
The development of retrieval-augmented generation techniques has grown considerably in the area of large language models and gen AI application development. However, there is an inherent need for a standardised framework for comparing and evaluating RAG approaches in a compatible environment. LLM Orchestration frameworks such as LlamaIndex and LangChain offer a huge set of customisations when it comes to RAG, but often fail in meeting the needs of researchers due to their flexibility. FlashRAG offers an open-source modular toolkit that helps researchers compare and reproduce existing RAG methods within a single unified framework.
This article explores FlashRAG and its internal architecture towards achieving modularity and RAG reproducibility.
Table of Content
FlashRAG (https://github.com/ruc-nlpir/flashrag) is a toolkit that aims to assist researchers in reproducing and developing RAG algorithms. This library allows users to build RAG pipelines, and use RAG components, and datasets to accelerate their RAG workflow. FlashRAG differs from existing RAG toolkits in the following ways:
FlashRAG differs from the other available RAG toolkits in five areas, namely, modular component, automatic evaluation, corpus helper, number of provided datasets and number of support work.
The toolkit’s composition of modularity is quantified by modular components. The corpus helper shows if the toolkit provides supplementary help and support in terms of corpus processing, cleansing and chunking. The automatic evaluation shows if the toolkit provides automated evaluation capabilities for assessing RAG performance.
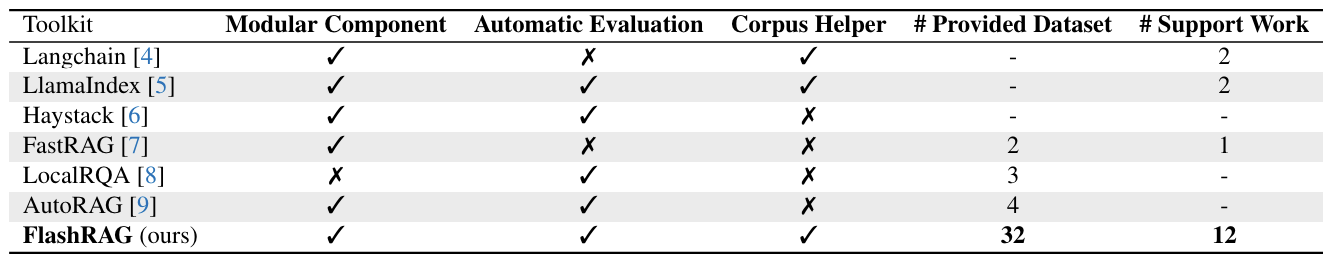
Comparison with other RAG toolkits.
The structure of FlashRAG includes three modules, namely, environment module, component module and pipeline module.
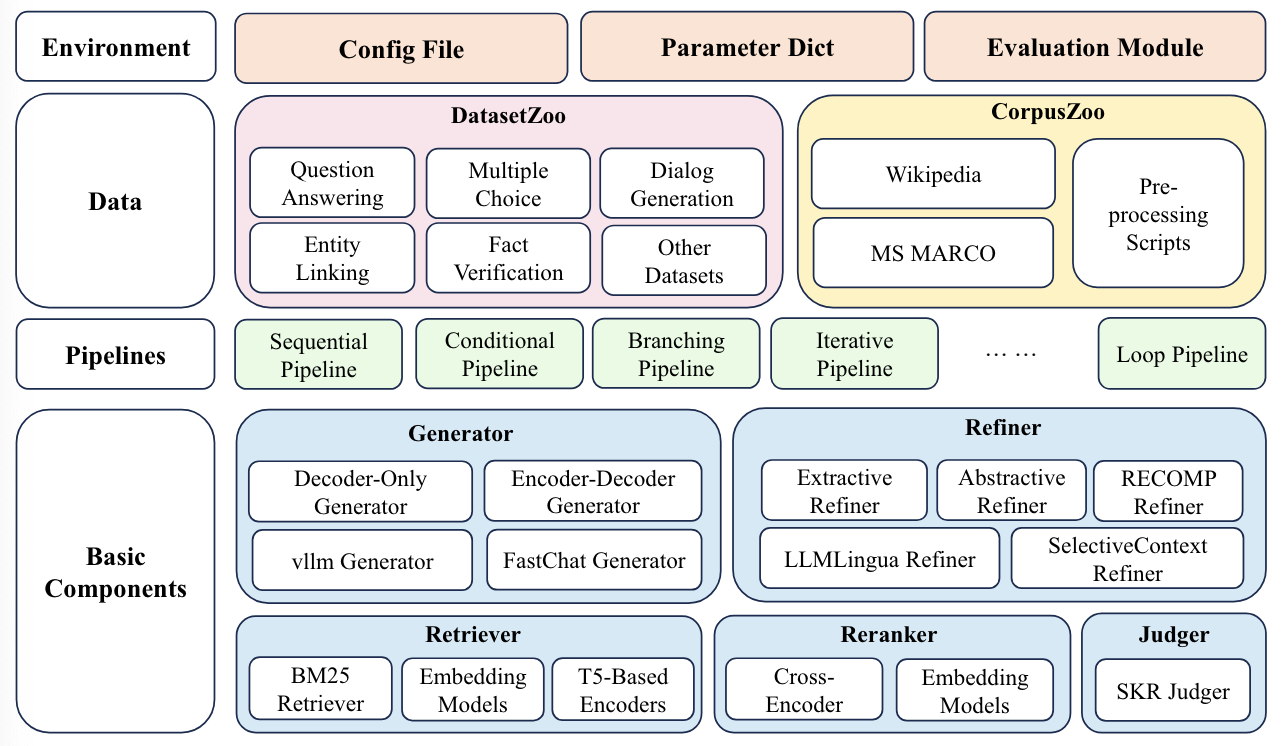
Overview of FlashRAG Components
Environment Module – The environment module is the fundamental component consisting of configuration details, hyperparameters and evaluation metrics required for RAG experimentation.
