
The world of Artificial Intelligence is rapidly evolving, moving beyond conversational chatbots to intelligent “agents” capable of complex tasks. This article delves into Meta’s groundbreaking Gaia2 benchmark, a crucial new testing ground designed to assess AI agents‘ true readiness for the unpredictable real world. We’ll explore why traditional evaluations fall short, the surprising tradeoffs discovered between AI “smartness” and speed, and the powerful potential of AI teamwork in shaping the next generation of truly practical AI assistants.
We’ve all witnessed the remarkable advancements in artificial intelligence. Chatbots can write poems, generate code, and answer complex questions in seconds. But the next major frontier for AI is not just about talking; it’s about doing. We’re moving towards a future of AI “agents” who are smart assistants that can perform multi-step tasks for us, like booking a trip, managing our calendars, or sorting through our emails to find crucial information. The ultimate goal is an AI that can handle real-world complexity just as a human assistant would. However, a groundbreaking paper from Meta’s Superintelligence Labs suggests we have a long way to go, and the tests we’ve been using to measure AI might not be telling the whole story.

Evolution of Agentic AI
How do we know if an AI is getting smarter? We test it. For years, AI benchmarks have been a turn-based game. The AI is given a task, and the world essentially pauses while the AI “thinks” and performs its actions. But the real world isn’t a turn-based game. It’s dynamic and chaotic. While you’re trying to book a flight, you might receive a new email that changes your plans, or a friend might message you with a conflicting schedule.

A representation of the paused world vs the real world
Most AI evaluations don’t account for this messiness. They operate in a static setting, which hides common ways an agent might fail in a real, ever-changing environment. An AI that performs perfectly when the world is on pause might completely fall apart when things are happening in real time. Real-world plans are vulnerable to unforeseen issues; a calendar’s availability may be inaccurate, a confirmed ride can be canceled, and sudden traffic can easily derail a schedule. To build truly useful agents, we need to test them in a world that doesn’t wait for them.
