
Google released EmbeddingGemma on September 4, 2025, a new open-source 308M parameter embedding model. It is capable of delivering best-in-class performance based on its size. This model is specifically engineered for on-device AI. It empowers users to develop applications with ease and efficiency using methods like Retrieval Augmented Generation and semantic search. Based on the Gemma 3 architecture, it was trained on over 100 languages. With quantization, the model is optimized for use on everyday devices, such as phones, tablets, and laptops. It is small enough to run on less than 200MB of RAM. This article explores EmbeddingGemma practically based embedding generating and similarity searching.
Text embeddings are crucial in modern language models. Machines use them as the fundamental method to understand and process human language. Instead of treating words as discrete, isolated units, text embeddings transform them into dense numerical vectors. These vectors capture their semantic meaning and relationships. Consequently, this allows language models to perform complex tasks that require a more refined understanding of language.
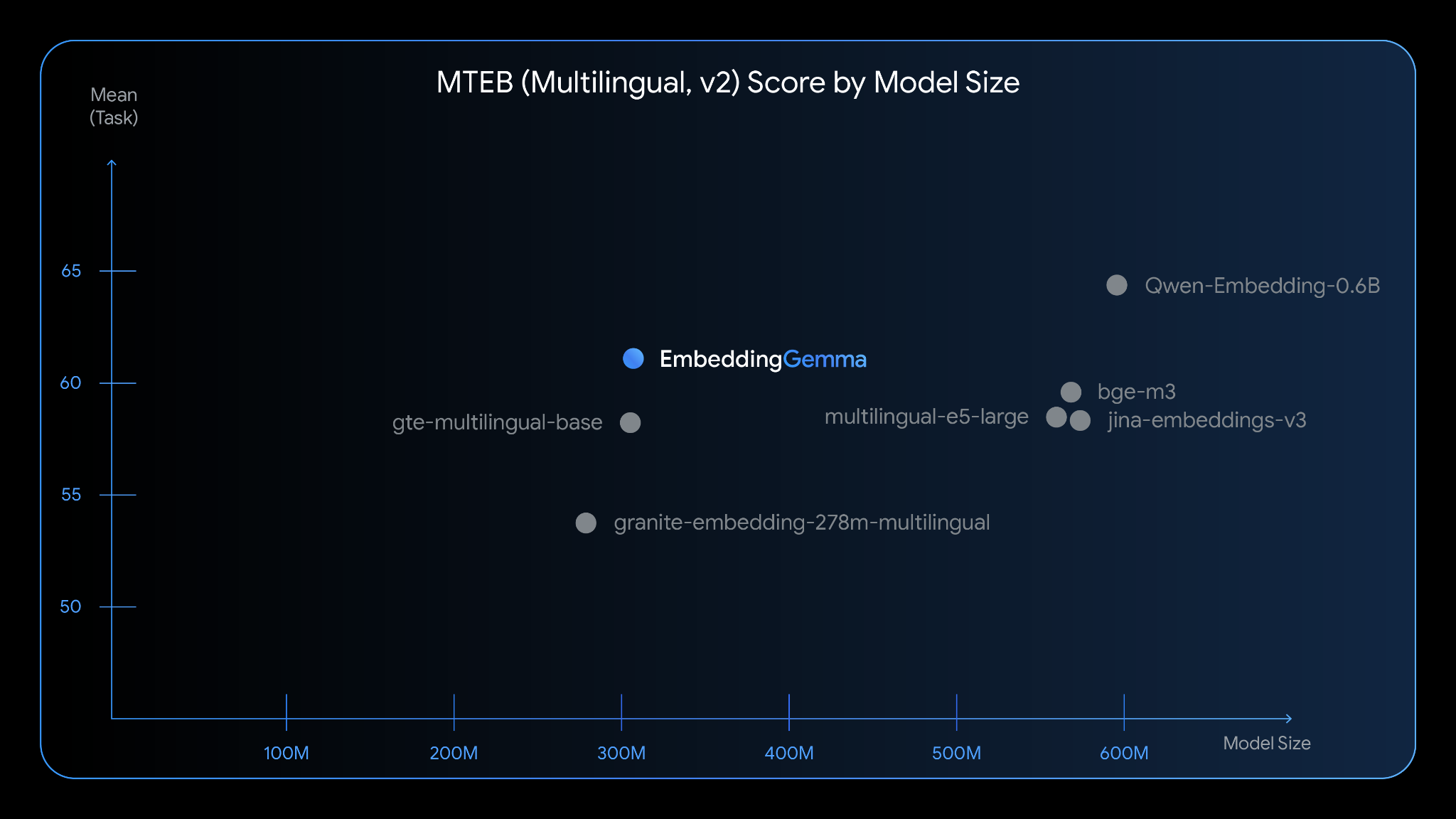
Google DeepMind’s new text embedding model, termed EmbeddingGemma, is a new 308M parameter model. In addition, it has a 2k-token context window and supports over 100 languages. Furthermore, it is capable of delivering SOTA performance on the Massive Text Embedding Benchmark (MTEB). Remarkably, the model uses just 200MB of RAM when quantized.
MTEB Performance – EmbeddingGemma
Google built EmbeddingGemma on a Gemma 3-based encoder backbone with mean pooling. This means it uses a transformer architecture specifically adapted for the task of creating dense, semantic embeddings. Google applied the same research and technology used to create Gemini models. It distinguishes itself from other embedding models with a few key features. Google specifically designed these features for on-device and resource-constrained environments.
JAX and ML Pathways were utilized in training the model. First, JAX is a Python library designed for high-performance numerical computing and machine learning research. Furthermore, the power of JAX comes from its ability to automatically transform functions, which is important for machine learning. Specifically, JAX uses Just-in-time (JIT) compilation to optimize Python code for specific hardware, thereby making computations exponentially faster. In essence, it traces the code’s operation and compiles it into highly efficient, device-specific executables.
