
Graph databases are specialised databases that can represent data interconnections and relationships and store data. Graph database performance generally stays constant, unlike relational databases, where join-intensive query performance degrades with increasing dataset size. Knowledge graphs can be built using graph databases to capture data relationships and connections. This allows us to model and reason data efficiently. This article explains the importance of knowledge graphs and how to build them using graph databases based on large language models offered by OpenAI and Langchain orchestration framework.
Table of Content
A graph database is s used to store and manage interconnected information. In contrast to relational databases, which use tables with rows and columns, graph databases use nodes and edges to represent entities and relationships based on the data.
Nodes represent entities in the dataset, such as people, customers, products, etc., whereas edges connect different nodes and show their relationships. For example, in the image below, the nodes are different people, whereas the edges show which person knows whom.
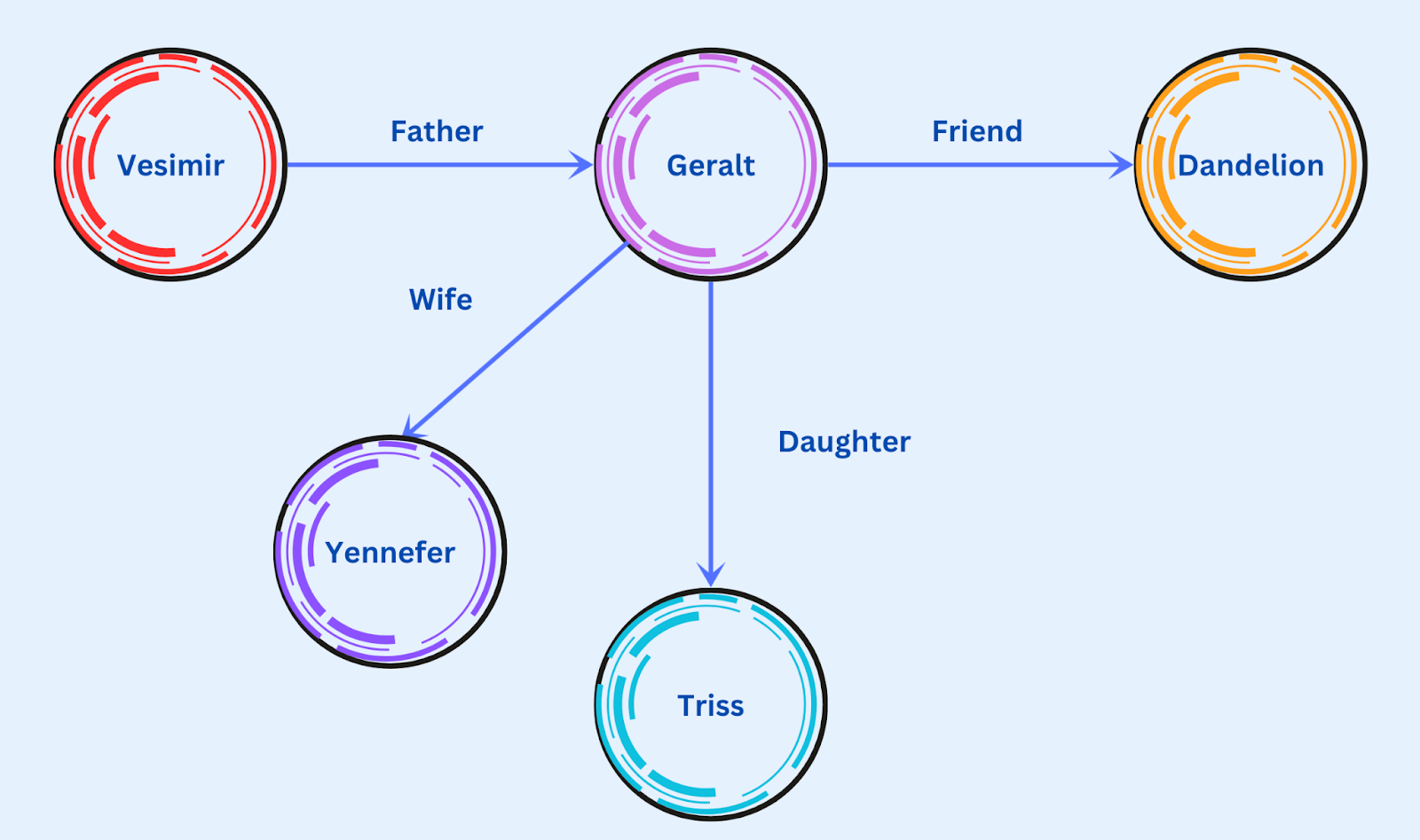
A Simple Graph showing relationships between people
This type of structure uses nodes and edges and allows graph databases to capture hidden and complex relationships efficiently.
