Large language models are difficult to understand due to their inner complexity which raises concerns about interpretability and accountability. CometLLM is a platform designed for explaining LLMs through the concept of prompt logging, tracking and visualization. It offers unique features such as experiment tracking, prompt management, output visualization which facilitate transparency, reproducibility, RAG analysis and optimization, prompt tuning and engineering with ease and efficiency. This article discusses CometLLM using a hands-on approach.
Explainability refers to the ability to present the behavior of models in human-understandable terms. Improving the explainability of LLMs is important primarily because it establishes trust by interpreting the reasoning behind the model predictions in an understandable manner, without requiring technical expertise. This enables the users to understand the capabilities, limitations, and potential issues in the LLM. It also enables the users to understand the model behavior providing insights towards identification of biases, risks and areas of performance improvements.
The scale of LLMs in terms of parameters and training data is far more complex than traditional machine learning or deep learning models. The difficulty in interpreting models increases based on the increase in their size. This also adds up to the computational complexity based on the computations required for generating explanations. The traditional approaches in explainable AI such as SHAP and LIME would require more computational power to explain such high-sized LLM. This makes such techniques less practical for real-world implementations.
As the models become large, the interpretation process also becomes difficult due to increased internal complexity and size of training data. This complexity also requires a huge amount of computational resources for generating explanations. Also, traditional approaches in Explainable AI such as SHAP would demand more computational power to explain LLMs composed of billions of parameters. This makes such techniques less practical for real-world implementations and applications.
The research paper titled “Explainability for LLMs: A Survey” published on 28th Nov’23 shows an overview of methods for interpreting LLMs. It introduces two paradigms – The traditional downstream methods for fine-tuned LLMs and the prompted LLMs as shown in the image below:
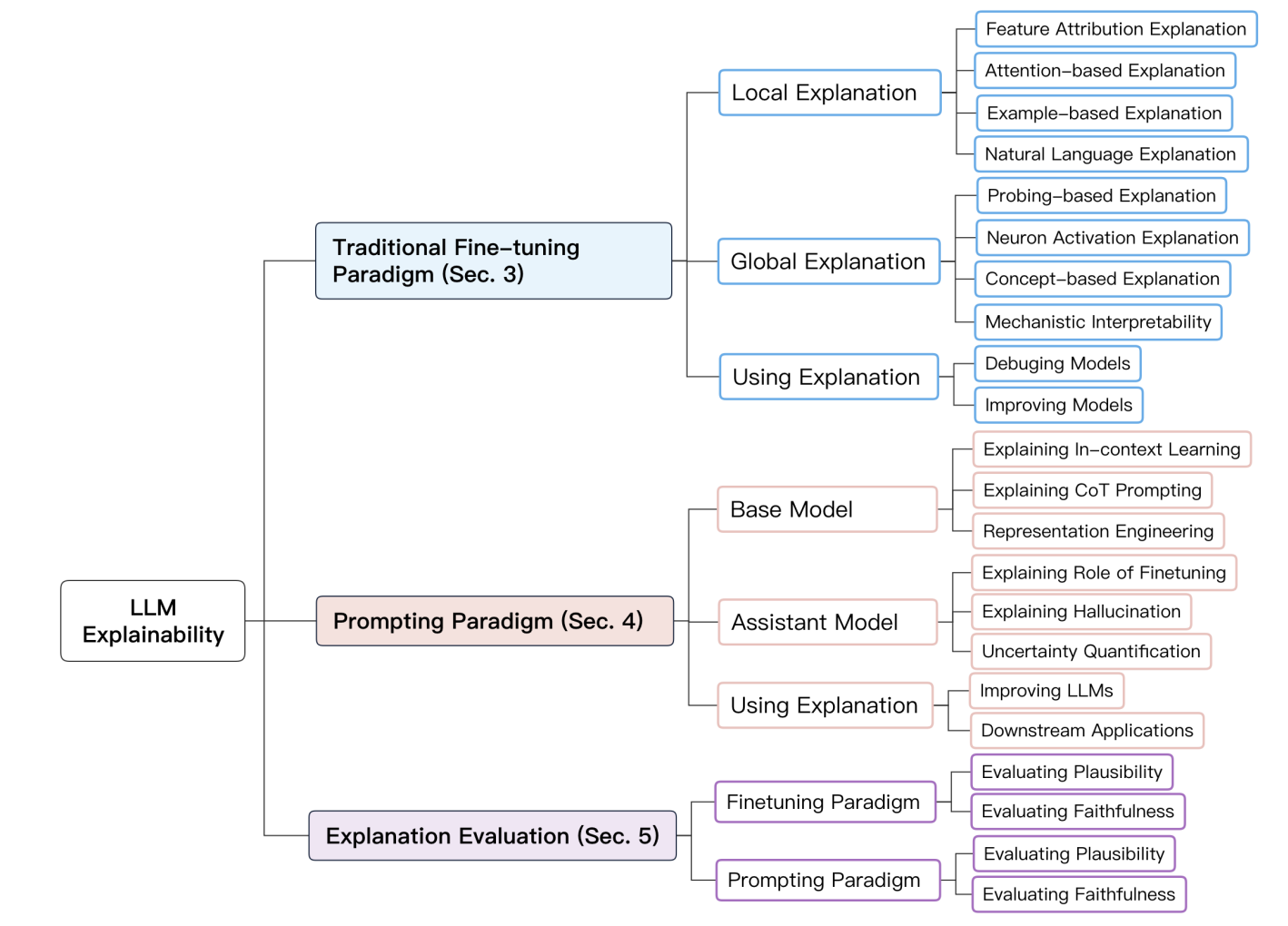
Explainability for LLMs: A Survey
The traditional fine-tuning paradigm is relevant to language models that are pre-trained on a large corpus of unlabeled text data and then fine-tuned on a set of labeled data from a specific downstream domain. The interpretations or explanations on this paradigm focuses on understanding how the self-supervised pre-training enables models to acquire a foundational understanding of language and analyzing how the fine-tuning process equips these pre-trained models with the capability to effectively solve downstream tasks.
