
LangExtract is a new open-source Python library introduced by Google. It’s a Gemini-powered information extraction library, designed to programmatically extract user-required information while ensuring the outputs are structured and grounded to the source content. The library offers a seamless way to extract structured information from unstructured textual data using LLMs with source grounding and interactive visualisation. This article explores LangExtract and showcases a hands-on implementation for using it effectively.
Recent developments in the field of large language models have proven them incredible at understanding context and generating human-like text, but reliably extracting precise, structured information from unstructured data remains a problematic task altogether. There are different issues that arise, such as hallucinations, imprecision, context window limitations when it comes to large documents, non-determinism, lack of grounding, etc. LangExtract, a new open-source Python library, is designed specifically to handle these challenges in information extraction. It aims to bridge the gap between LLMs and the need for reliable, grounded, structured data output.
LLMs are designed to generate coherent text-based responses based on probability. This can lead to hallucinations where they create new facts or distort the extracted information to make it sound natural, rather than accurately transcribing it. For structured extraction, exact fidelity is important. Distorted information can invalidate the entire extraction, leading to misinterpretation. While LLMs have improved over time in terms of expanded context windows, large documents or detailed reports can still exceed what an LLM can process in a single go. This necessitates document chunking, which can break the entire flow and make it harder for the LLM to maintain a holistic understanding and extract interconnected information.
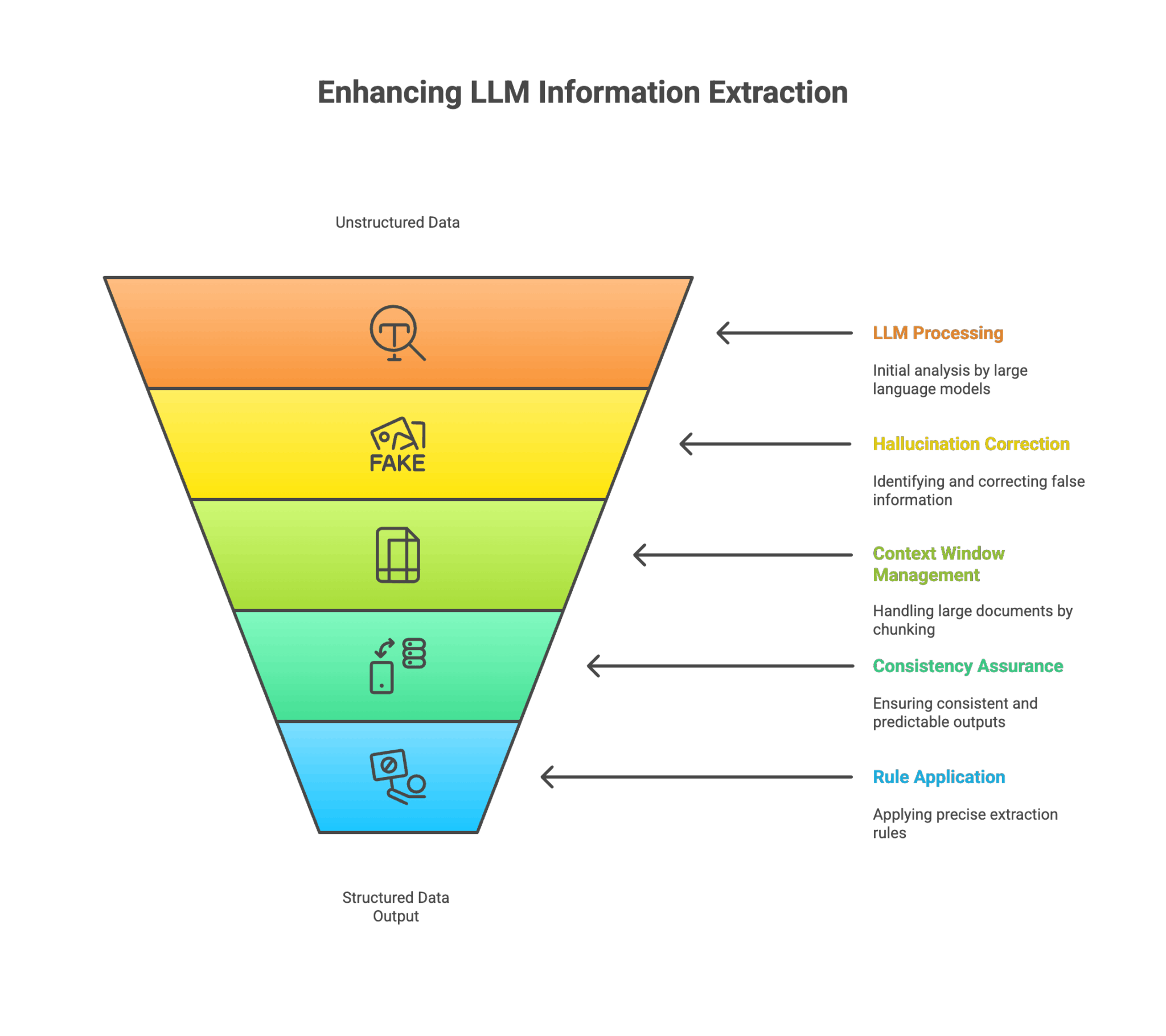
Also, the same prompt passed to an LLM might yield a slightly different structured response due to its probabilistic, non-deterministic nature. This can cause problems in terms of consistency and predictable output, which is important in terms of structured data extraction. While prompt engineering can guide LLMs, defining precise extraction rules for a highly varied or ambiguous document can still be a difficult task.
