
Nvidia released the Nemotron-4 340B family of models for synthetic data generation, which includes base, reward and instruct models. These models are open-access under the Nvidia Open Model Licence Agreement and can be downloaded and used from the Hugging Face model repository. The Nemotron-4 340B model family is designed to work together and address the key challenges in LLM training. This article explores the Nemotron-4 340B family of models in detail.
Recent innovations and research in the area of large language models are more focused on increasing the model accuracy based on pretraining on more, higher-quality tokens. The Nemotron-4 340B base model was trained with 9 trillion tokens from high-quality diverse data comprising English text, multilingual data and coding languages. The model used a breakdown of 70% English language, 15% multilingual and 15% coding data.
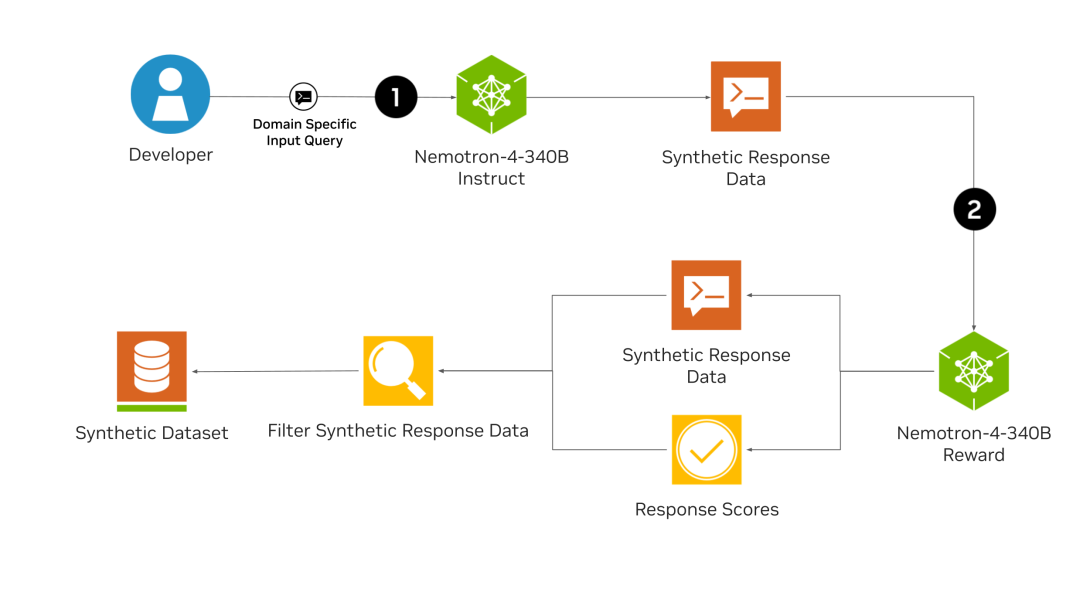
The Nemotron-4 340B model is aligned with the supervised fine-tuning followed by preference fine-tuning based on Reinforcement Learning with Human Feedback and Direct Preference Optimization which allows the model to engage in conversations more effectively and solve problems with a high degree of accuracy. The alignment process is dependent on a reward model that can accurately predict the response quality and is a useful tool in quality filtering and preference ranking in synthetic data generation.
The Nemotron-4 340B Instruct model surpasses the Llama-3 70B Instruct, Mixtral-8x22B Instruct and Qwen-2 72B Instruct models in terms of the instruction following and chat capabilities.
