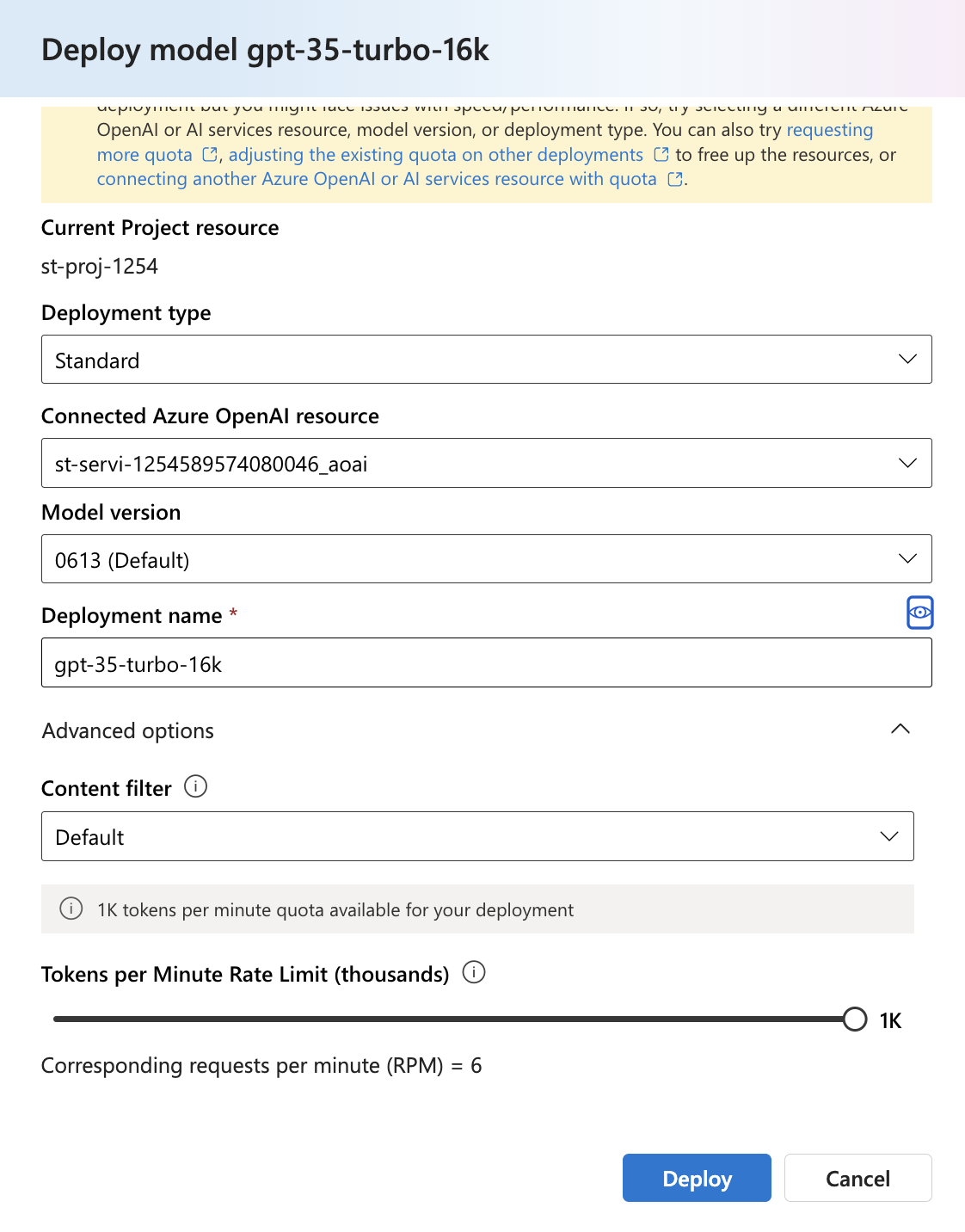
Check the deployment section to verify the model deployments.