To address this gap, researchers at Meta developed two things, the Meta Agents Research Environments (ARE) and a new benchmark called Gaia2. Think of ARE as a highly realistic simulator for an AI agent. It’s a virtual world, specifically mimicking a smartphone, complete with apps like email, messaging, calendars, and file systems.
What makes ARE special is that it’s asynchronous. Time flows continuously, and events can happen at any moment, independent of what the agent is doing. For example, while the agent is composing an email, a friend might reply to an earlier message, forcing the agent to adapt on the fly.
Gaia2 is the set of challenges within this simulated world. These aren’t simple trivia questions. The scenarios are designed to test capabilities essential for real-world usefulness, such as:
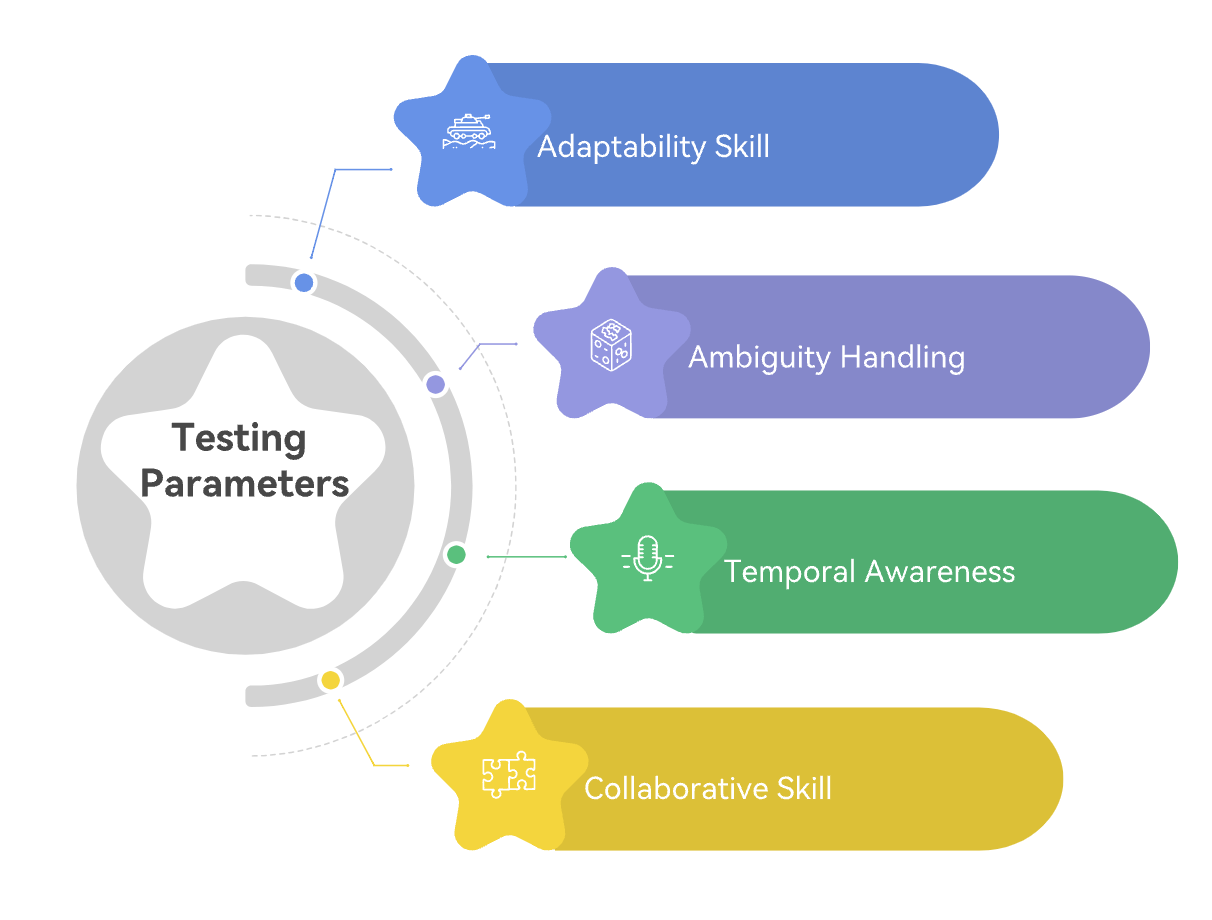
Gaia2 testing parameters
A truly capable AI agent must navigate the complexities of real-world tasks with a multifaceted intelligence. This begins with its ability to handle ambiguity, discerning when a request is vague or contradictory and intelligently seeking clarification rather than making risky assumptions. As it executes a plan, the agent must also demonstrate temporal awareness, performing actions under strict time constraints, such as sending a follow-up message precisely when a deadline is missed. Since the real world is unpredictable, the agent must possess adaptability, allowing it to dynamically change its strategy in response to unexpected events. Finally, for tasks that exceed its own capabilities, it must excel at collaboration, seamlessly working with other AI agents to achieve a common goal.
The researchers tested a wide range of leading AI models on the Gaia2 benchmark, including proprietary models like GPT-5, Claude-4 Sonnet, and Gemini 2.5-Pro, as well as top open-source alternatives. The results were fascinating.