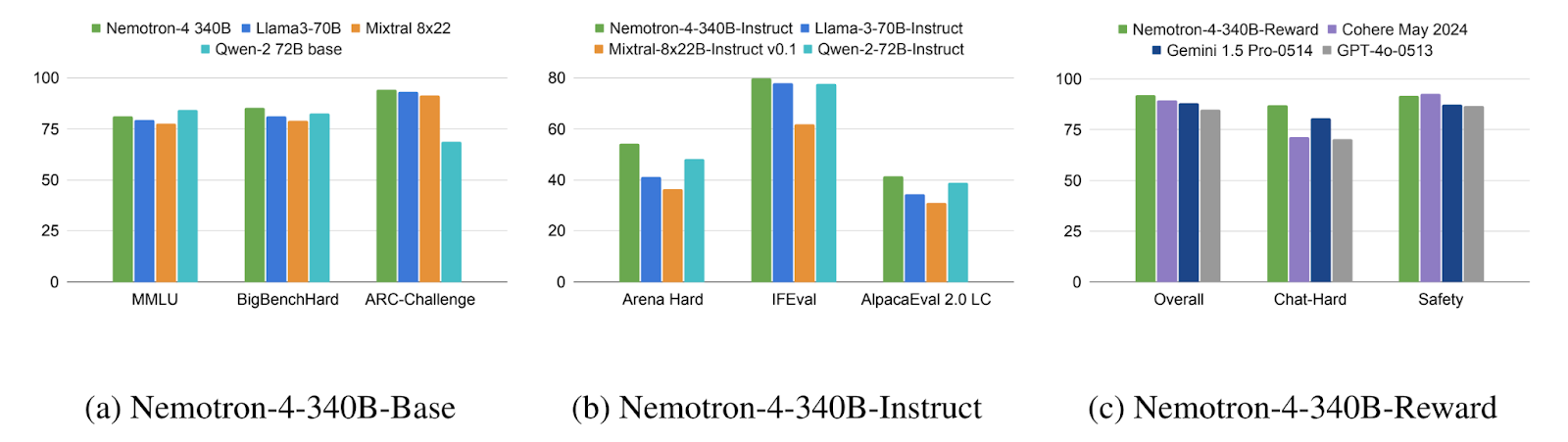
Nemotron-4 340 B Model Variant Comparison
Nemotron-4 340B Reward model achieves top accuracy on the RewardBench benchmark surpassing proprietary models such as GPT-4o-0513 and Gemini-1.5-Pro-0514.
The most important application of Nemotron models is synthetic data generation which improves data quality for pretraining significantly. The Nemotron-4-340B Instruct model has been created using over 98% of synthetically generated training data through an alignment process. Nvidia has also released the synthetic data generation pipeline that includes synthetic prompt generation, response and dialog generation, quality filtering and preference ranking. This pipeline has been created to support both supervised and preference fine-tuning processes.
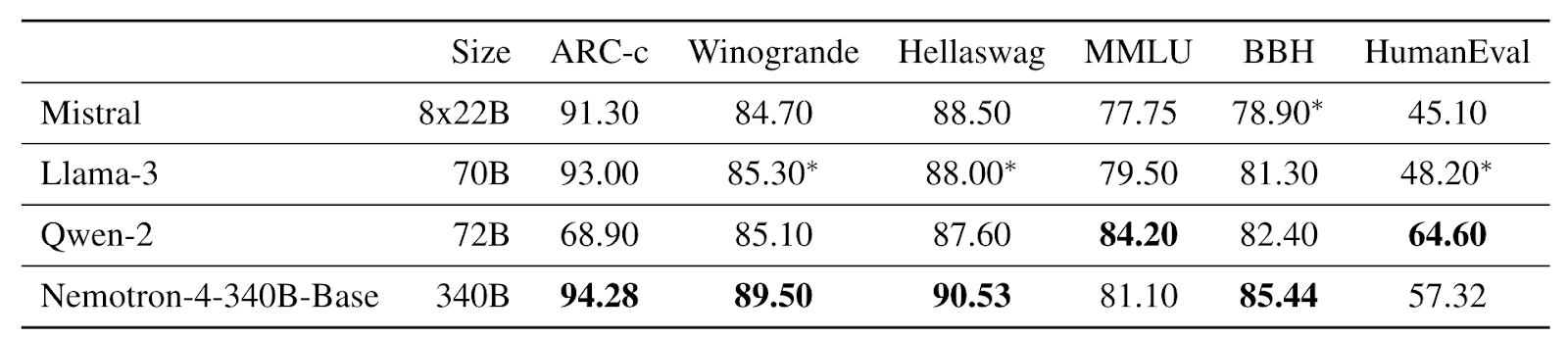
The Nemotron-4 340B Base model is similar to the architecture of Nemotron-4 15B which uses a standard decoder-only Transformer architecture with causal attention masks, Rotary position Embeddings, SentencePiece Tokenizer and squared ReLU activations for MLP layers. The model has 9.4 billion embedding parameters and 331.6 billion non-embedding parameters.