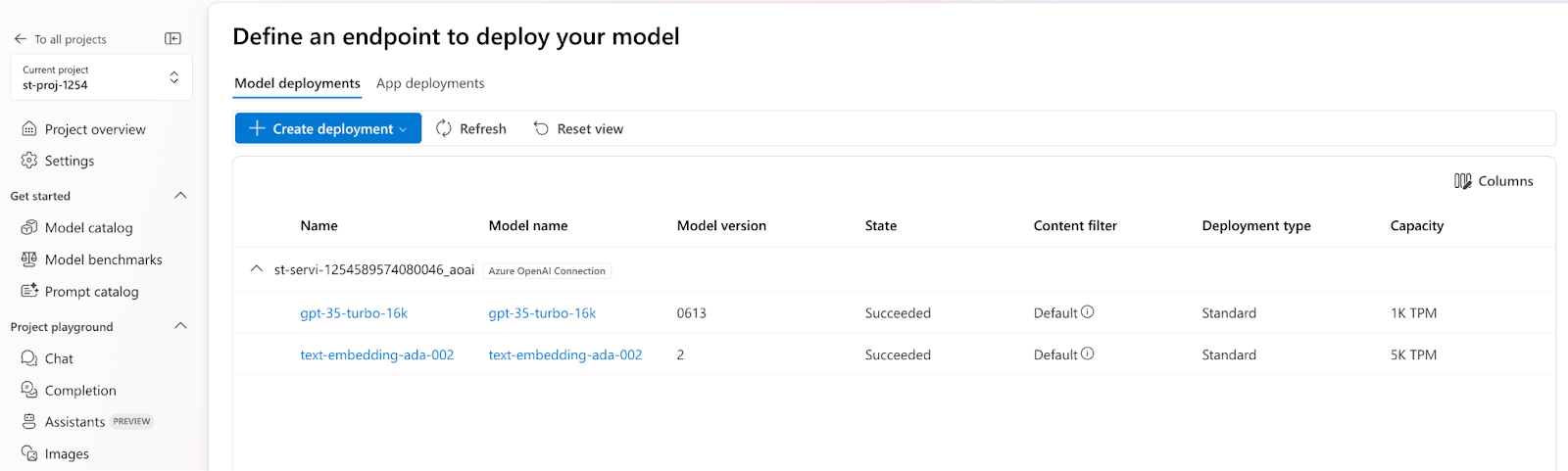
Set 4: Using the project’s playground chat option, we will add our data, index it, and use it for response generation. For a comparative analysis, I have used two text files based on Game of Thrones as inputs to our deployed embedding and chat model.