Graph databases can be utilised based on the following set of advantages:
The popularity of graph databases has increased by leaps and bounds based on different use cases and applications:
Graph databases can represent user accounts with their connections, group the user based on their social interaction and track how the information flows through the user network.
Graph databases can be used for real-time fraud analysis and detection in conjunction with machine learning algorithms to identify fraud patterns and activity.
A vast number of user accounts, products, reviews, etc. can be easily captured, visualised and analysed using graph databases based on nodes and edges. This can help us understand patterns based on different contexts and enable us to provide dynamic recommendations.
Graph databases employ the use of flexible schema which can be easily changed based on dynamic environments and datasets.
| Relational Databases | Graph Databases | |
| Database Model | Uses tables to organise data into rows and columns. Columns hold attributes whereas the rows hold records. | Uses a graph structure that utilises nodes and edges. Nodes show the entities whereas the edges represent the relationships. |
| Querying Process | Uses SQL for querying | Uses graph querying language such as Cypher |
| Operations | Uses SQL queries for performing database-related operations such as Create, Update, Insert, Delete, Alter, etc. | Uses graph traversal algorithms such as breadth-first and depth-first search for searching and retrieving connected data points. |
| Performance | Uses indexes for searching and joins for operating on multiple tables which is often time-consuming. | Doesn’t employ the use of indexes, it simply traverses between different nodes using connections and navigates which is faster. |
| When to use what? | When you are working with structured data such as transaction records where the data structure is well-defined and the relationships are simple. | When you are working with unstructured data that has complex relationships and evolving schema. |
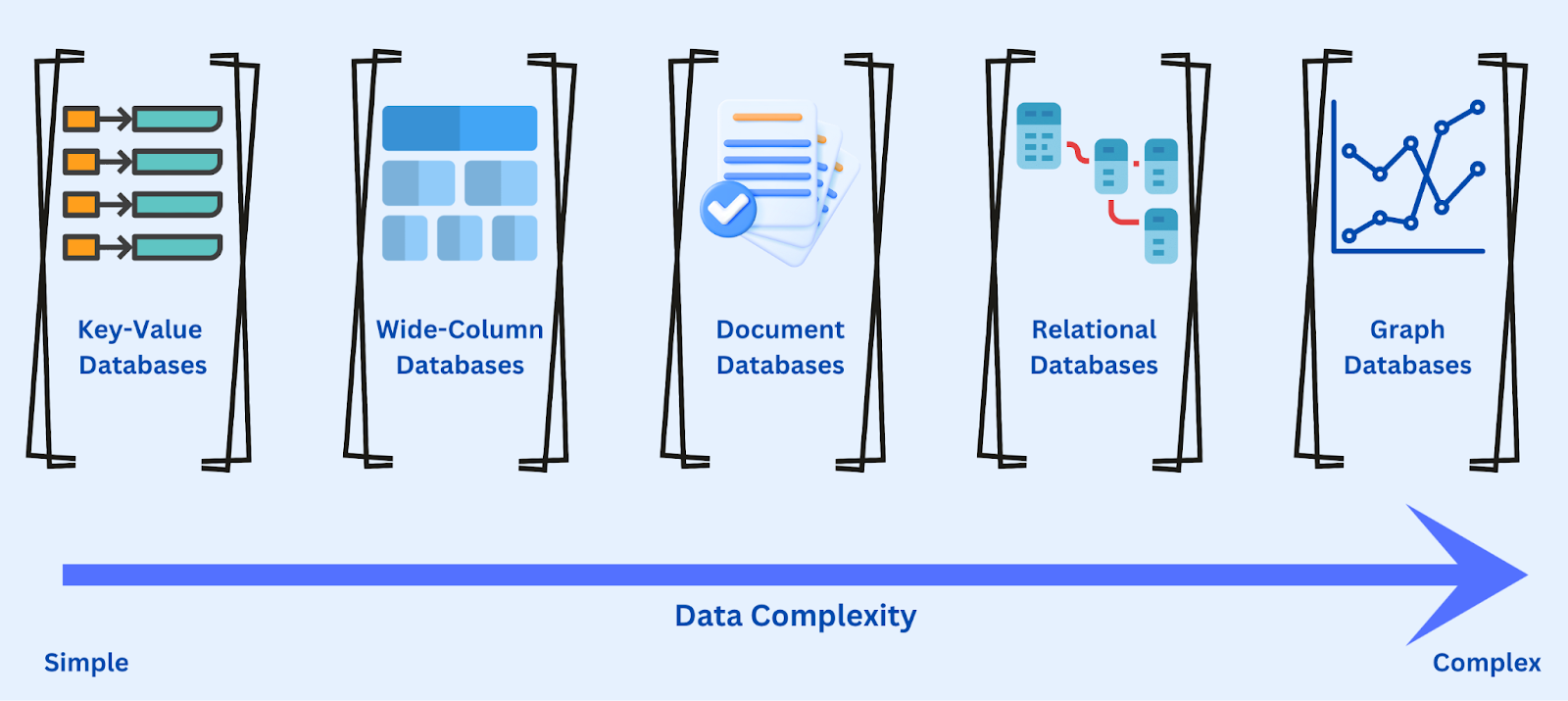