Component Module – The component module encapsulates five main sub-components: Judger, Retriever, Reranker, Refiner and Generator. The Judger sub-component assesses if the query requires retrieval using the Self-Knowledge guided Retrieval-Augmentation (SKR) method. The retriever sub-component comprises retrieval implementations such as Pyserini for sparse retrieval, BERT-based embedding models for dense retrieval, and FAISS for vector database computations.
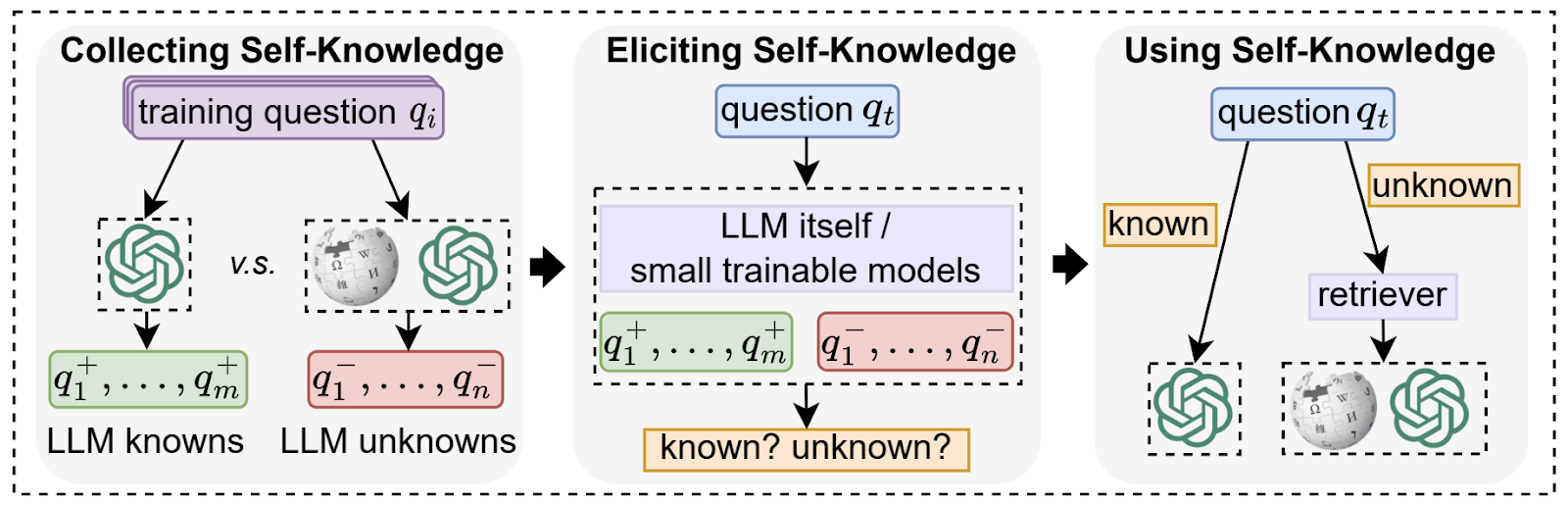
The Reranker sub-component operates on the output of the retriever sub-component to increase the accuracy of retrieval by re-ordering the output to prioritise relevant information. The Refiner reduces the noise and token usage from retrieved documents, thereby, increasing the final response. Generator is the final sub-component which uses two leading LLM acceleration libraries – vllm and FastChat.
Pipeline Module – The pipeline module processes the data provided by the user, implements and executes the corresponding RAG process and provides the final evaluation output along with the intermediate results. FlashRAG supports four categories of process flows – Sequential, Branching, Conditional and Loop. The sequential pipeline uses a linear execution flow, while, the branching pipeline implements multiple flows in parallel for a single query and merges the results from all flows for the final output. The conditional pipeline uses the Judger sub-component to judge an outcome and direct the query into different execution flows based on the judgement. The loop pipeline uses multiple cycles between retrieval and generation processes for improved outcomes.
FlashRAG supports two different categories of evaluation metrics:
Retrieval-aspect Metrics – These metrics evaluate retrieval quality. FlashRAG supports four metrics in this category – recall@k, precision@k, mean average precision and F1@k.
Generation-aspect Metrics – These metrics quantify the quality of generation. FlashRAG supports five metrics in this category – token-level F1 score, exact match, accuracy, BLEU and ROUGE-L.
FlashRAG is an excellent toolkit for researchers to compare, evaluate and reproduce RAG algorithms with ease and efficiency using benchmark datasets and corpus. The evaluation techniques included in FlashRAG provide a comprehensive view of the RAG process execution giving increased control over RAG approaches and its investigations.