The prompting paradigm on the other hand involves using prompts enabling zero-shot or few-shot learning without requiring additional training data. It incorporates two categories of models – base model and assistant model.

CometLLM is an open-source specialized tool that documents LLM usage and experimentation. It can be used to identify effective prompting strategies, enable appropriate troubleshooting and provide reproducible workflows. Developing an effective LLM application or agent involves a continuous refinement of the user prompts. CometLLM provides a streamlined way of tracking and management of these prompts built on the idea around LLM prompt engineering workflows.
CometLLM’s main functionality is to meticulously log every prompt and chain used during LLM inference, capturing essential metadata such as parameters, model details, timestamps and execution duration. This granularity in terms of detail is invaluable for understanding prompt performance and supports LLM engineers/users in identifying areas of improvement. The platform allows the users to enrich prompts with custom metadata, enabling deeper analysis and organization of experiments.
Another notable feature of CometLLM is visualization. Through intuitive charts and graphs, LLM users can effortlessly explore trends, patterns, and correlations within their prompt data. This visual representation facilitates a deeper understanding of prompt effectiveness and helps in identifying optimizing opportunities.
Integration of CometLLM with LLM frameworks and models such as OpenAI, Cohere, Hugging Face Transformers, LangChain further increases its usability and functionality in LLM application development and experimentation.
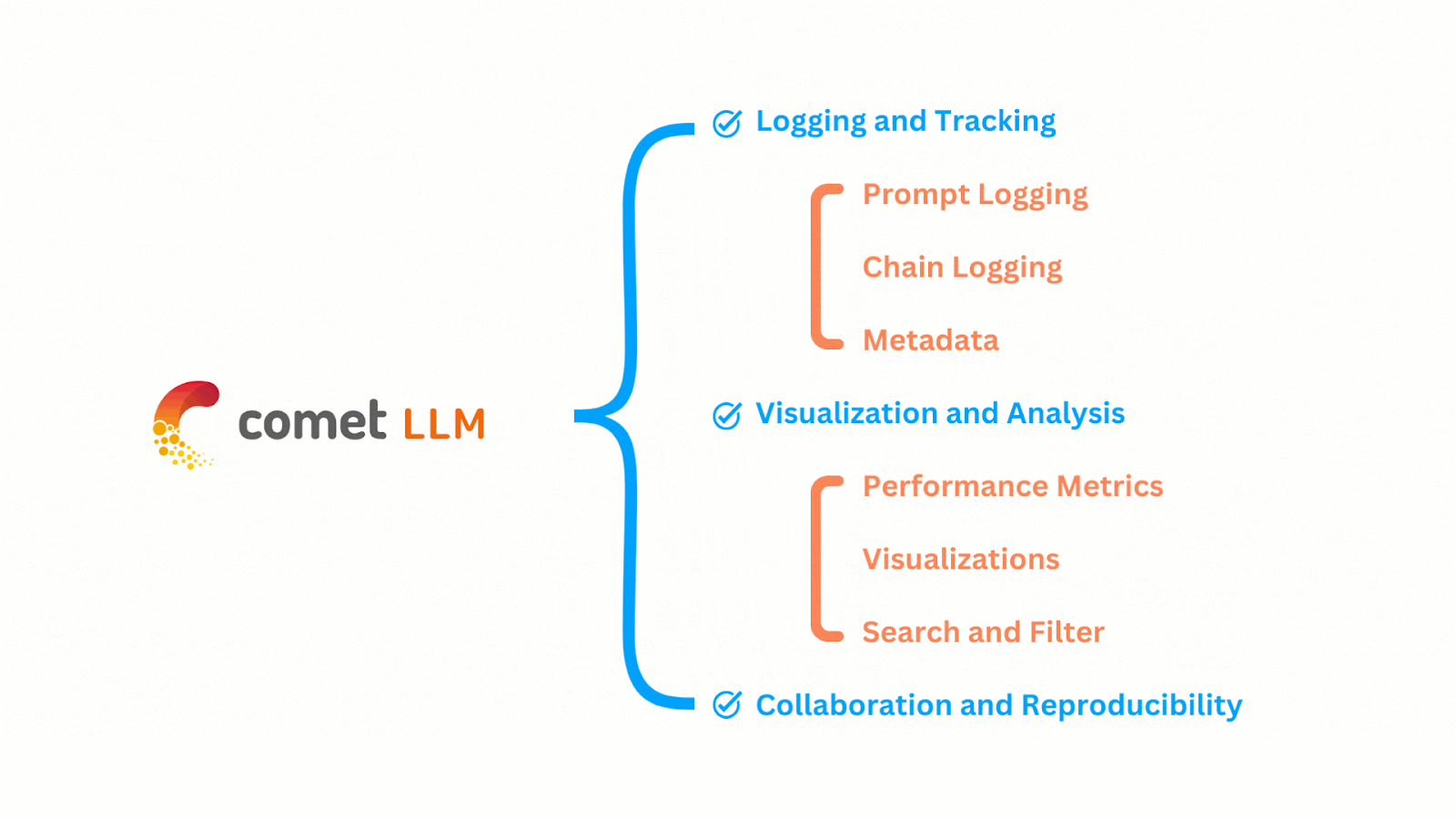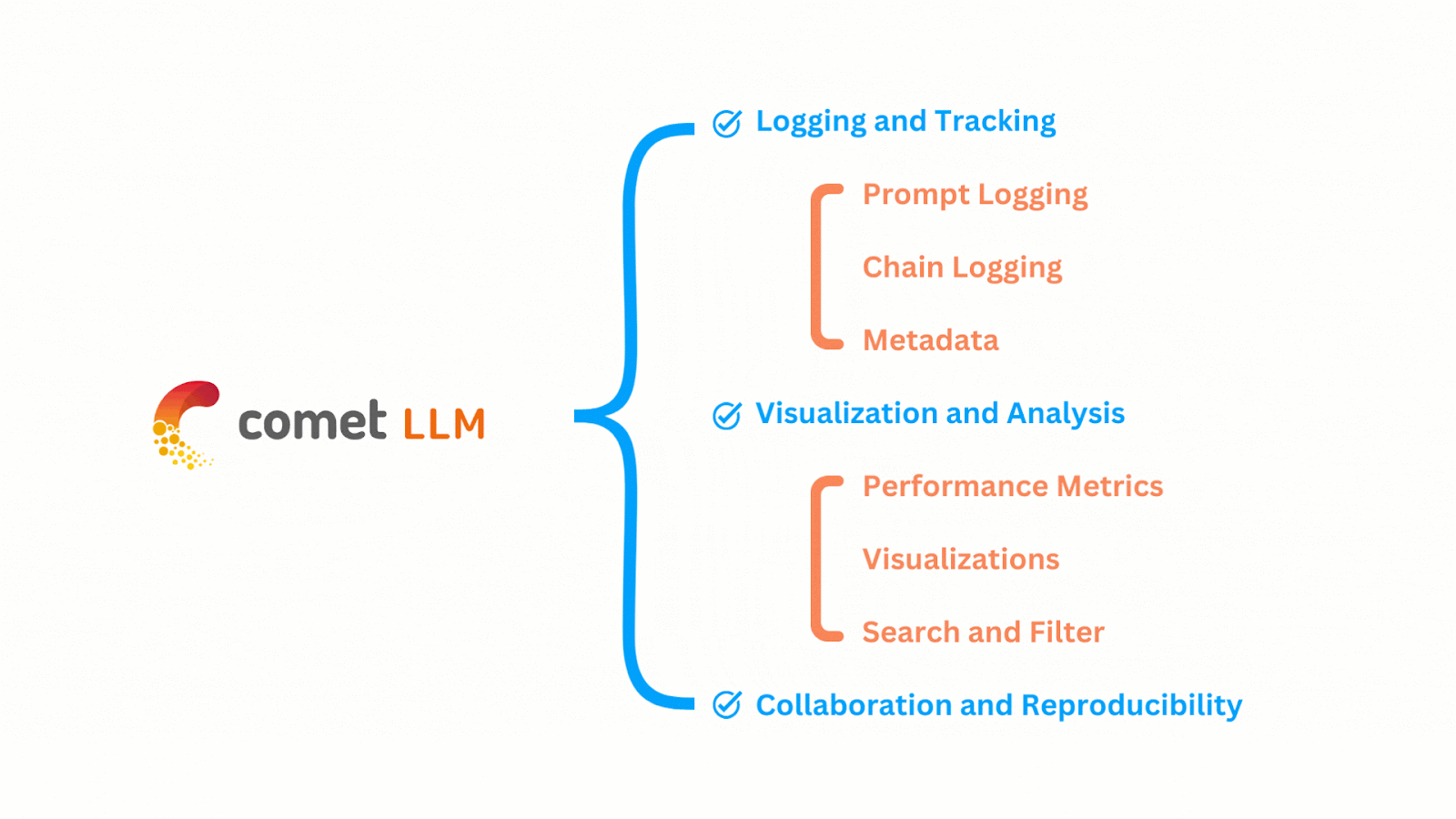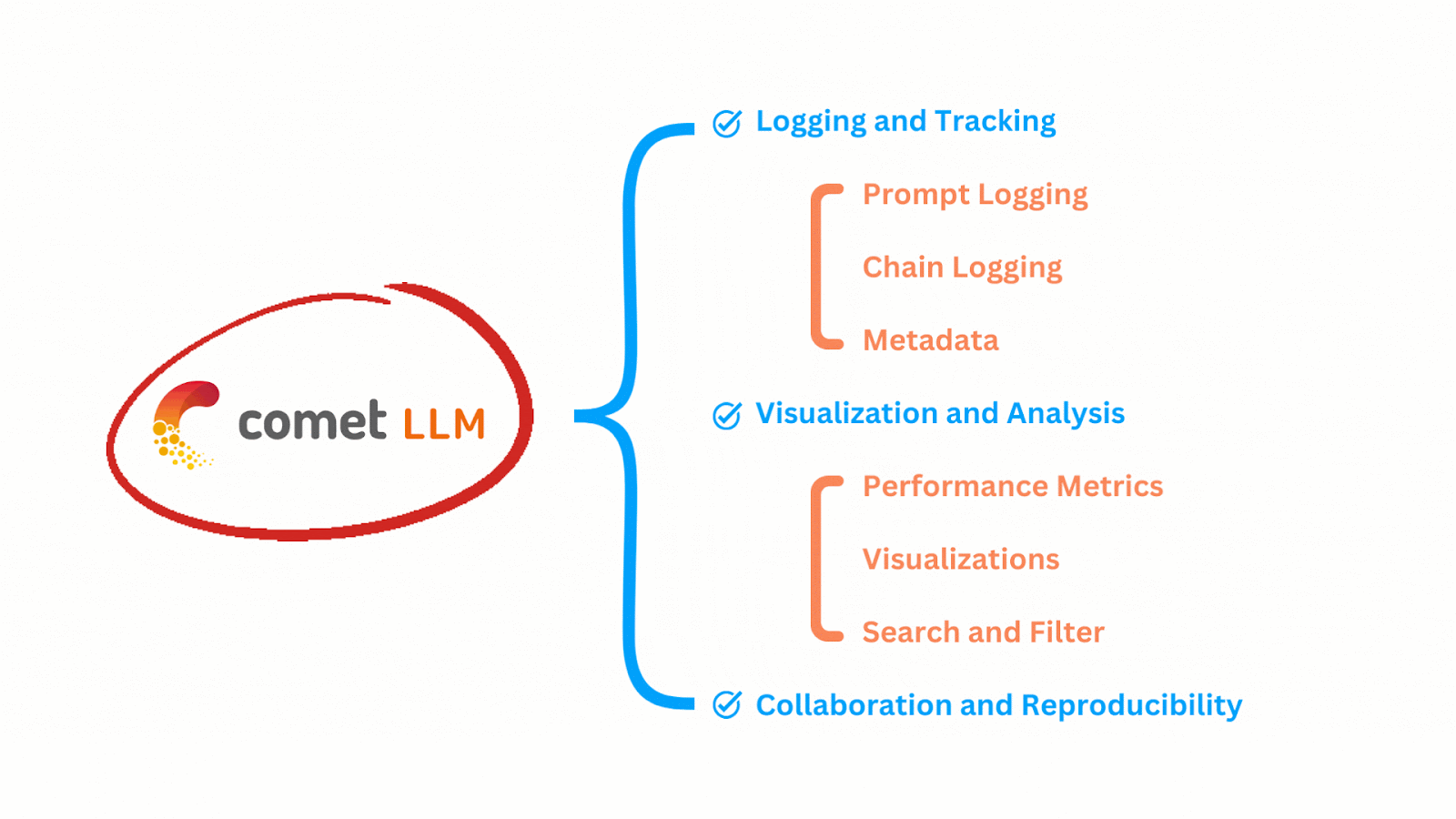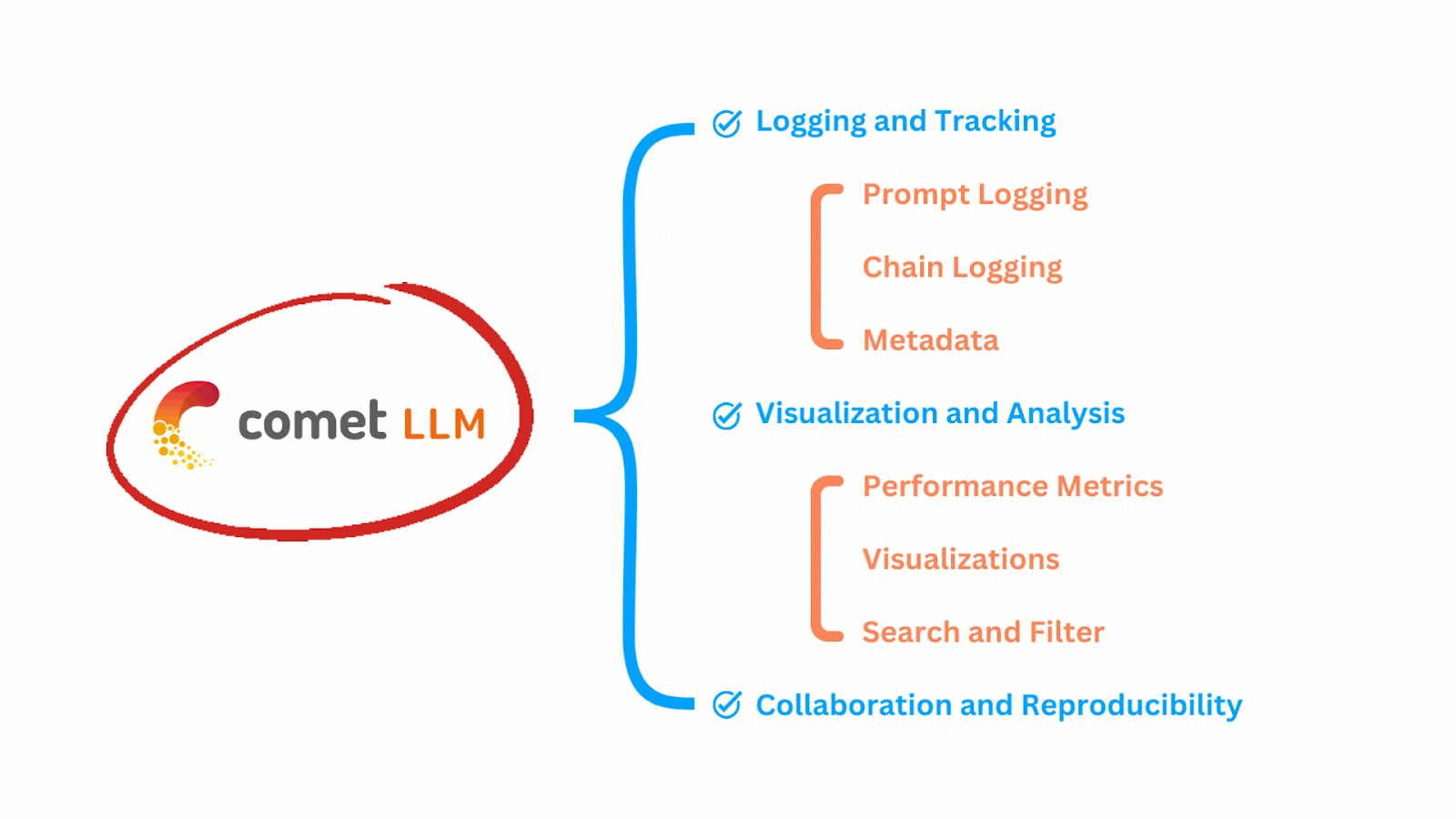