The base model was trained on 768 DGX H100 nodes, where each node contains 8 H100 80GB SXM5 GPUs based on Nvidia Hopper. Each H100 GPU has a peak throughput of 989 teraflops/s when performing 16-bit FP arithmetic without sparcity. Within each node, GPUs are connected by NVLink and NVSwitch. The GPU-to-GPU bandwidth is 900 GB/s.
The LM-Evaluation Harness is used to evaluate the Nemotron-4 340B across the tasks depending on MMLU, BBH, ARC Challenge, Winograde, Hellaswag and HumanEval as shown in the image below:
The reward model is developed using 10k human preference data, called HelpSteer2. This model is a necessary component in model alignment as it is used for preference ranking and quality filtering in the training of a strong instruction-following model. The Nemotron-4 340B reward model achieves the top accuracy on Reward Bench’s primary dataset as compared to Cohere, Gemini-1.5 Pro, GPT-4-0125, GPT-4-0513 and Claude-3-Opus models.
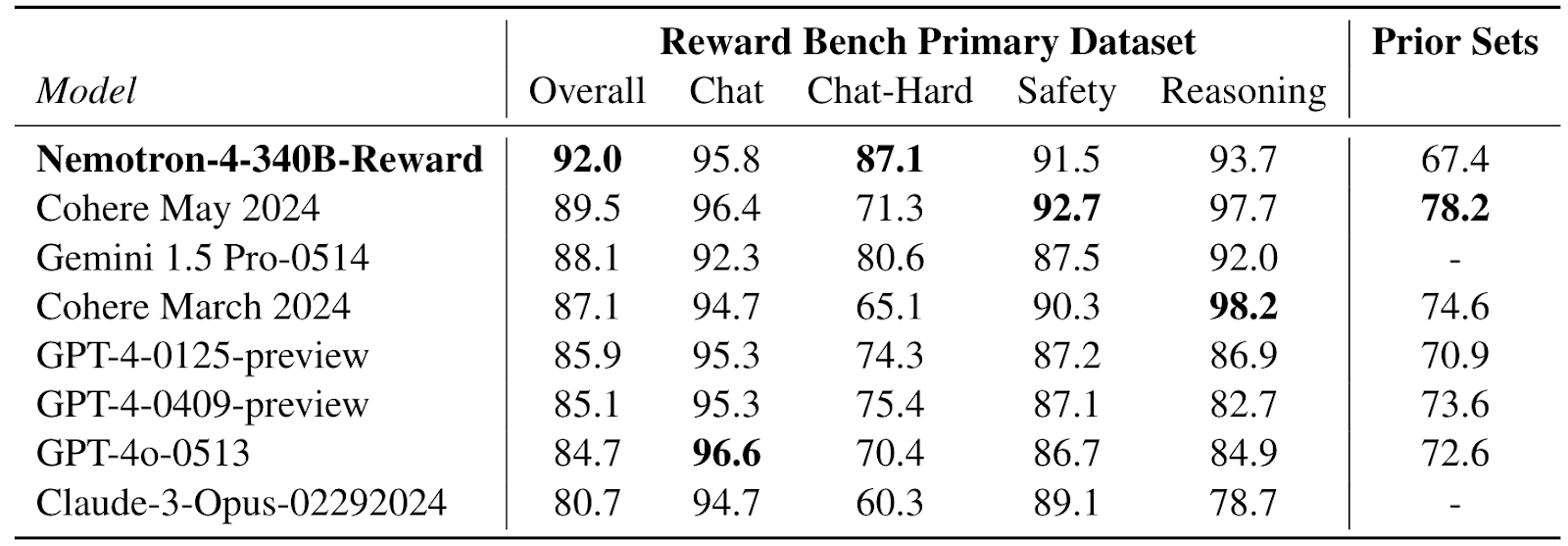
Model Accuracy on Reward Bench
The model only relies on 20k human-annotated data (10k for supervised fine-tuning and 10k HelpSteer2 data) for reward model training and preference fine-tuning. The data generation pipeline synthesised over 98% of the data used for supervised fine-tuning and preference fine-tuning.
The Nemotron-4 340 B Instruct model is competitive when compared against both open-sourced and closed-source models. The tasks based on which the evaluations were done are single-turn conversation (AlpacaEval), multi-turn conversation (MT-Bench), aggregated benchmark (MMLU), GSM8k for Math, HumanEval for Code, IFEval for instruction following and TFEval for topic following.