LangExtract acts as an intelligent layer on top of LLMs, providing the necessary scaffolding and controls to transform their language understanding capabilities into reliable, structured information extraction for unstructured documents.
The core feature of LangExtract is precise source grounding. It’s able to map every extracted entity back to its exact character offsets in the source text. This allows users to visually highlight and verify where each piece of information came from in the document. This is an important feature that can be used for debugging and reliability testing.
LangExtract focuses on ensuring the output always conforms to a predefined JSON schema by using controlled generation techniques using user-defined few-shot examples. It guides the LLM to produce output in the exact requirement, making it an excellent choice for databases, analysis, or other business intelligence applications. This reduces the non-determinism issue.
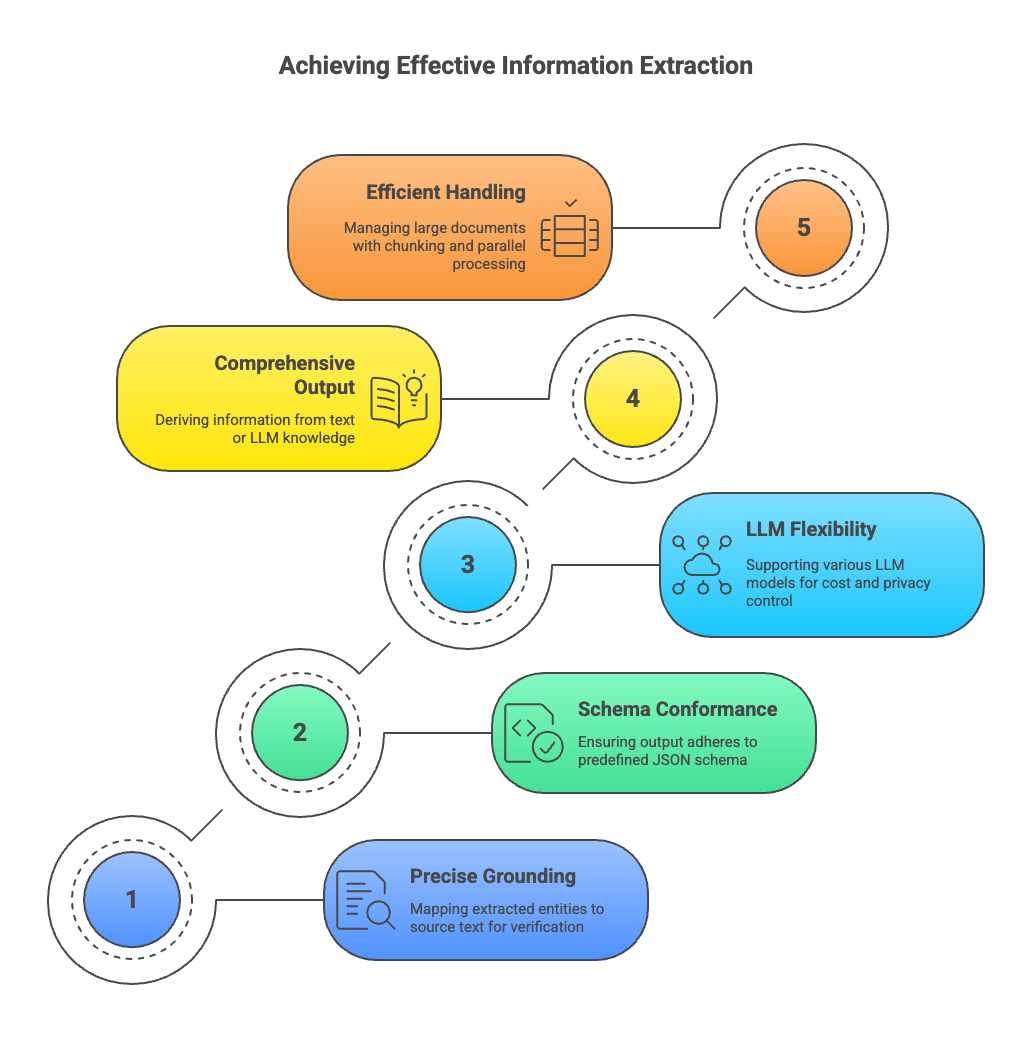
The library is flexible and agnostic in terms of LLM usage. The users can use their preferred LLM models, whether they are cloud-based or open-source on-device models. This provides an efficient way to control cost and privacy. While primarily focused on grounded extractions, LangExtract can also use LLM’s knowledge to supplement extracted information. Users can control whether the LLM derives information explicitly from the text or infers it from its knowledge, allowing for more comprehensive and exhaustive outputs as and when required.
LangExtract is engineered to handle large documents efficiently. It employs the use of chunking strategies, parallel processing, and multi-pass scanning to ensure that the retrieved information from lengthy texts remains accurate, even in million-token contexts where LLM recall might otherwise fall. Instead of using complex regex or extensive model fine-tuning, users can write a concise prompt along with a few high-quality, few-shot examples to guide the LLM towards effective and accurate information retrieval.
Step 1: Install the required libraries –
pip install langextractStep 2: Import the libraries and set up the dotenv file with LANGEXTRACT_API_KEY, which uses the GEMINI API –
import textwrap
import langextract as lx