The functionalities of CometLLM can be easily understood by the image shown below:
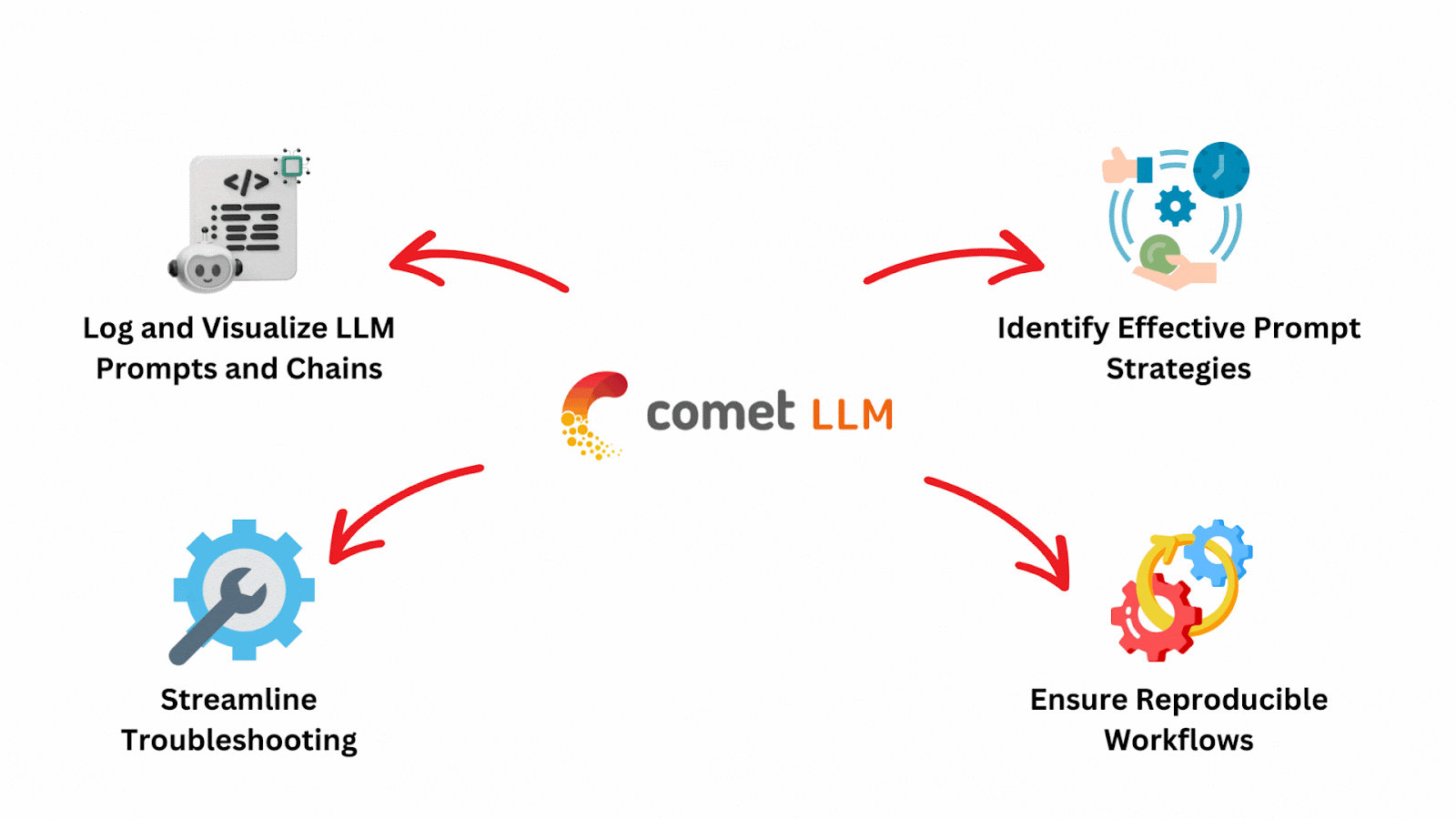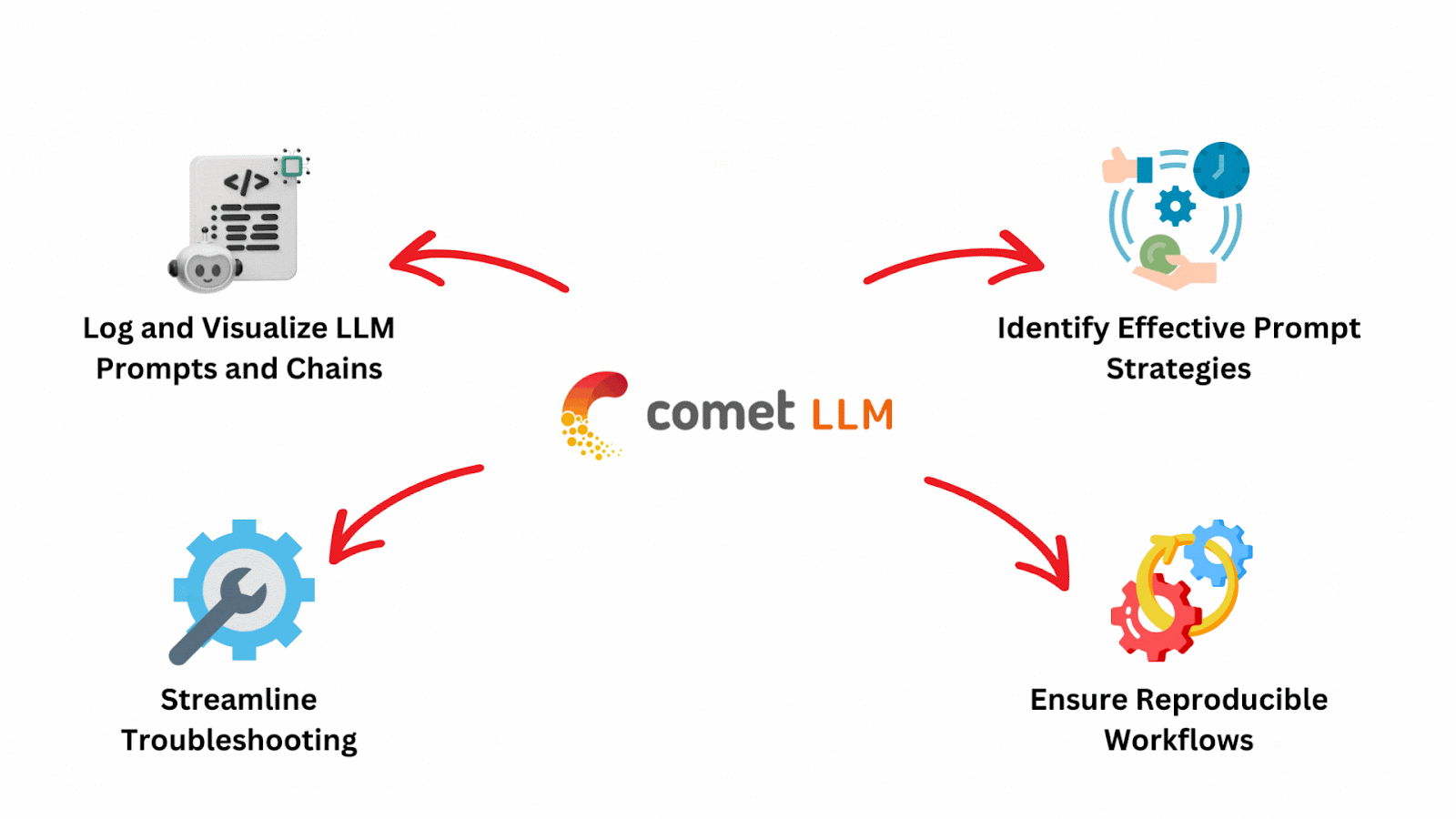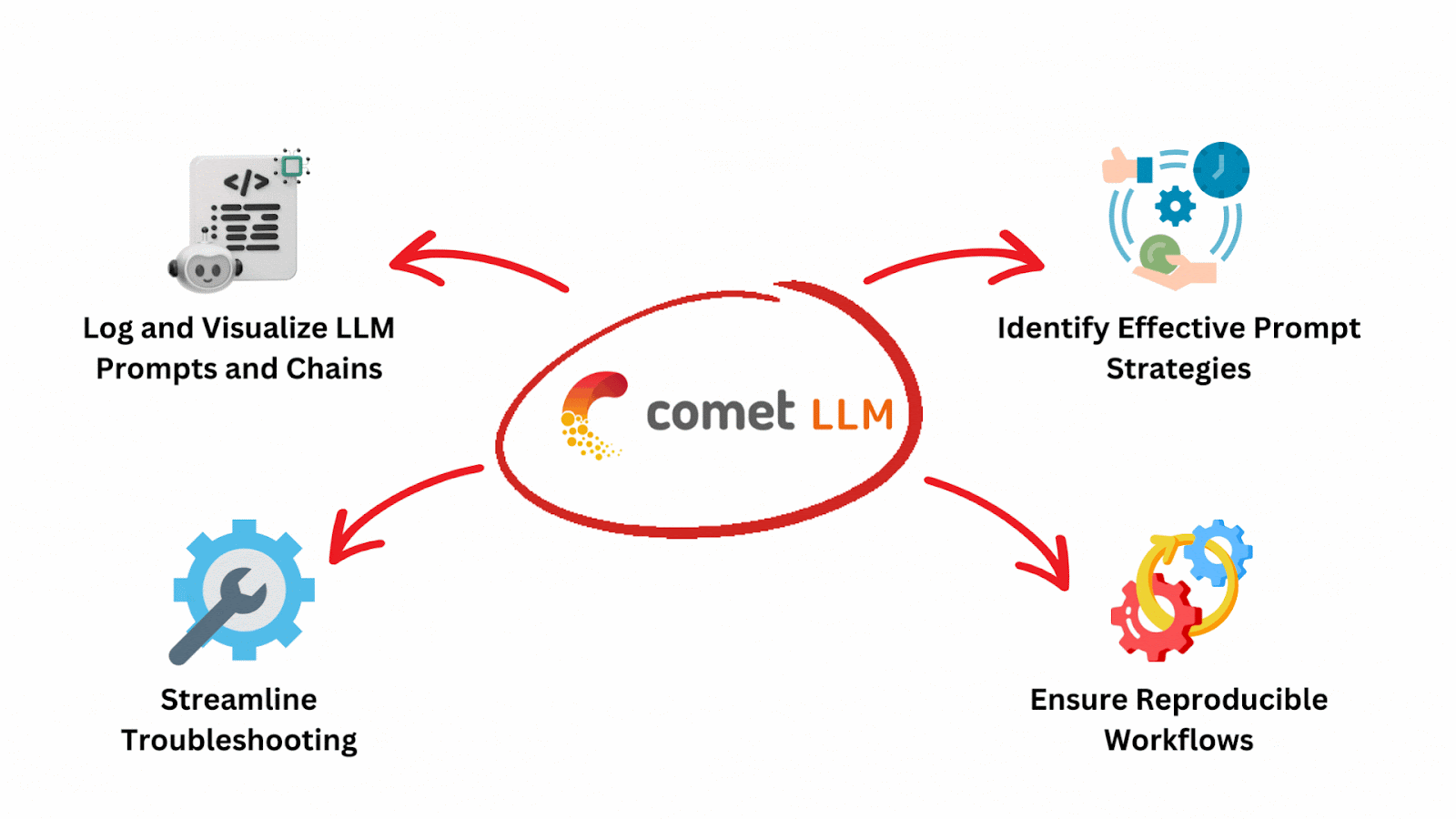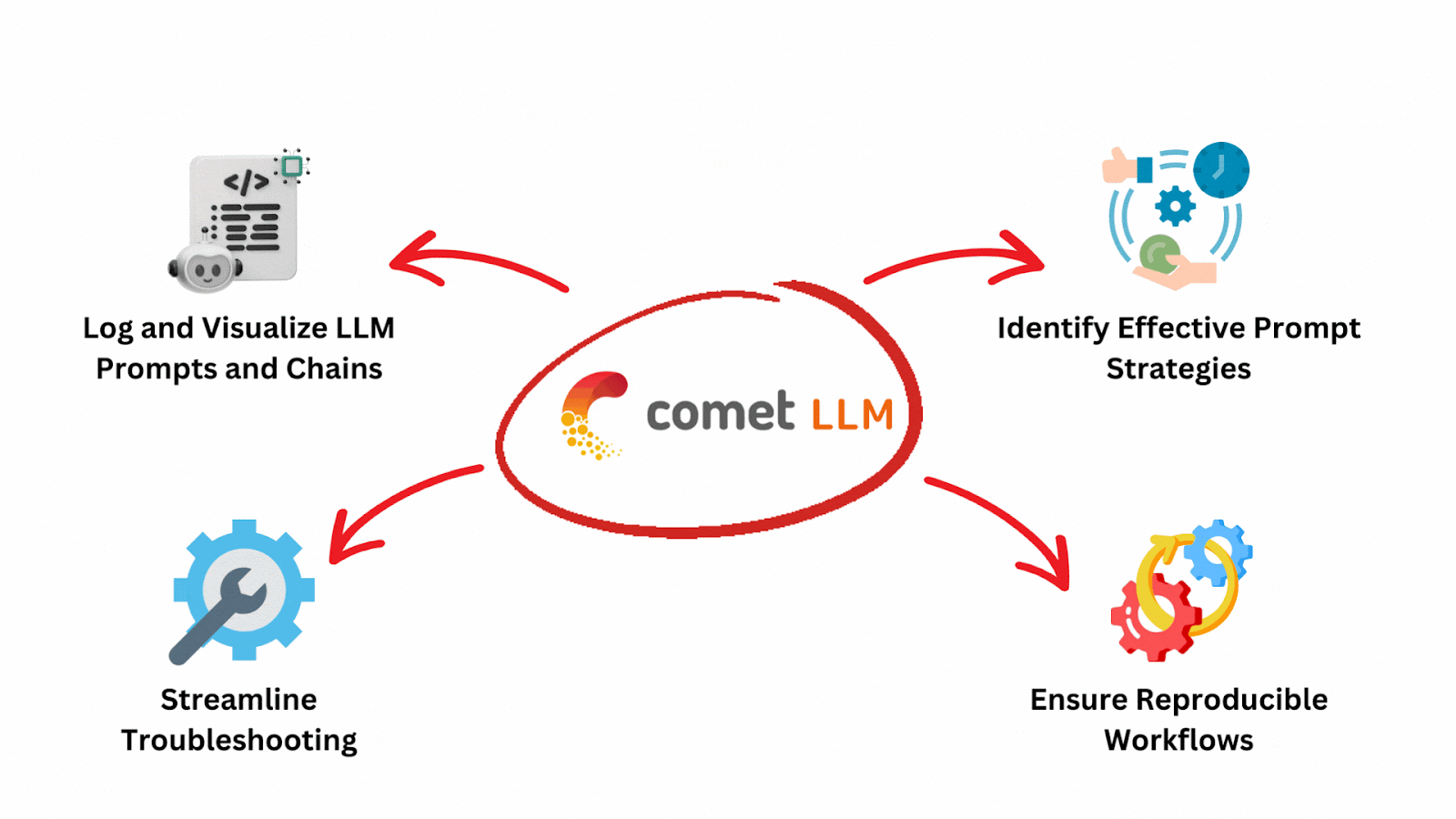
The features of CometLLM can be summarized as shown below:
Let’s implement CometLLM for Prompt Logging and Visualization.