ML Pathways on the other hand, is Google’s next gen AI architecture. It is designed to enable a single AI system to perform multiple tasks and understand various data modalities with remarkable efficiency. While a typical machine learning model is trained for a single purpose, Pathways aims for a more general-purpose system. It can handle different tasks and data types simultaneously. It provides a single controller programming model which allows a single Python process to orchestrate the entire training run of a massive model across thousands of TPU chips. This simplifies development and training workflow for models that are large for a single machine.
The synergy of JAX and ML Pathways is the key to how Google trains its most advanced models, including EmbeddingGemma. Jax provides a composable and high-performance numerical computation framework. Meanwhile, Pathways provides orchestration and distributed systems framework to handle the immense scale of the training process. Together, they are able to create a powerful and efficient workflow that simplifies the development of complex, large-scale AI models. This synergy allowed Google to train the EmbeddingGemma on over 100 languages on the latest generation of TPUs. This feat would be incredibly difficult without these specialized tools.
Matryoshka Representation Learning (MRL) is a key feature of EmbeddingGemma that allows it to generate embeddings of different sizes from a single model. This is a crucial innovation for on-device AI because it provides a flexible trade-off between model accuracy and resource efficiency.
The concept is similar to a set of nested Matryoshka dolls. A single, large doll contains a smaller doll inside it, which contains an even smaller one, and so on. In the same way, the full 768-dimensional embedding from EmbeddingGemma contains smaller, still-useful embeddings within it. During the training process, the model is taught not only to create a high-quality 768-dimensional embedding but also to ensure that the initial segments of this vector (e.g., the first 512, 256, or 128 dimensions) are also semantically rich and meaningful. This is achieved by adding a loss function during training that encourages these shorter vectors to perform well on tasks like semantic similarity and retrieval.