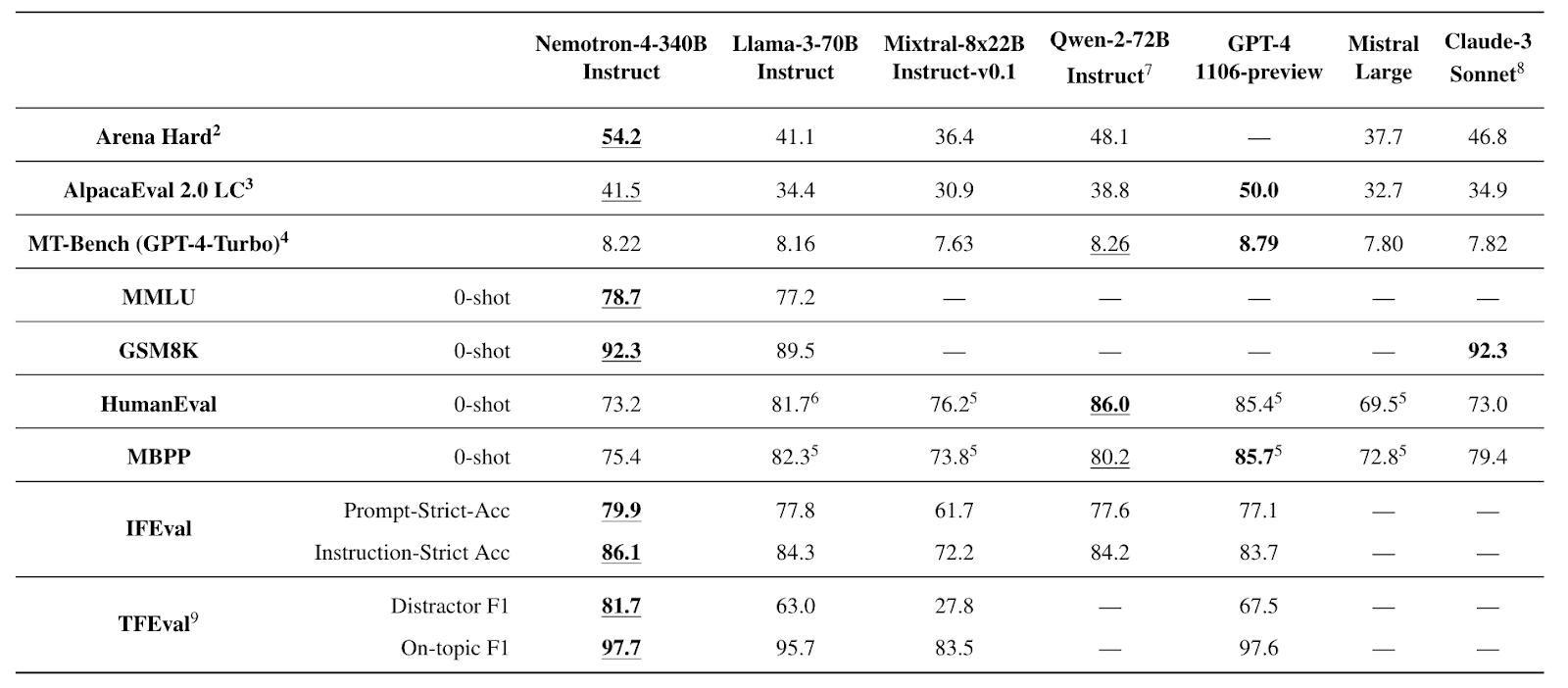
Instruct Model Evaluation Results
The Nemotron-4 340B family of models are a new addition to the ongoing research in overcoming data scarcity challenges when it comes to LLM training. The LLMs require a huge amount of data for training which can be hard & expensive to acquire, or, limited in scope and biased. These challenges can be addressed using Nemotron by generating high-quality synthetic data, allowing researchers and developers to train custom LLMs even when real-world data is scarce. The Nemotron family is designed to operate seamlessly with Nvidia’s NeMo framework and TensorRT-LLM library increasing the training efficiency and deployment as well alongside a higher degree of accessibility.