Different categories of databases used based on data complexity
Knowledge graphs are built using graph databases and use an added layer of meaning and context alongside the entities and attributes. The attributes carry descriptive information which are connected to entities.
Knowledge graphs use a concept of ontologies which defines domain knowledge comprising definitions, relationships and rules. These ontologies are integrated with the data to create knowledge that can be used by us. By implementing ontologies, knowledge graphs become more reliable, interoperable and reusable. These ontologies are actionable apart from being descriptive, we can write our logic and make the graph respond more effectively to our queries.
Schema.org is one of the most widely used ontologies for structured data having different entities like people, places, events, etc. For instance, the image below shows a “person schema” example from schema.org:


Example Schema on Persons Entity taken from – https://schema.org/Person
Knowledge graphs excel in the following tasks and can be utilised in efficient data modelling and reasoning:
Knowledge graphs can bring improvements and enhancements in the functionalities of AI Systems such as recommender systems, QA systems and information retrieval tools.
Recommender systems learn user preferences from a set of items and produce suggestions with similar characteristics. These systems can be developed using content-based and collaborative filtering-based methods. These systems can implement knowledge graphs as supplementary information along with user and item preferences to learn the relationships efficiently.
The figure below shows an example of a knowledge graph-based recommendation:
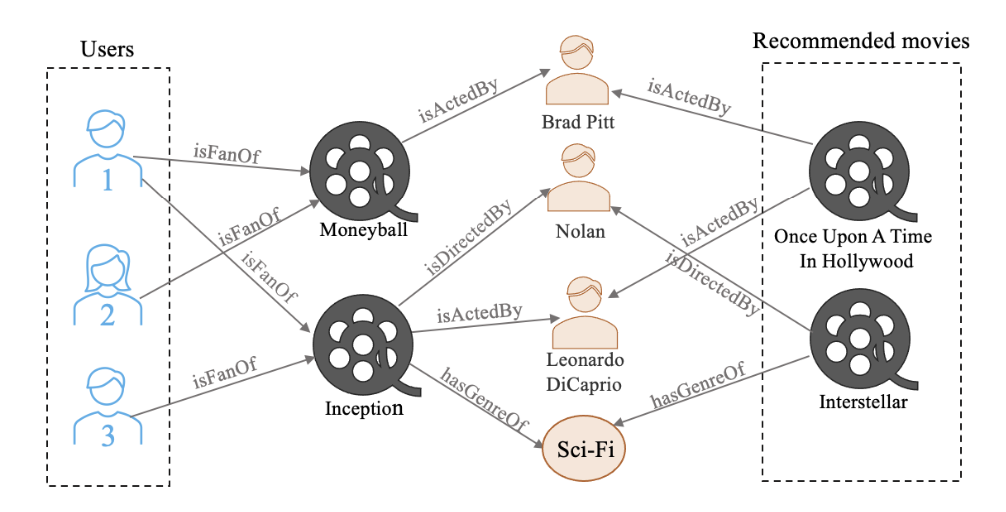
An Example of Knowledge graph-based recommender system – Knowledge Graphs: Opportunities and Challenges Paper
Knowledge graph-based QA systems can analyse the user question and retrieve the portion of knowledge graphs to prepare an answer. The answering tasks are performed using similarity measures or by implementing queries in standard formats such as SPARQL, Json-ld or Cypher.