This innovative technique allows developers to truncate the output embedding vector from its full 768 dimensions down to smaller sizes. For instance, these smaller sizes can be 512, 256, or even 128, all without needing to retrain the model. Consequently, this provides a customizable trade-off between retrieval accuracy and resource efficiency (memory and storage). In other words, a smaller embedding size requires less storage space and can be processed faster, ultimately making it highly valuable for mobile devices.
The model’s training process incorporates Quantization Aware Training (QAT), which reduces the precision of the numerical representations within the model. For example, from 32-bit to 8-bit integers. This lowers the memory footprint. As a result, the model can run on less than 200MB of RAM, making it feasible for devices with limited resources.
QAT also enables an increased processing speed by using low-precision arithmetic which is much faster for a device’s processor (CPU or specialized hardware like a Neural Processing Unit). It enables the model to leverage this hardware efficiency, leading to faster inference times and a more responsive user experience.
Unlike a simple post-training quantization, QAT trains the model to be robust to the precision loss from the start. By simulating the quantization process during training, EmbeddingGemma learns to compensate for the rounding errors, ensuring that its high-quality embedding performance is preserved even after the model is fully quantized. This means the model maintains its accuracy on tasks like semantic search and Retrieval-Augmented Generation (RAG).
Despite its compact size of 308M parameters, EmbeddingGemma ranks as a top-performing multilingual text embedding model under 500M parameters. It ranks on benchmarks like MMTEB & MTEB, rivaling models that are nearly twice its size. It is also trained on over 100 languages, making it versatile and capable of generating high-quality embeddings for a wide range of global applications.
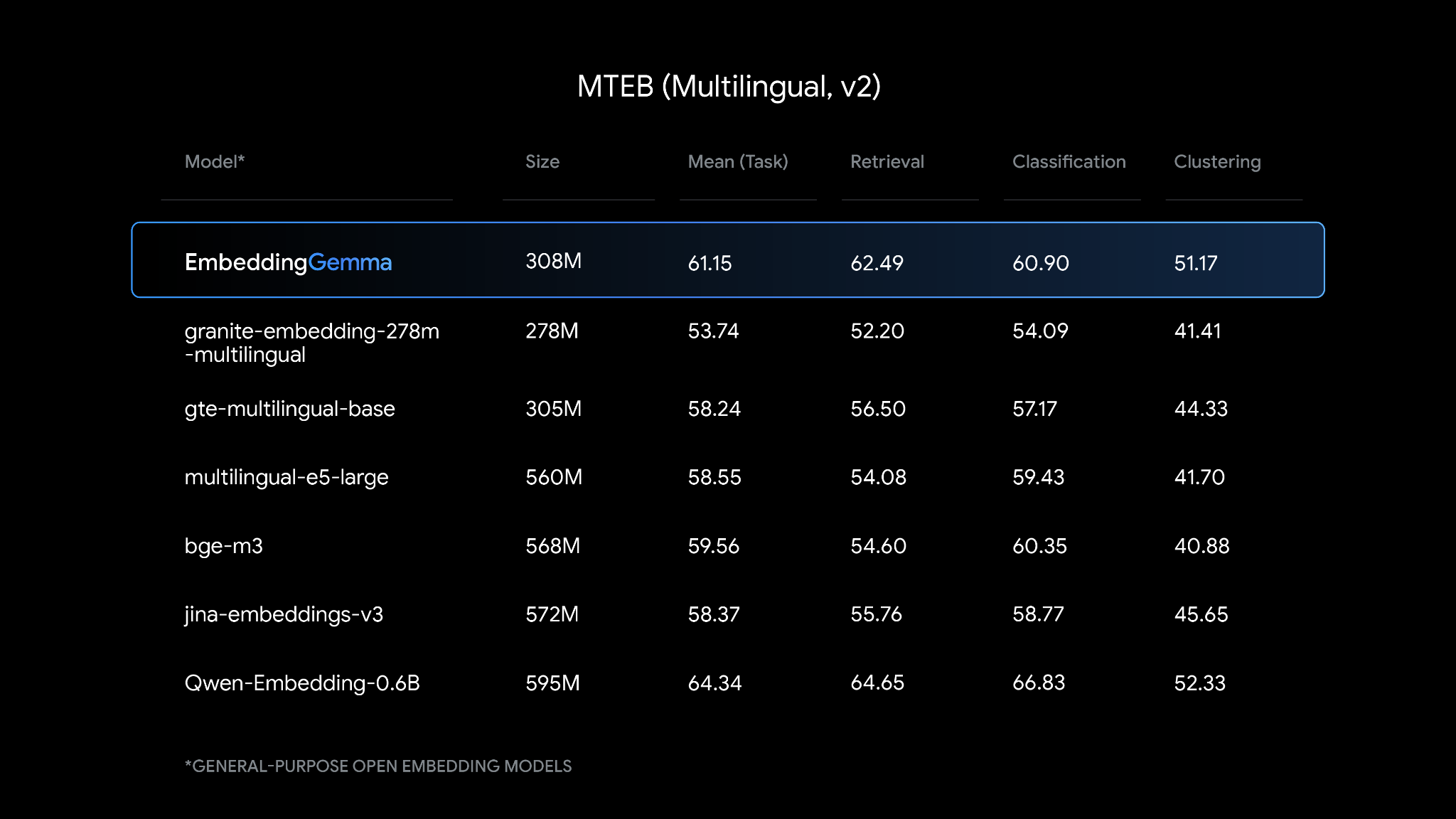
EmbeddingGemma MTEB (Multilingual, v2) Benchmarks
EmbeddingGemma’s model weights are available on HuggingFace, Kaggle, and VertexAI. It seamlessly integrates with on-device tools such as transformers.js, MLX, llama.cpp, LiteRT, Ollama, LMStudio, etc.
