
Traditional search methods often fall short in capturing the semantics and complexities of data. This is where vector search emerges as a solution. By representing data as numerical vector, vector search unlocks the ability to understand semantic meaning and relationships. MongoDB’s Atlas Vector Search is a tool that enables users to build intelligent applications by combining the flexibility of a document database with the efficiency of vector search. This article provides a hands-on tutorial on Atlas Vector Search with explanation.
Vector search is a technique of finding and retrieving information based on the meaning and context of data. It uses the concept of numerical representations known as vectors. Vectors are mathematical objects/quantities having both magnitude and direction. They can be represented as arrays of numbers, where each element represents a specific dimension or component.
Vector search uses the concepts of embeddings, vector space and semantic meaning along with similarity search. An embedding, numerical representation of the data, is placed in a high-dimensional space. The position of the vector in this space reflects its semantic meaning, that means similar items will have vector closer together.
Instead of treating words as isolated entities, vector embeddings represent them as multidimensional vectors. Each dimension captures a specific aspect of the word, like its meaning, part of speech, or sentiment. Words with similar meanings tend to have similar vector representations in this multidimensional space. For example: “helicopter”, “drone” and “rocket” being close neighbours, reflect their semantic closeness.
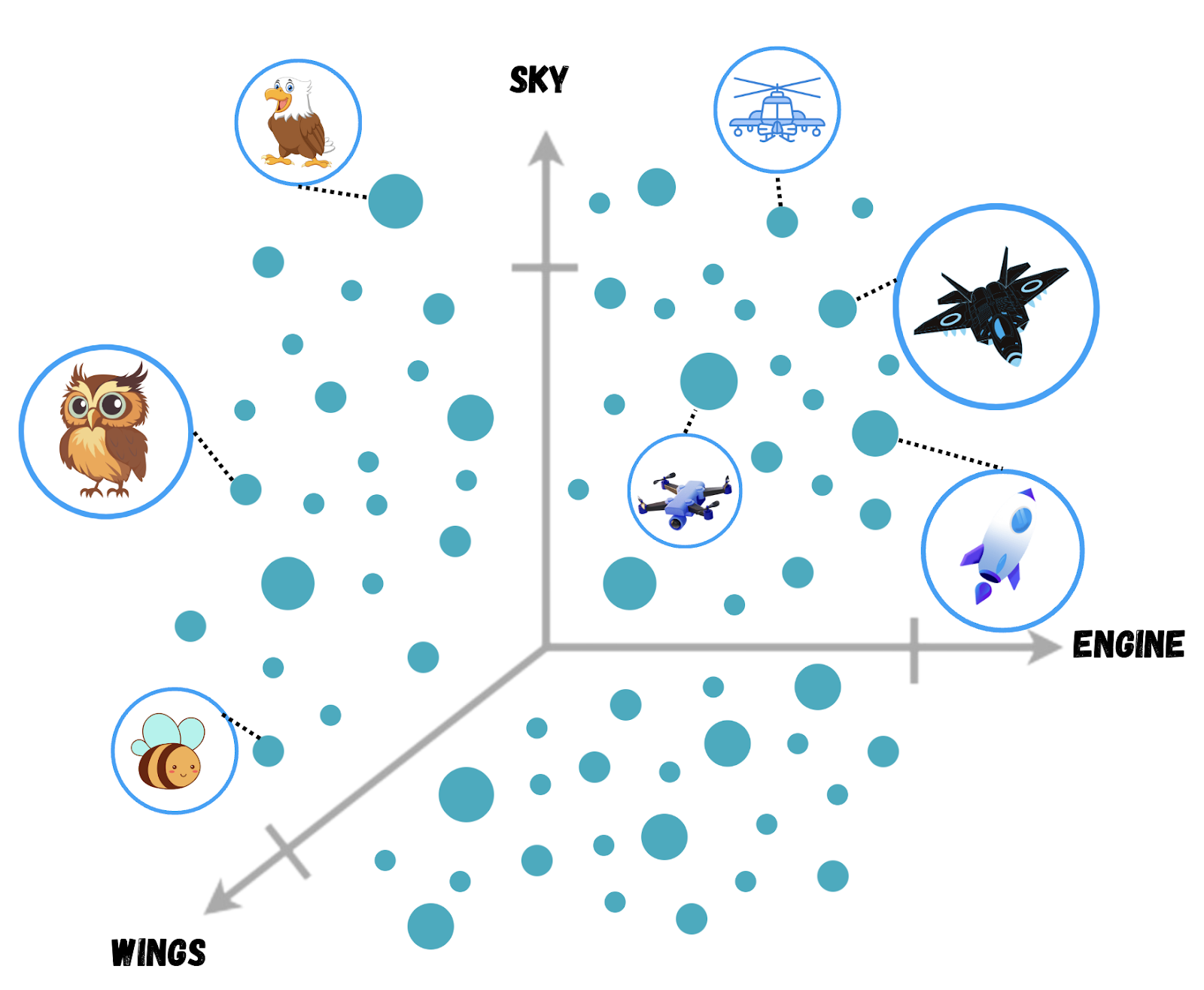
The search query is also transformed into a vector. The system then calculates the distance between the query vector and all other vectors in the data. The items with vectors closest to the query vector are considered most similar and are ranked accordingly. As a final output, the system returns the top-ranked items as search results.