Input 1: A shorter version of the Game of Thrones script

Input 2: A Larger version of the Game of Thrones script

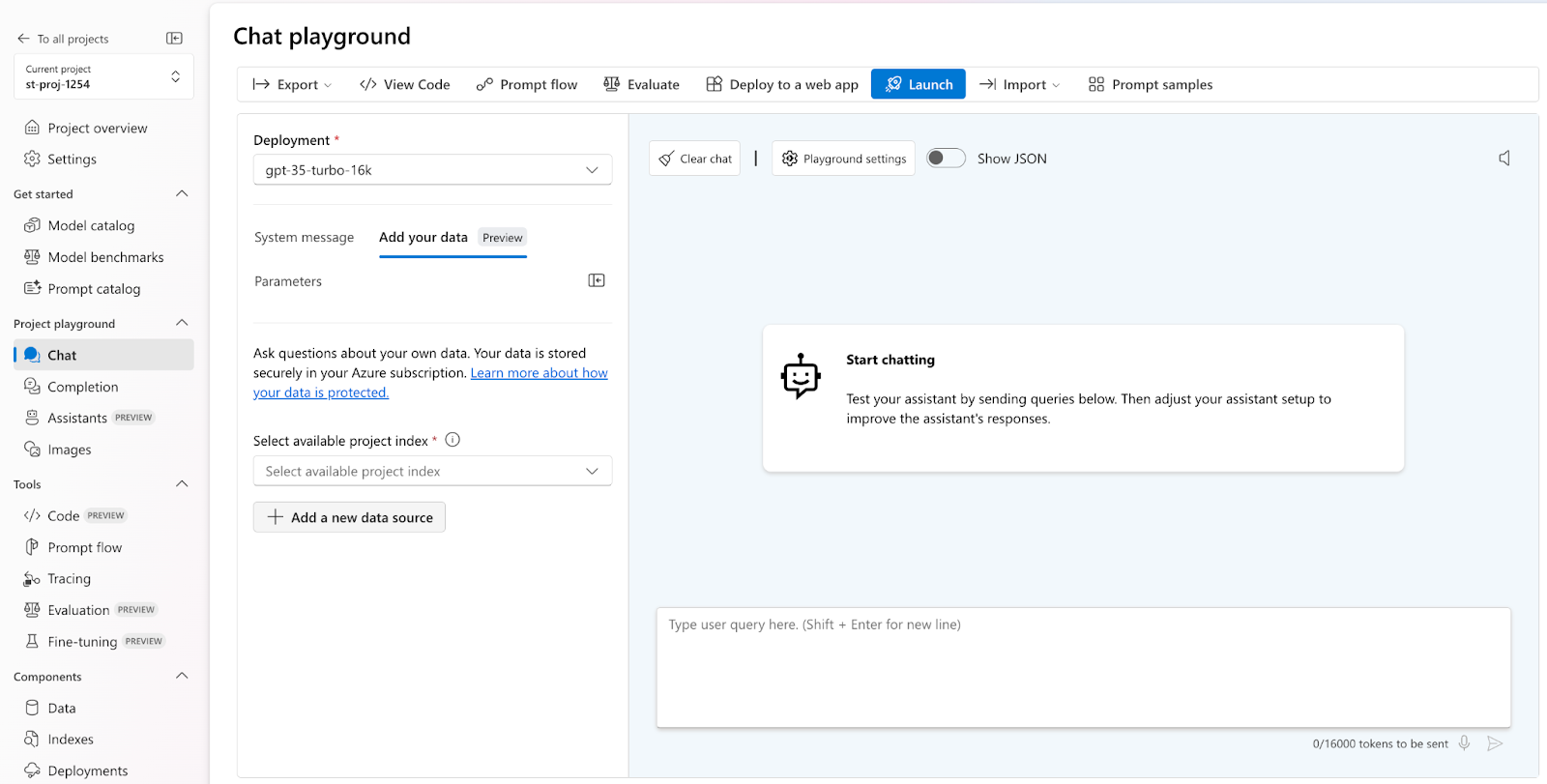
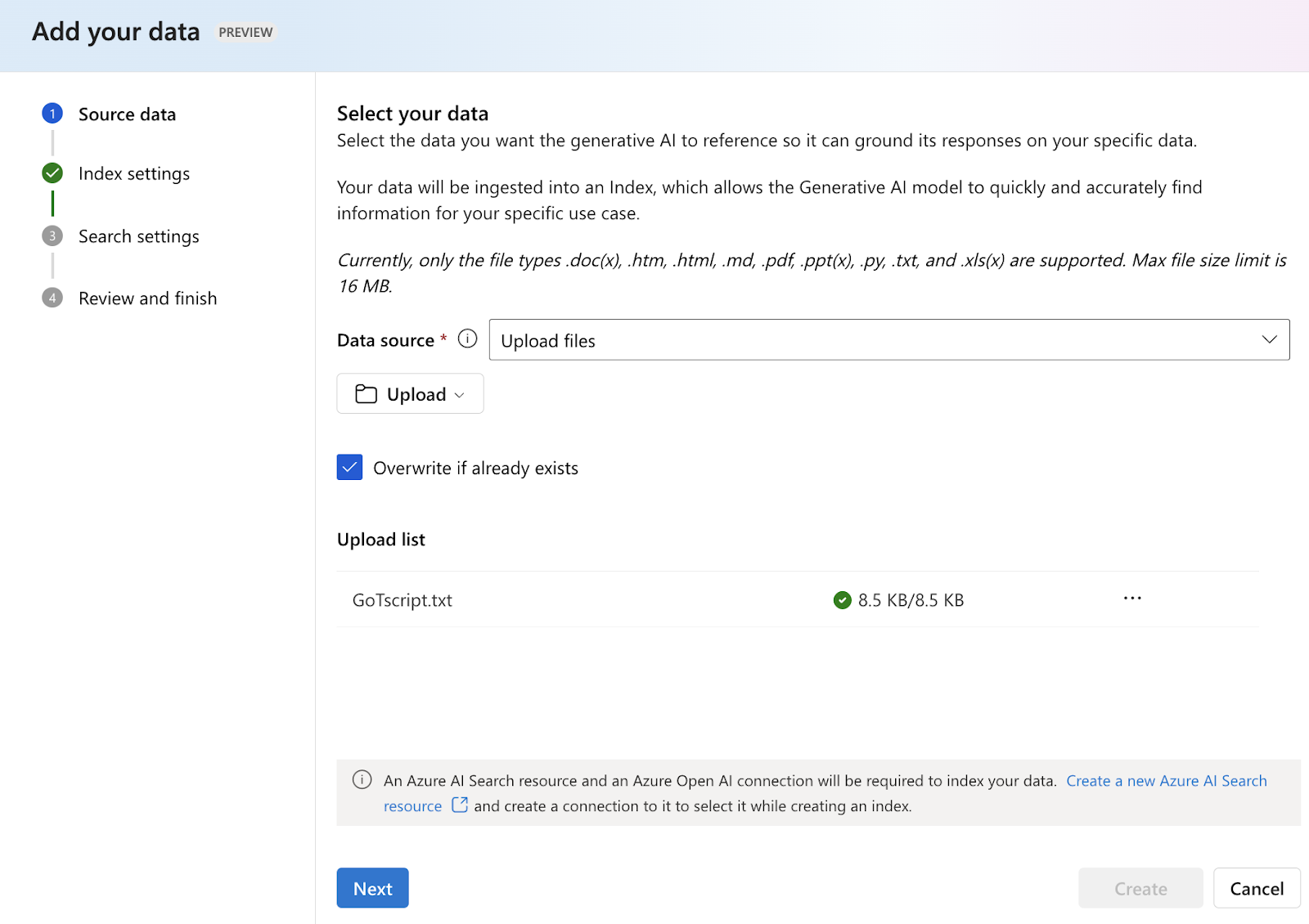
Add the data and index it for use with the models. Select