Interactive Demo of EmbeddingGemma
Let’s implement a simple similarity finder using EmbeddingGemma model.
%pip install git+https://github.com/huggingface/transformers@v4.56.0-Embedding-Gemma-preview -q
%pip install sentence-transformers>=5.0.0 -qfrom google.colab import userdata
import os
os.environ["HUGGINGFACE_TOKEN"] = userdata.get('HF_TOKEN')import torch
from sentence_transformers import SentenceTransformer
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "google/embeddinggemma-300M"
model = SentenceTransformer(model_id).to(device=device)
print(f"Device: {model.device}")
print(model)
print("Total number of parameters in the model:", sum([p.numel() for _, p in model.named_parameters()]))words = ["Google", "Meta", "OpenAI", "Anthropic", "Nvidia"]
embeddings = model.encode(words)
print(embeddings)
for idx, embedding in enumerate(embeddings):
print(f"Embedding {idx+1} (shape): {embedding.shape}")# Encoding the sentences for determining the degree of similarity
low_similarity = [
"An Agentic AI system can plan and execute its own tasks.",
"LLMs have made chatbots more conversational."
]
medium_similarity = [
"Fine-tuning an LLM improves its performance on specific tasks.",
"RAG is an alternative to improve LLM performance."
]
high_similarity = [
"Generative AI creates new content.",
"Generative AI can be used to create new text, images, audio, or video."
]
i = 1
for sentence in [low_similarity, medium_similarity, high_similarity]:
print("Sentence pair: ", i)
print(sentence)
embeddings = model.encode(sentence)
similarities = model.similarity(embeddings[0], embeddings[1])
print("`-> score: ", similarities.numpy()[0][0])
i = i + 1
print("\n")
We can clearly see that the results are in-line with the statement pairs that we used.
EmbeddingGemma’s innovation, from its efficient architecture to its flexible Matryoshka Representation Learning, sets a new standard for what’s possible with small, open models. It proves that we don’t need a massive, cloud-dependent system to achieve SOTA performance. It’s an important step in terms of AI-based application development which is fast, efficient, and respects user privacy by design.




![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