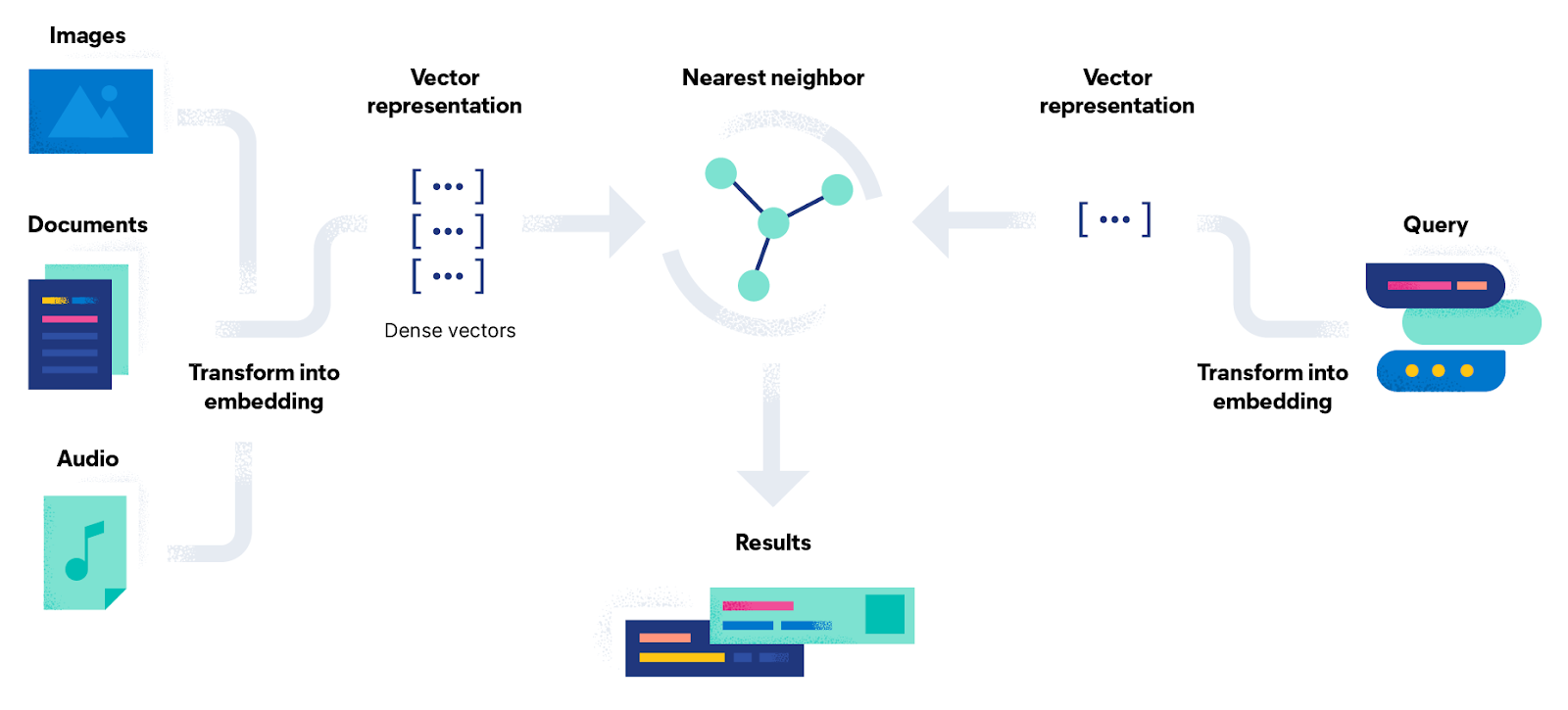
MongoDB Atlas Search is a feature integrated directly into MongoDB’s cloud database service. It combines the robust document storage capabilities of MongoDB with advanced search functionalities allowing users to perform complex queries on their data without requiring a separate search engine.
Atlas Search enables full-text search across text fields in MongoDB documents. Users can search for specific words, phrases, or even fuzzy matches within the data. This goes beyond simple text matching as it incorporates advanced search elements such as relevance scoring, which helps in ranking results based on the degree of their match with search query.
Another standout feature of Atlas Search is its seamless integration with MongoDB’s aggregation pipeline. This allows uses to combine data processing operations with search queries, enabling data manipulations and analysis in a single operation.