the add a new data source option and upload your data file. We will upload inputs 1 and 2 sequentially and check their responses, requiring separate indexes.
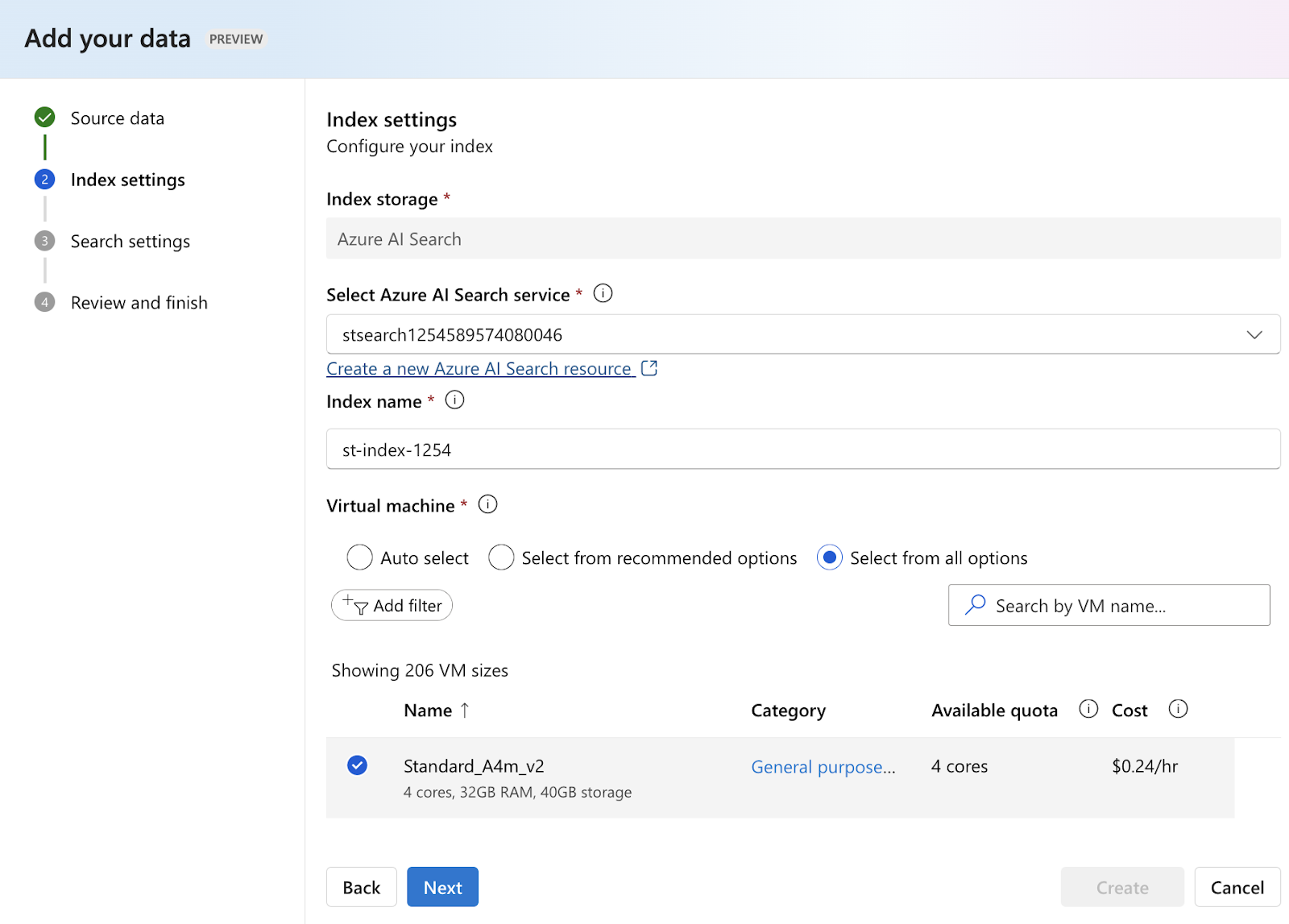
Step 5: Checking the responses generated based on inputs 1 and 2 show different outputs:
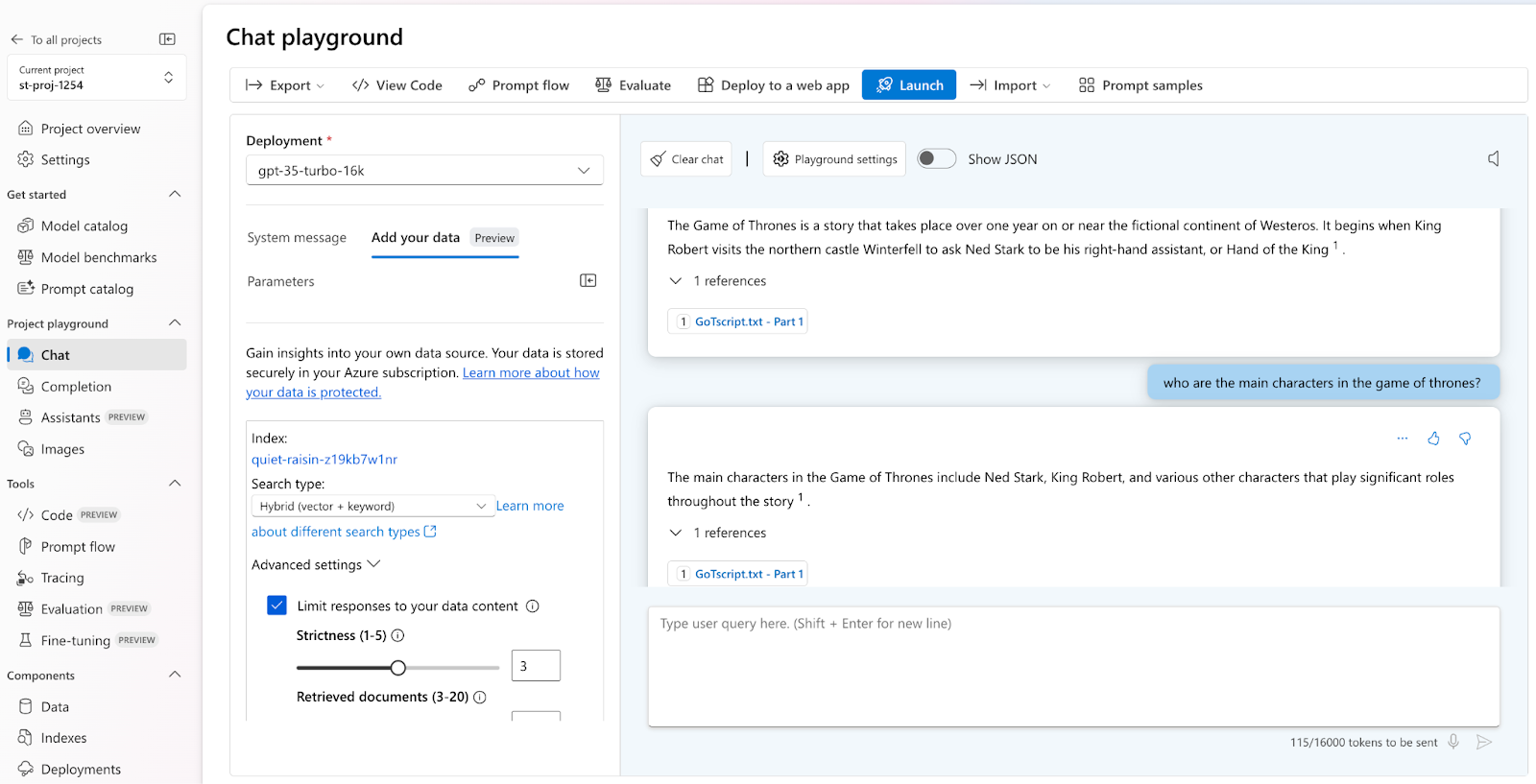
Output based on Input 1 (shorter version of Game of Thrones script)
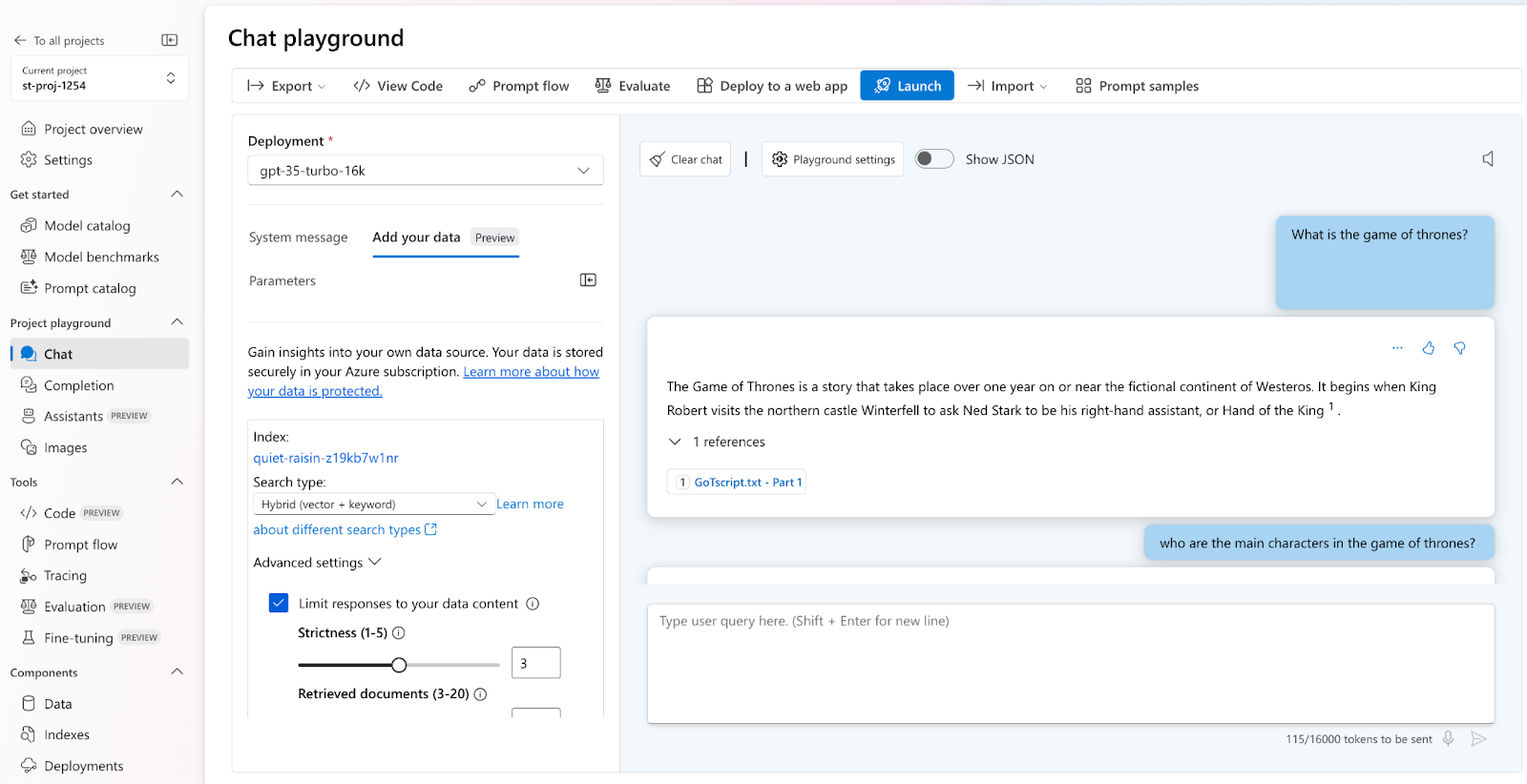
Output based on Input 2 (larger version of Game of Thrones script)
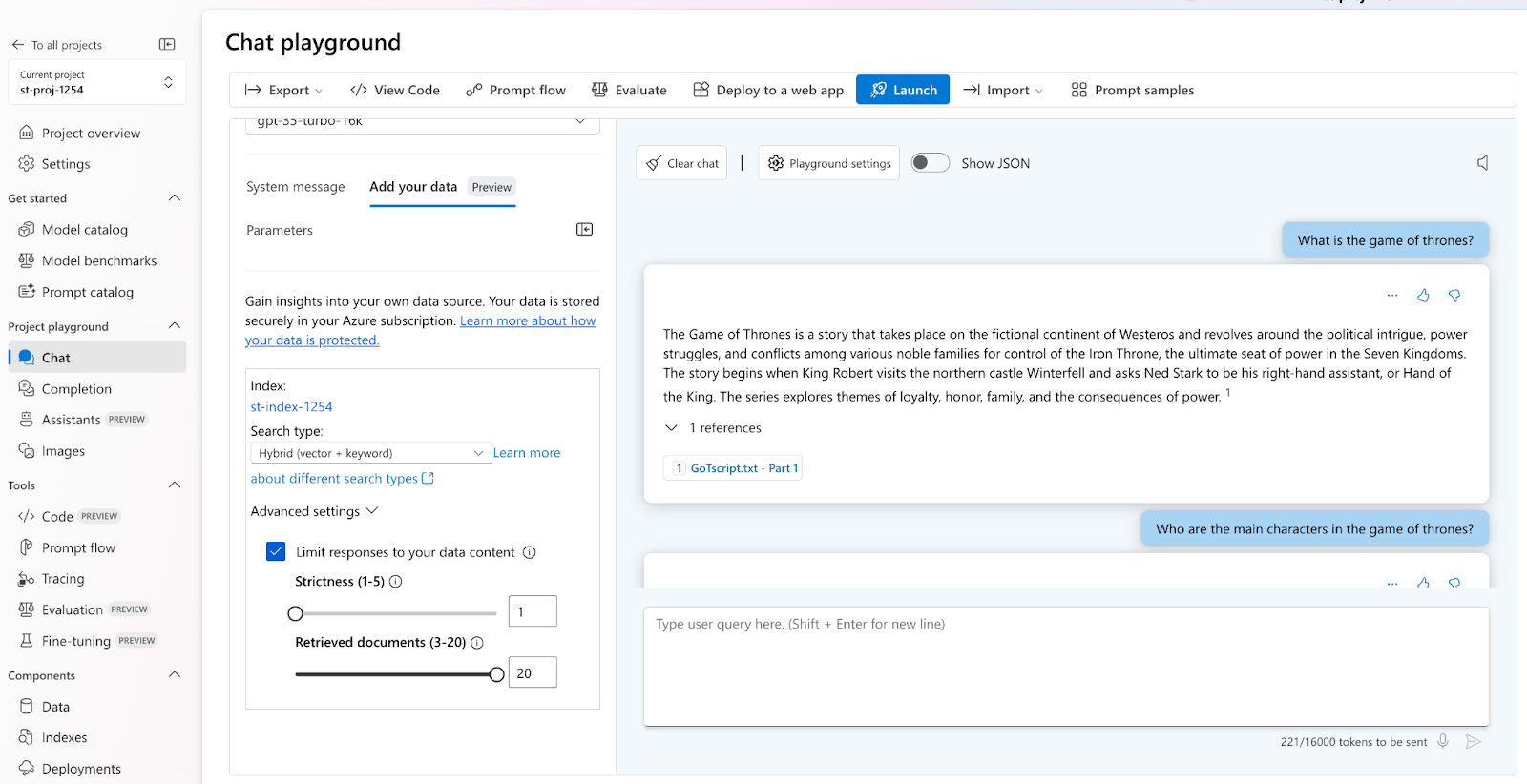