Knowledge graph-based information retrieval tools can be used to improve the performance and observability of search engines. These tools rely on the advanced representation of the documents based on nodes and edges from knowledge graphs. These representations are matches to the user query for retrieving contextually relevant documents.
In this hands-on tutorial, we will build a knowledge graph using the Langchain orchestration framework, Neo4j graph database and OpenAI.
Step 1: Setup an instance on Neo4j Aura DB Service
Step 2: Install the necessary Python libraries for working with LangChain, Neo4j and OpenAI frameworks:
!pip install openai langchain langchain_openai langchain-experimental langchain-community neo4j unstructuredStep 3: Import the required packages:
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain.text_splitter import CharacterTextSplitter
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_core.documents import Document
from langchain_community.document_loaders import DirectoryLoader
from google.colab import userdata
import osStep 4: Set up Neo4j access variables for connecting with Neo4j’s database instance. The access requires three parameters: URL, username and password. These details are automatically downloaded in a text file when you create the Neo4j instance for the first time.
graph = Neo4jGraph(
url = "neo4j+s://bf*****.neo4j.io",
username = "neo4j",
password = "HO**************************"
)
Step 5: Set up the OpenAI API key which will be used to access the OpenAI’s model for LangChain operations.
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_APIKEY")Step 6: User ChatOpenAI function to set up the chat model parameters. We are only using temperature here, but you can experiment with different parameters as well.
llm = ChatOpenAI(temperature = 0)
llm_transf = LLMGraphTransformer(llm = llm)Step 7: Load a directory for input data (Save your input data files – TXTs, PDFs, etc. in a directory and use its path) using DirectoryLoder, then we will use CharacterTextSplitter to create chunks from our text data based on the chunk_size and chunk_overlap. Chunk_size is the maximum number of characters stored in a chunk whereas the chunk_overlap is the number of characters that need to overlap between adjacent chunks.
loader = DirectoryLoader('/content/Textdata')
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size = 1000, chunk_overlap = 20
)
documents = text_splitter.split_documents(loader.load())
for d in documents:
del d.metadata['source']Step 8: Use convert_to_graph_documents for converting documents into graph documents and building nodes and relationships for our knowledge graph.
graph_documents = llm_transf.convert_to_graph_documents(documents)
print(f"Nodes:{graph_documents[0].nodes}")
print(f"Relationships:{graph_documents[0].relationships}")Output:
Nodes:[Node(id=’A Game Of Thrones’, type=’Book’), Node(id=’Westeros’, type=’Continent’), Node(id=’King Robert’, type=’Person’), Node(id=’Ned Stark’, type=’Person’), Node(id=’Jon Arryn’, type=’Person’), Node(id=’Cersei Lannister’, type=’Person’), Node(id=’Lannisters’, type=’Family’), Node(id=’Catelyn’, type=’Person’), Node(id=’Bran’, type=’Person’), Node(id=’Jaime Lannister’, type=’Person’), Node(id=”Robert’S Queen”, type=’Person’), Node(id=’Winterfell’, type=’Castle’), ……
Relationships:[Relationship(source=Node(id=’A Game Of Thrones’, type=’Book’), target=Node(id=’Westeros’, type=’Continent’), type=’SETTING’), Relationship(source=Node(id=’King Robert’, type=’Person’), ……]
Step 9: Adding the generated nodes and relationships in our Neo4j database’s instance for visualization and analysis through a knowledge graph.
graph.add_graph_documents(graph_documents)Step 10: Check Neo4j’s web instance for the knowledge graph.