Atlas Vector Search is a feature built on top of Atlas Search that allows for similarity-based searches using vector representations of data. It provides an efficient way to store, index, and query high-dimensional vector data, which is fundamental to many LLM applications. These models often represent text, images, etc. as dense vectors, and being able to quickly find similar vectors is the key to their functionality.
Atlas Vector Search integrates seamlessly with a wide variety of LLMs and frameworks such as LangChain, LlamaIndex, OpenAI, Cohere, Hugging Face, Haystack, MS Semantic Kernal and AWS which further increases its utility and application.
In order to perform vector search in Atlas, the users need to create an Atlas Vector Search index which are separate from basic database indexes and are used to efficiently retrieve documents that contain vector embeddings at query-time. In the vector search index definition, the users need to index the fields in the collection that contain embeddings for performing vector search against those fields.
Atlas Vector Search supports Approximate Nearest Neighbor (ANN) search with Hierarchical Navigable Small Worlds (HNSW) algorithm and Exact Nearest Neighbor (ENN) search.
Let’s implement MongoDB’s Atlas Vector Search and perform Retrieval Augmentation Generation.
Prerequisites:
A: Signup/Login on MongoDB Atlas Webpage and create a default cluster (M0 – Free)
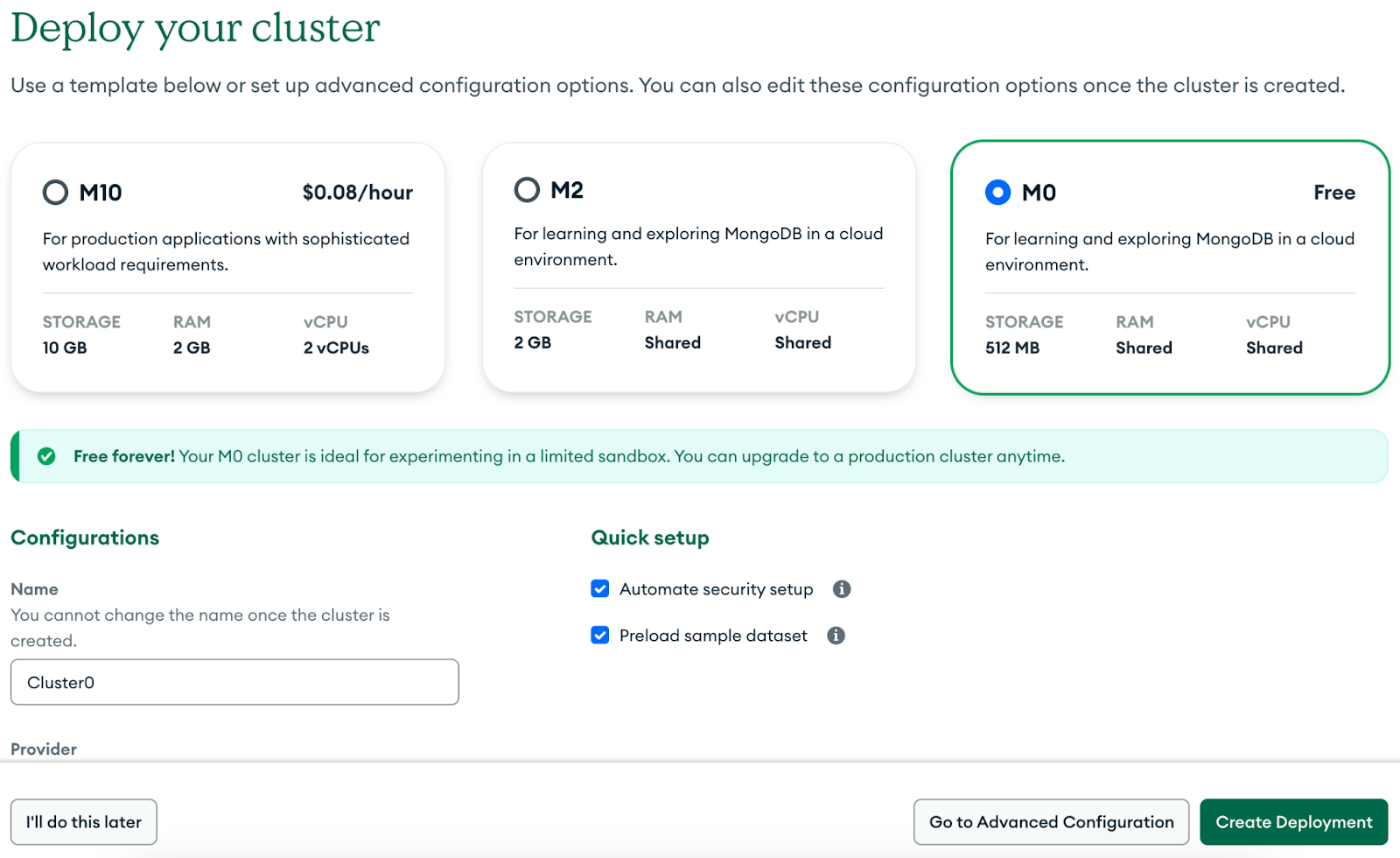
B: Make a note of the connnection string – this will be utilised in connecting with the cluster.