from dotenv import load_dotenv
import os
load_dotenv()Step 3: Define the prompt with the extraction requirements –
prompt = textwrap.dedent("""\
Extract the company name, specific financial metrics, and market sentiment from the text.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.
- For companies, include the stock ticker.
- For financial metrics, specify the type and value.
- For market sentiment, classify it as 'bullish', 'bearish', or 'neutral'.""")Step 4: Provide a high-quality example to guide the model –
examples = [
lx.data.ExampleData(
text=(
"AlphaTech (AT) announced a quarterly profit of $2.5 billion, exceeding analyst expectations"
" and signaling a strongly bullish trend for the sector."
),
extractions=[
lx.data.Extraction(
extraction_class="company",
extraction_text="AlphaTech",
attributes={"stock_ticker": "AT"},
),
lx.data.Extraction(
extraction_class="financial_metric",
extraction_text="quarterly profit of $2.5 billion",
attributes={"metric_type": "profit", "value": "$2.5 billion"}
),
lx.data.Extraction(
extraction_class="market_sentiment",
extraction_text="strongly bullish trend",
attributes={"sentiment": "bullish"}
),
],
)
]Step 5: Provide an input for processing and execute the extraction process –
input_text = (
"Global Dynamics Inc. (GDI) reported a staggering quarterly revenue of $15 billion, \
But its stock dipped 2%, leading to a neutral but cautious market outlook."
)
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-pro",
)Output –

Step 6: Save the results in a JSONL file –
lx.io.save_annotated_documents([result], output_name="/Users/sachintripathi/Documents/Py_files/LangExtract/extraction_results.jsonl")Output –

Step 7: Visualise the results –
html_content = lx.visualize("extraction_results.jsonl")
html_contentOutput –

Final Output –

LangExtract directly confronts the issues and challenges that arise in unstructured data extraction. Its features, such as source grounding, flexible LLM support, simplifying extraction through few-shot examples, and long-context information extraction, allow efficient processing of unstructured data without sacrificing accuracy. It is invaluable in terms of transforming the imprecise capabilities of LLMs into robust, verifiable, and production-ready information extraction systems.





![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