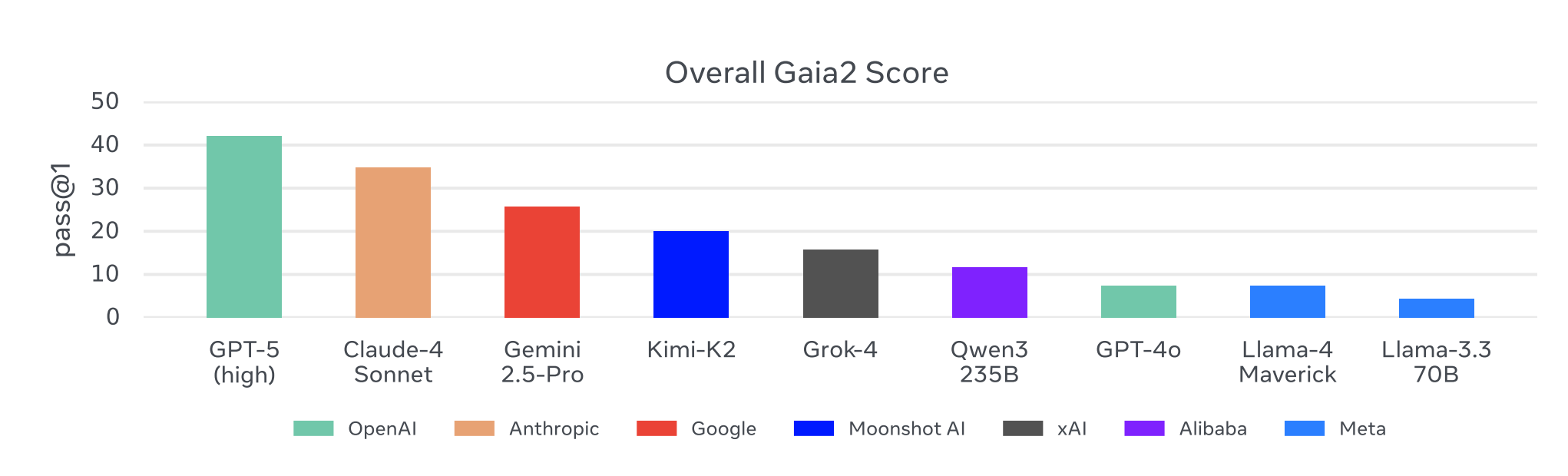
Comparing the Gaia2 score of popular models
While frontier models from OpenAI, Anthropic, and Google performed the best overall, no single model dominated across the board. Models that were excellent at basic search and execution tasks often struggled when faced with ambiguity or the need to adapt to new information. GPT-5 (high) achieved the top score, but even it was far from perfect, highlighting that there is significant room for improvement. This shows that our most advanced AIs still have critical blind spots when it comes to the kind of fluid, dynamic reasoning that humans find easy.
One of the most revealing findings from the study is what the researchers call an “inverse scaling law” for time. Common sense suggests that a smarter, more capable AI would also be faster and more efficient. However, the Gaia2 results show the opposite can be true. Models that engaged in deeper, more complex reasoning performed the best on difficult tasks like navigating ambiguity. But this extra “thinking” time made them extremely slow and ineffective at time-sensitive tasks.

Smartness and Speed are not achievable simultaneously
For example, GPT-5’s most powerful reasoning mode scored very high on execution tasks but scored a zero on the time-based scenarios because it was too slow to act within the required deadlines. In contrast, faster and less complex models performed better on time-sensitive tasks. This highlights a critical tradeoff. For an AI agent to be practical, it must not only be smart but also know when to act quickly and when to think deeply. Intelligence isn’t just about getting the right answer; it’s also about efficiency.
Another exciting area to be explored is agent collaboration. Instead of one AI trying to do everything, what if a task were broken down and handled by a team of specialized AI agents? The Gaia2 benchmark tested this with its Agent2Agent scenarios, where apps like “Shopping” or “Email” were replaced by dedicated agents that the main agent had to communicate with.