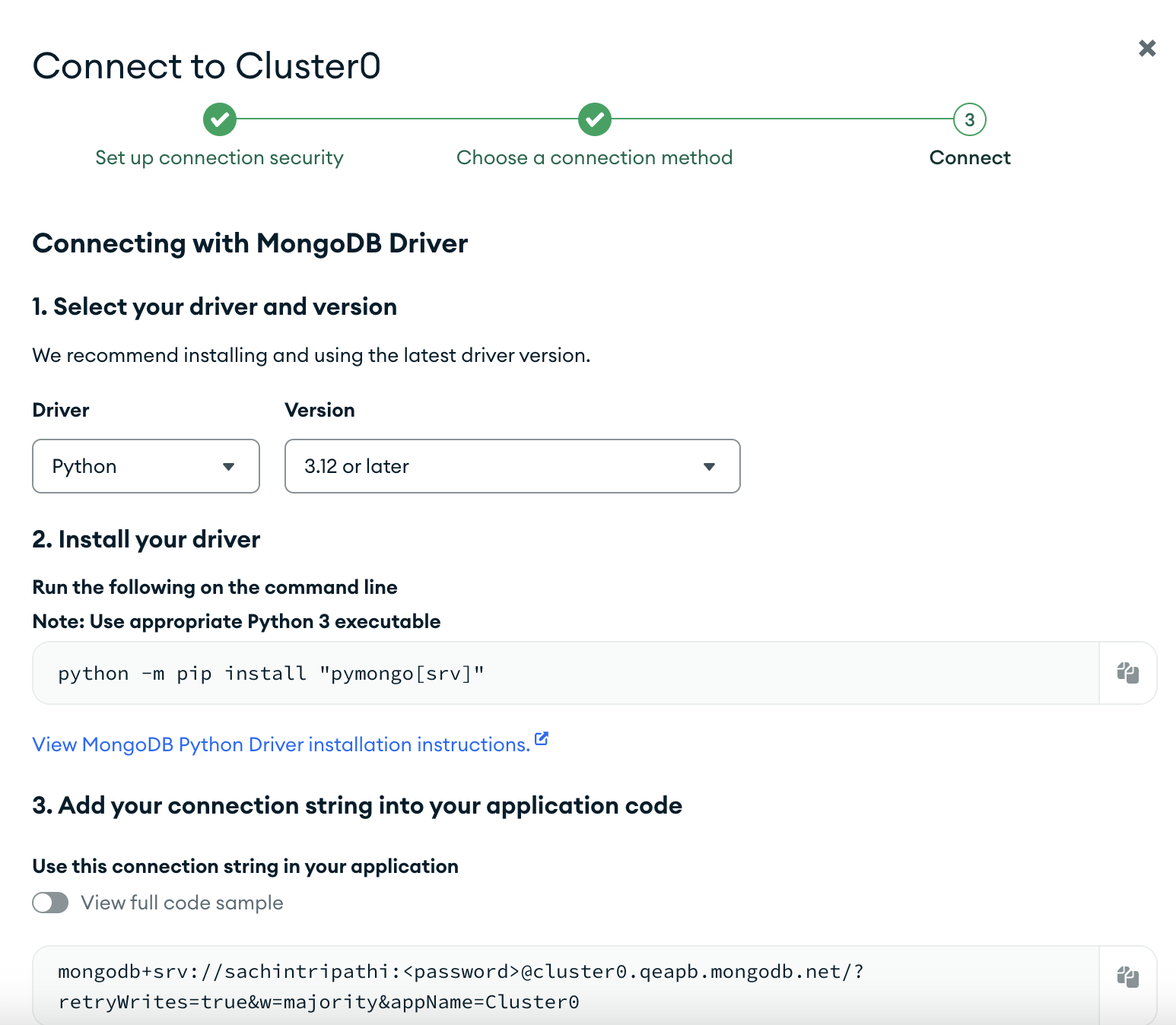
After Atlas has been setup, let’s go to out Python IDE and code.