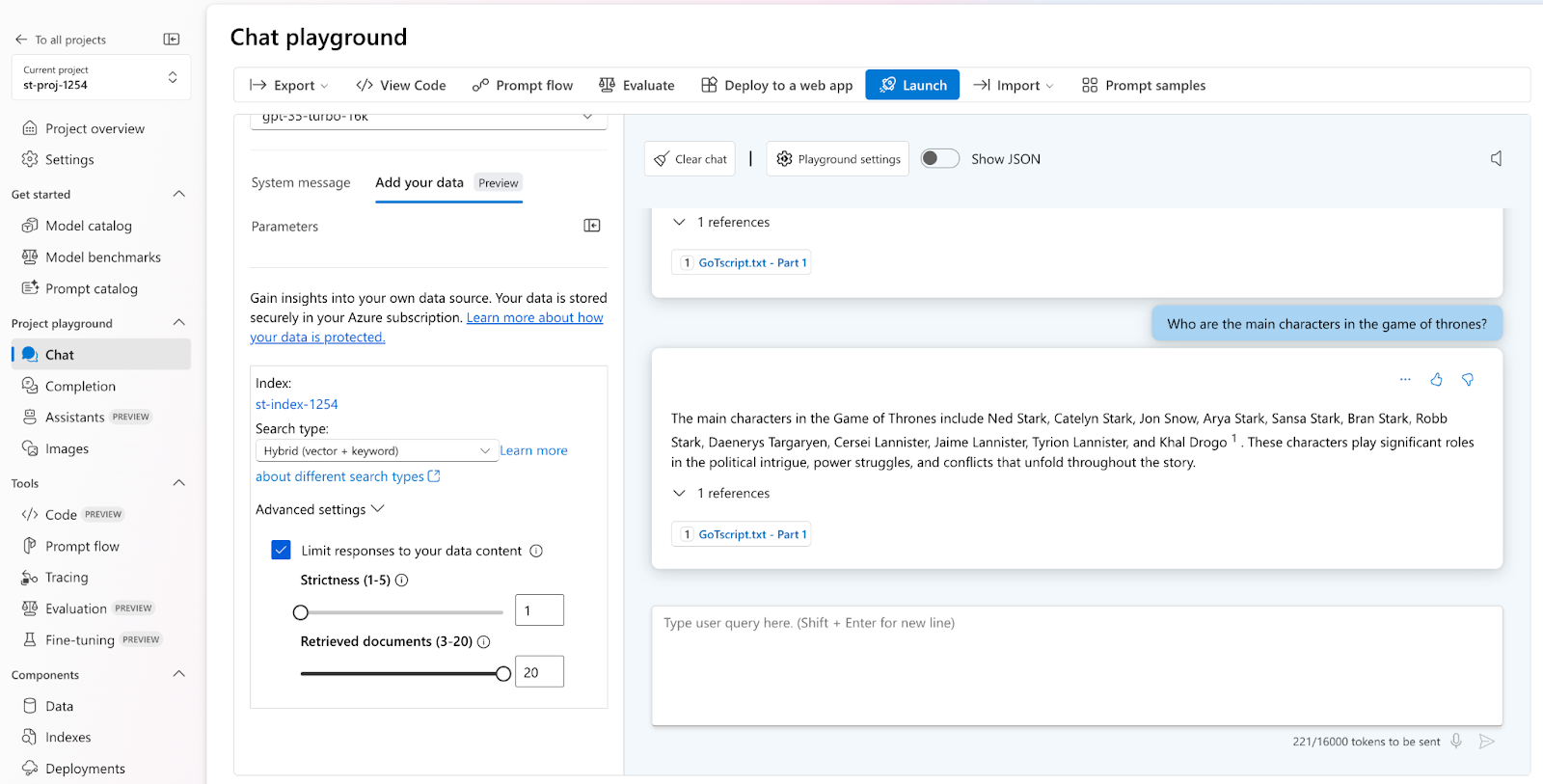
We can observe the change in the generated answer when we limit our embedding model for the data we provide. Due to the smaller amount of data provided as input, the response based on input 1 data is brief in context. in contrast, the response based on input 2 data is considerably more thorough and contextually relevant.
In conclusion, embeddings are very important for working with large amounts of data and understanding their context for effective and efficient generative AI application development. The integration of Azure AI services, resource manager, AI search, and Azure OpenAI within Azure AI Hub makes it very easy to deploy generative AI models and operate on them securely and collaboratively.







![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