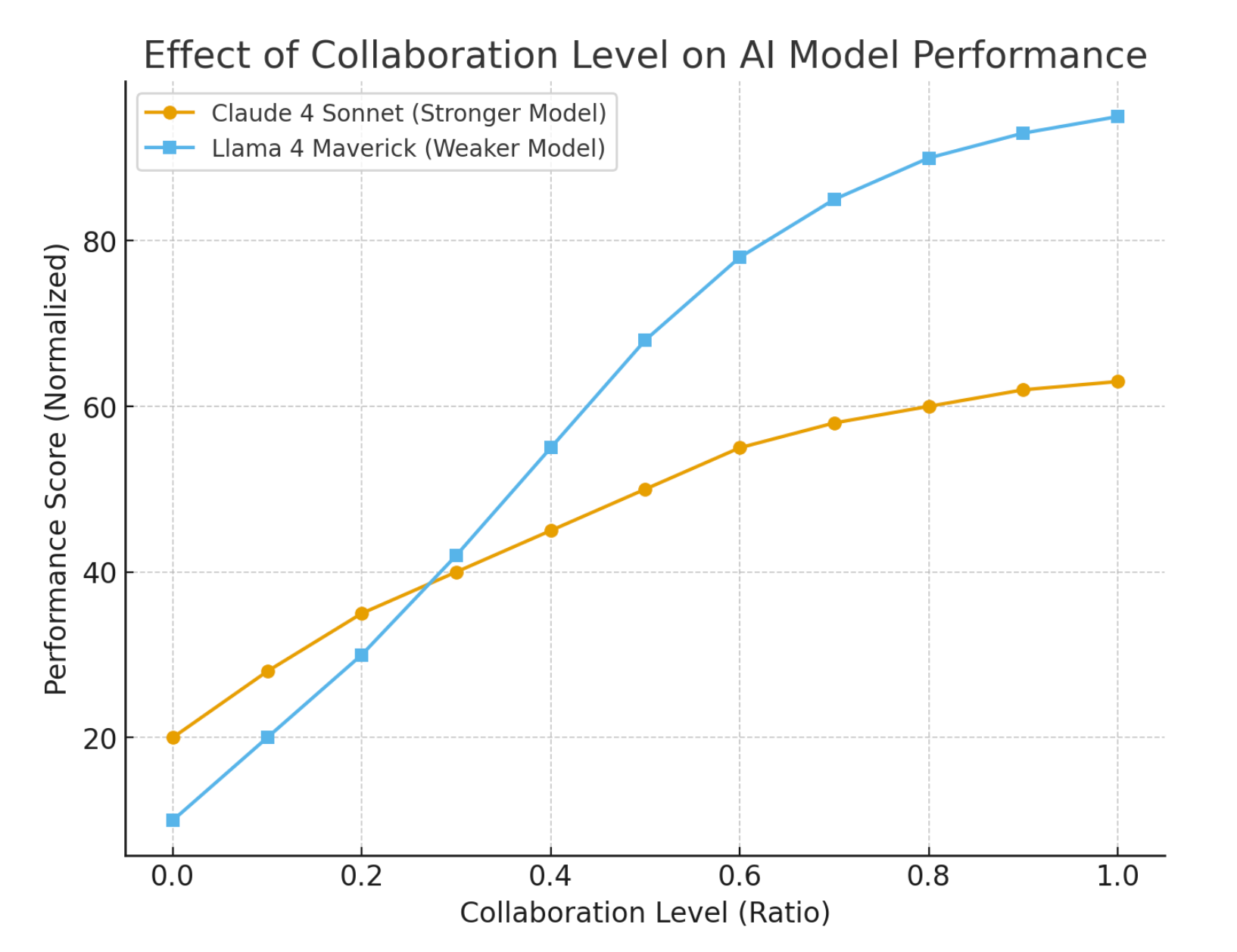
A dummy representation of the model performance vs collaboration level
The results showed that this collaborative approach can significantly boost performance, especially for less powerful models. By breaking a complex problem into smaller sub-goals and delegating them, weaker models became more stable and effective. This points to a future where our primary AI assistant might act more like a manager, coordinating a team of specialized AIs to get a job done efficiently.
The Gaia2 benchmark and the insights from this paper mark an important step forward in our quest for truly useful AI agents. They show us that simply building bigger models is not enough. The path forward requires a focus on the skills that matter in the real world: adaptability, efficiency, and collaboration. We need AIs that can handle the unpredictable nature of our lives, that can adapt their thinking to the task at hand, and that can work together to solve complex problems. The journey to building a true AI assistant is still long, but with smarter ways to measure progress like Gaia2, we’re getting a much clearer map of the road ahead.