Step 1: Install the required libraries
pip install --quiet --upgrade llama-index llama-index-vector-stores-mongodb llama-index-embeddings-openai pymongoStep 2: Import the libraries
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, StorageContext
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.settings import Settings
from llama_index.core.vector_stores import MetadataFilter, MetadataFilters, ExactMatchFilter, FilterOperator
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.vector_stores.mongodb import MongoDBAtlasVectorSearch
import getpass, os, pymongo, pprintStep 3: Setup the OpenAI API and MongoDB Atlas Connection String
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
ATLAS_CONNECTION_STRING = getpass.getpass("MongoDB Atlas SRV Connection String:")Step 4: Configure LlamaIndex settings for OpenAI Embedding Model
Settings.llm = OpenAI()
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
Settings.chunk_size = 256
Settings.chunk_overlap = 20Step 5: Load the data and create a vector store
sample_data = SimpleDirectoryReader(input_files = ["data/waitgpt.pdf"]).load_data()
mongodb_client = pymongo.MongoClient(ATLAS_CONNECTION_STRING)
atlas_vector_store = MongoDBAtlasVectorSearch(
mongodb_client,
db_name = "llamaindex_db",
collection_name = "test",
index_name = "vector_index"
)
vector_store_context = StorageContext.from_defaults(vector_store = atlas_vector_store)Step 6: Store the data as vector embeddings
vector_store_index = VectorStoreIndex.from_documents(
sample_data, storage_context=vector_store_context, show_progress = True
)Step 7: Setup Atlas Search for MongoDB Cluster and configure it using the following JSON file
{
"fields": [
{
"type": "vector",
"path": "embedding",
"numDimensions": 1536,
"similarity": "cosine"
},
{
"type": "filter",
"path": "metadata.page_label"
}
]
}
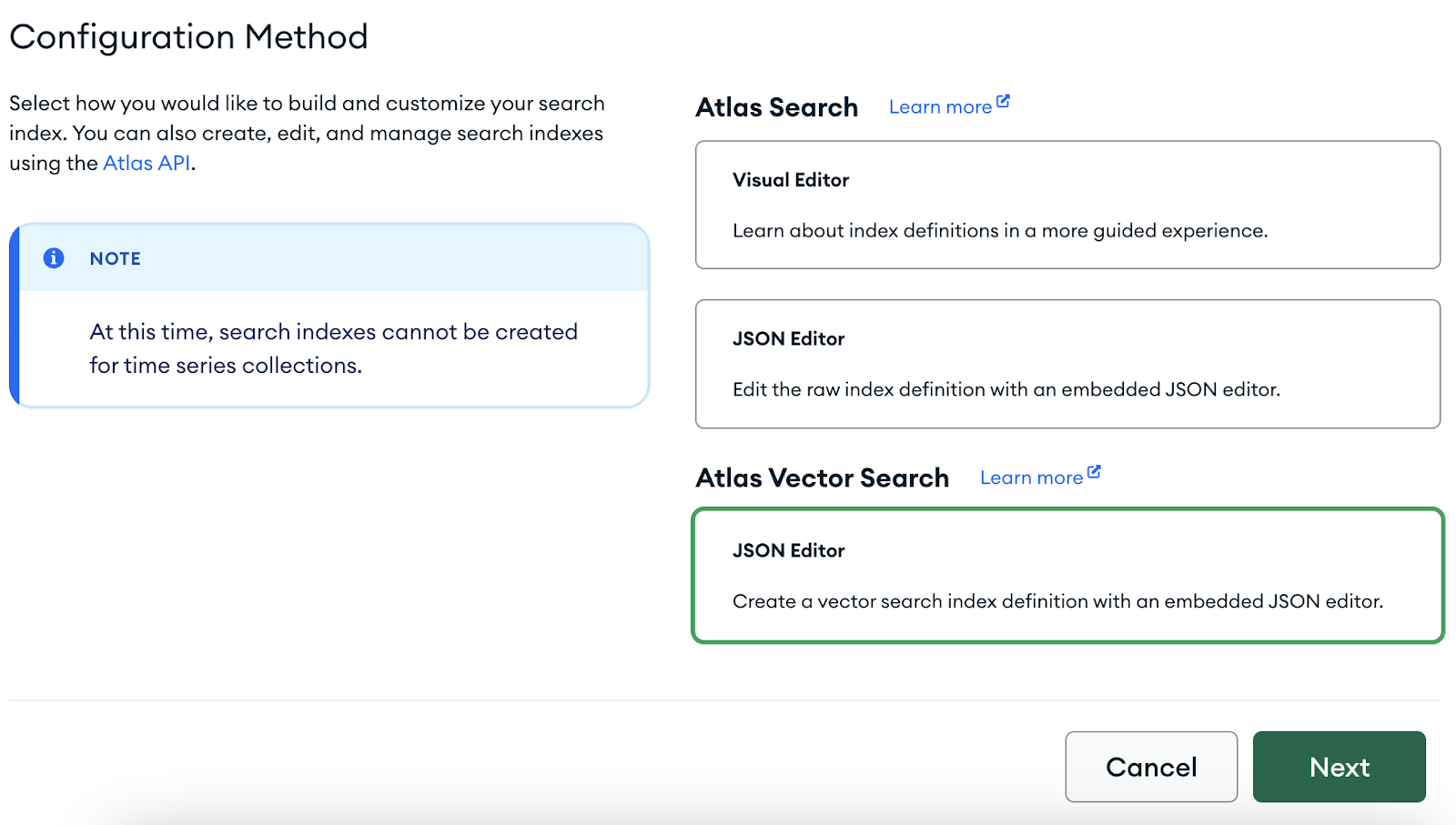
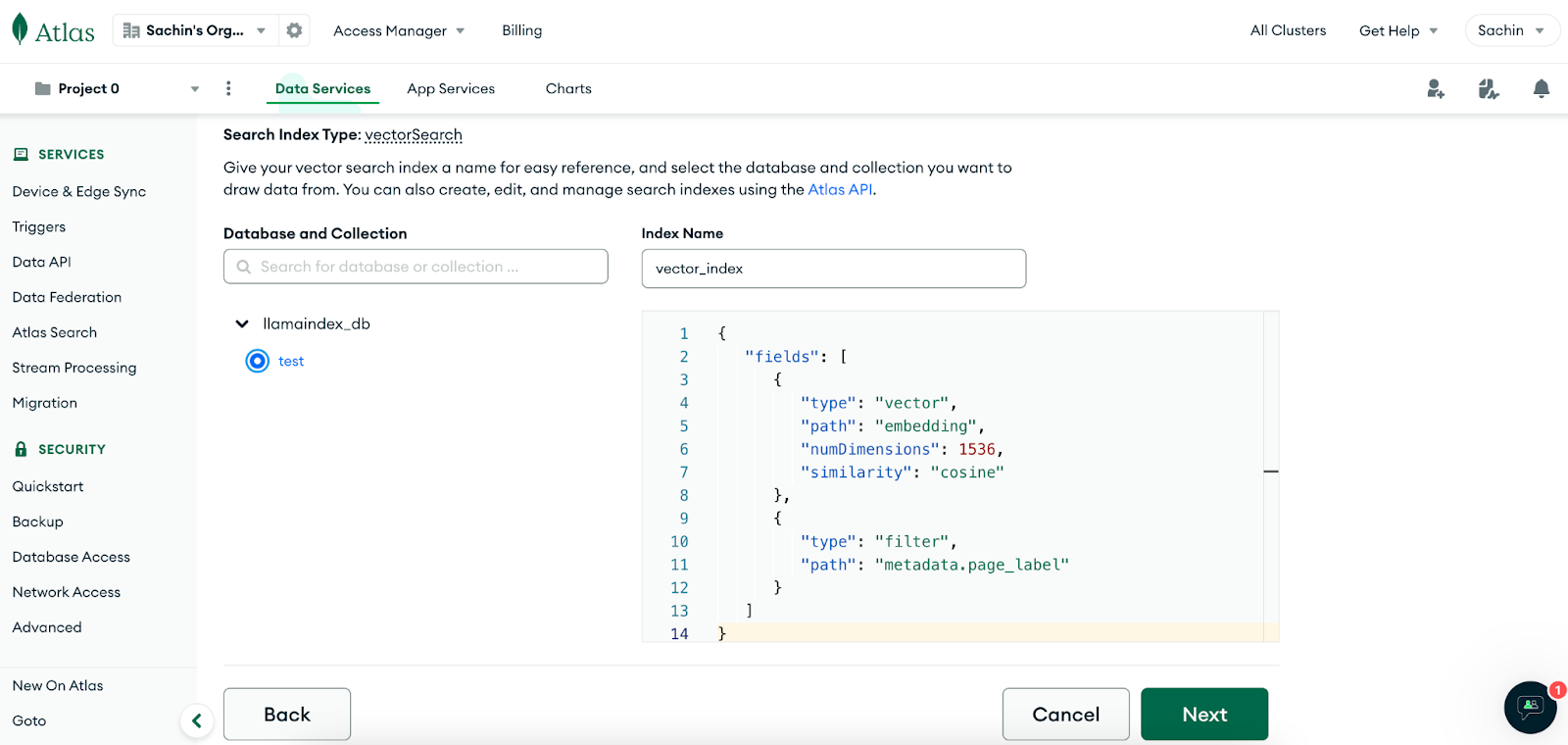
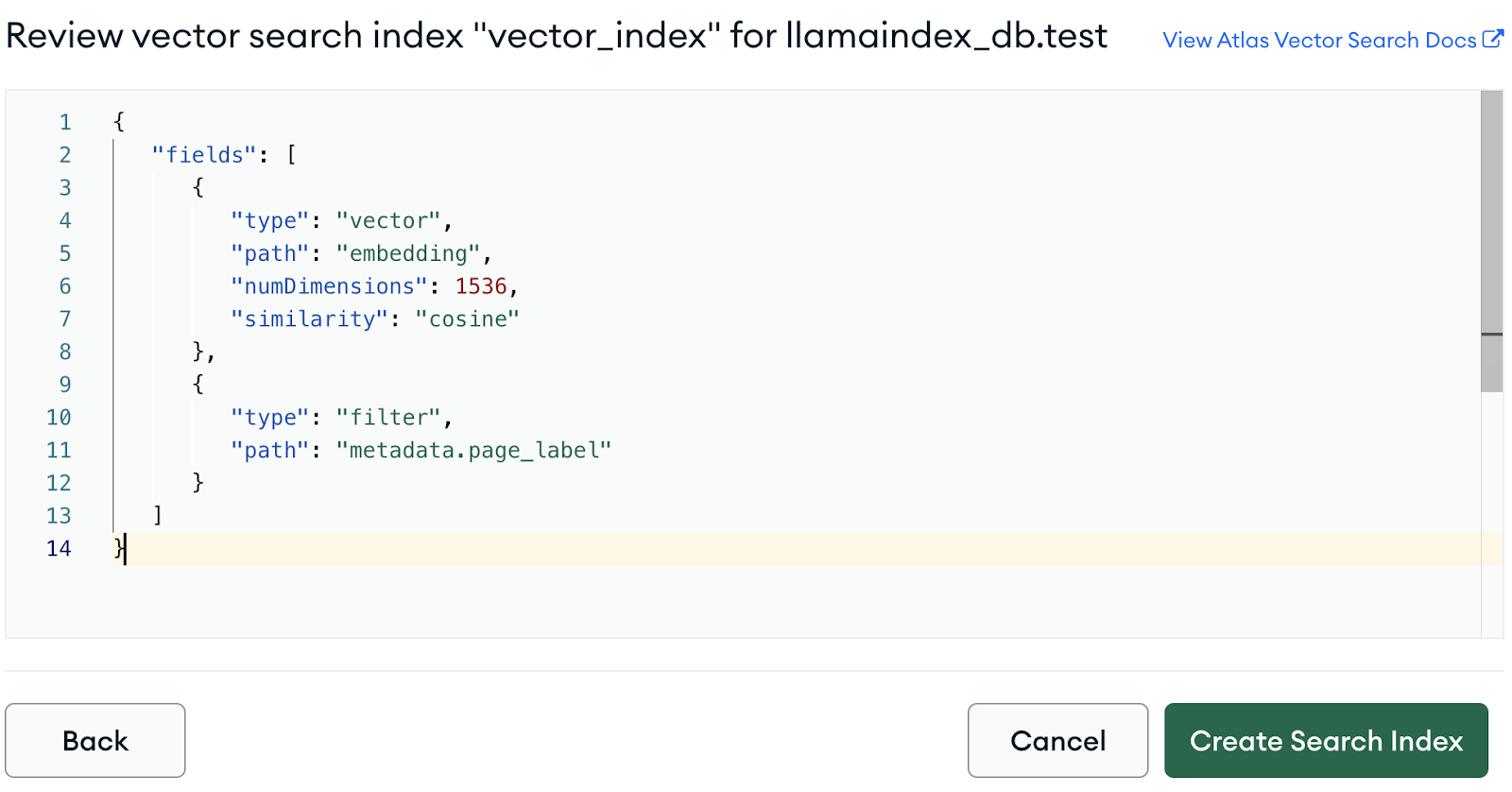
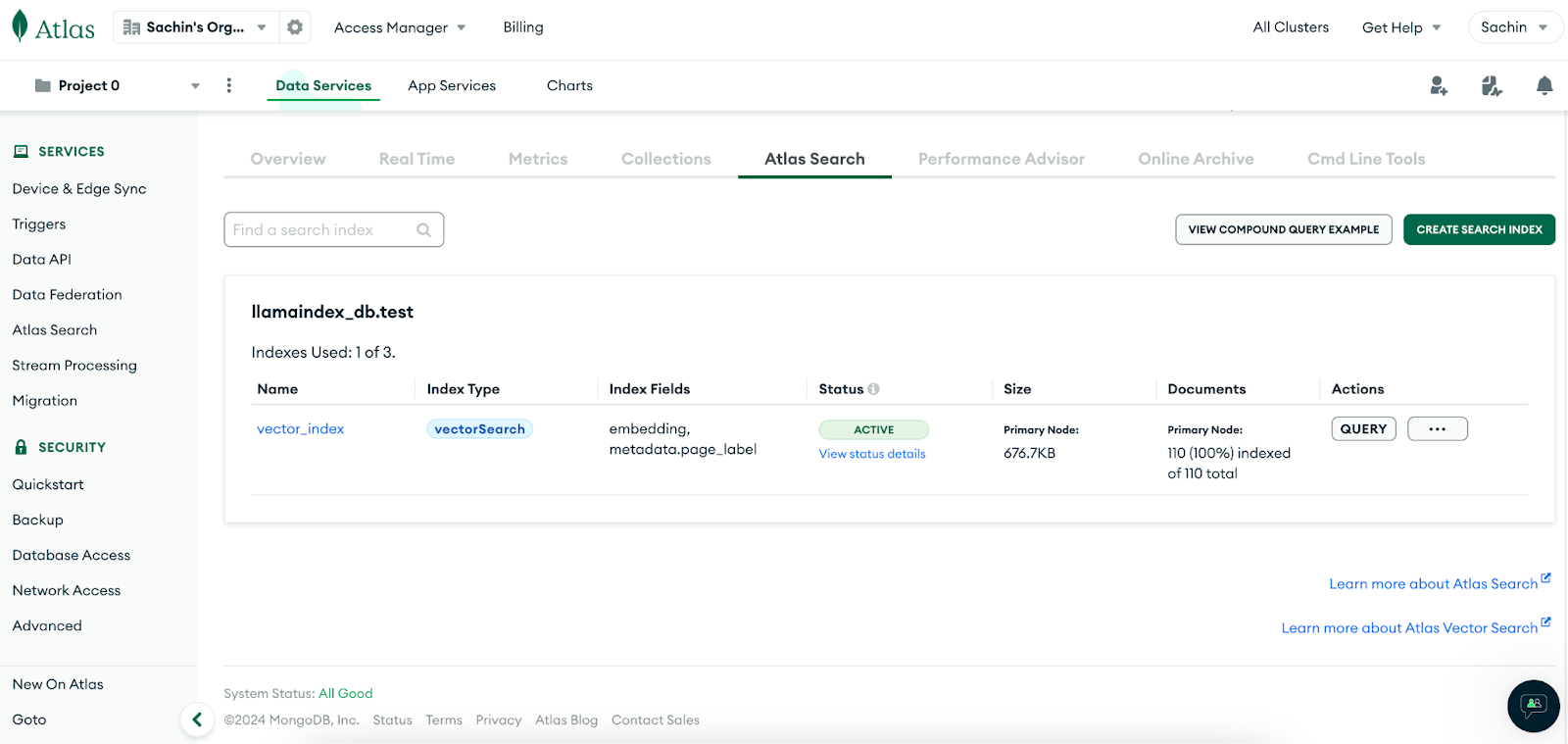
We can see that the vector index is created. Let’s implement RAG and check if vector search is working properly.
Step 8: Implementing RAG over the vector index using vector search
vector_store_retriever = VectorIndexRetriever(index = vector_store_index, similarity_top_k = 2)
query_engine = RetrieverQueryEngine(retriever = vector_store_retriever)
response = query_engine.query('What is WaitGPT?')
print(response)
print("\nSource documents: ")
pprint.pprint(response.source_nodes)Output:
Step 9: We can enhance the entire operation using a ChatEngine for back-and-forth communication as well