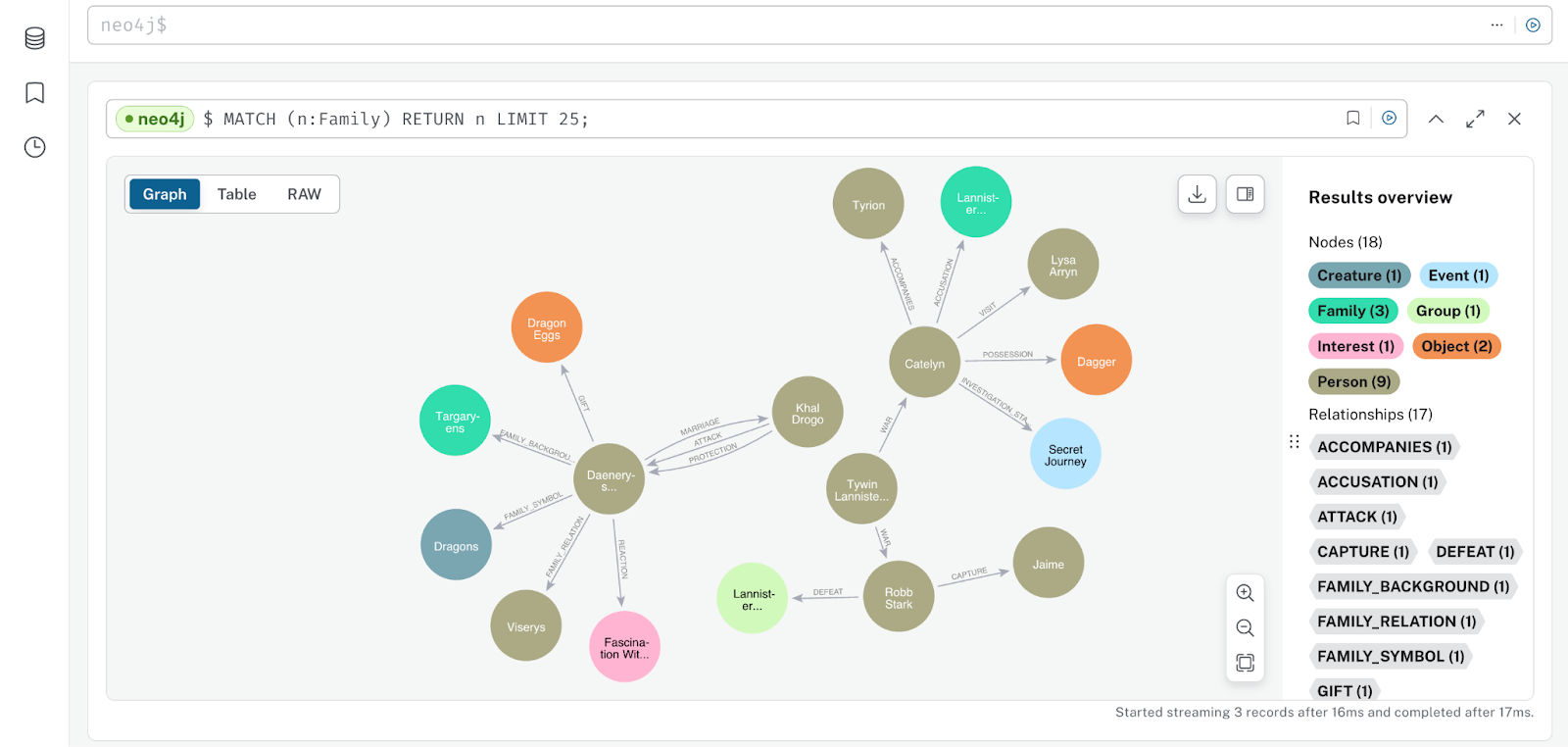
We can see the relationships as per the Game of Thrones script data knowledge graph
Step 11: We can now use LangChain’s graph query with cypher query language for running our queries based on the knowledge graph’s entities and relationships. In the query below, we are printing Person node values.
graph.query(""" MATCH (n: Person) RETURN n """)Output:

Step 12: We can also use LangChain’s GraphCypherQAChain for running queries across our knowledge graph and getting results.
from langchain.chains import GraphCypherQAChain
llm = ChatOpenAI(temperature = 0)
chain = GraphCypherQAChain.from_llm(
graph=graph, llm=llm, verbose=True
)
chain.invoke("Who are the different persons?")Output:

Here we can see that LangChain’s GraphCypherQAChain can retrieve the data based on Person ID (node in the knowledge graph) and it’s true as well as per the data supplied. Also, the knowledge graph created on Neo4j’s web instance is interactive thereby assisting us in analysing the data and performing appropriate decision-making without the need for any additional cypher queries or coding.
We can understand from the hands-on that irrespective of the size of the data, using knowledge graphs can enhance our understanding of context and relationships in unstructured data efficiently and also give contextually relevant results when querying them. Langchain’s integration with Neo4j enables us to use tools such as GraphCypherQAChain and Cypher graph query language for efficient querying and response generation based on the created knowledge graph.