chat_engine = vector_store_index.as_chat_engine(
chat_mode="condense_question", streaming=True
)
response_stream = chat_engine.stream_chat("What are the benefits of WaitGPT")
response_stream.print_response_stream()Output:
WaitGPT facilitates monitoring and steering of data analysis performed by LLMs, enabling users to enhance error detection and increase their overall confidence in the results. Additionally, WaitGPT empowers users to monitor and steer data analysis performed by LLM agents, enhancing error detection rate and improving overall confidence in the results.
response_stream = chat_engine.stream_chat("How is WaitGPT able to enhance LLMs?")
response_stream.print_response_stream()Output:
WaitGPT facilitates monitoring and steering of data analysis performed by LLMs by translating stream-based code into a growing visualization of key data operations, allowing for granular interactions. This approach empowers users to actively monitor and steer the data analysis process, leading to enhanced error detection rates and increased overall confidence in the results.
Step 10: Similarity search can also be implemented on the vector index
retriever = vector_store_index.as_retriever(similarity_top_k=2)
nodes = retriever.retrieve("How does WaitGPT addresses reliability issues and user challenge in LLM apps?")
for node in nodes:
print(node)Output:
Node ID: 640da0ef-c300-4876-af75-bf2e5c90af43
Text: By translating stream-based code into a growing visualization of the key data operations and affording granular interactions, WaitGPT empowers users to monitor and steer data analysis performed by LLM agents. A user study (N=12) covering basic data analysis tasks demonstrated that WaitGPT could enhance error detection rate and improve overall co…
Score: 0.926
Node ID: a1d10be9-fd5e-41e2-a25f-8171f77c7087
Text: Publication rights licensed to ACM. This is the author’s version of the work. It is posted here for your personal use. Not for redistribution. The definitive Version of Record was published in The 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24), October 13–16, 2024, Pittsburgh, PA, USA…
Score: 0.926
MongoDB’s Atlas Vector Search provides a comprehensive platform from implementing vector search, combining the strengths of a robust document database with advanced search capabilities. Its integration and support for various LLMs and framework makes it a versatile choice for building intelligent applications and agents.





![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