Step 1: Create an account on https://www.comet.com/ for using Comet API key and Workspace –
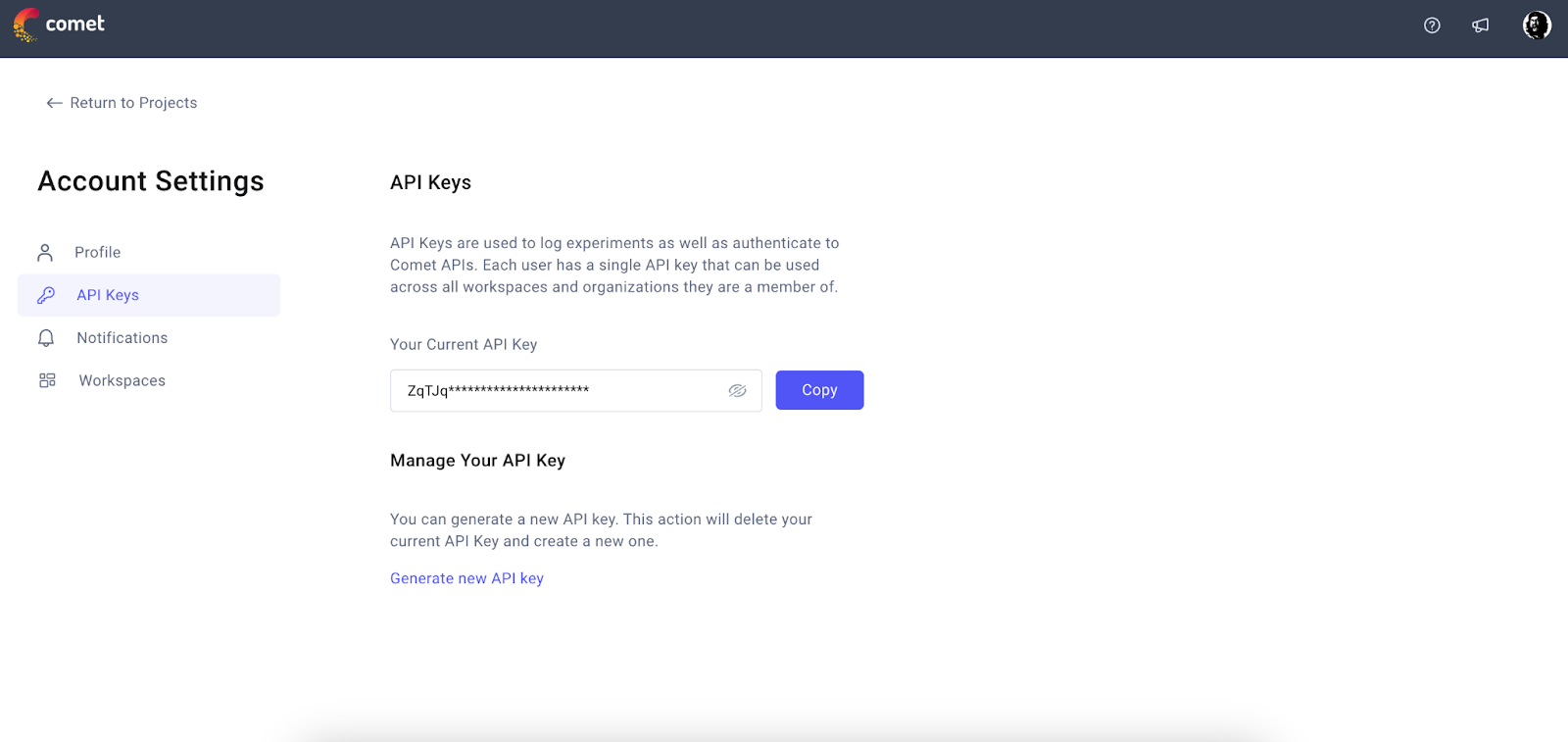
Step 2: Goto the account settings for generating the API key once the login process is complete. This API key will be used to log LLM prompt execution and results with the metadata –
Step 3: Use a Python code editor (such as Jupyter notebook) and code –
Install the necessary libraries –
%pip install -q comet_llm openai langchain-openai langchain-communityStep 4: Initialize the CometLLM API and use the designated project and workspace –
import comet_llm
comet_llm.init(project="demo_project101", workspace="godfather-ace")Output:

Step 5: OpenAI API Setup –
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")Step 6: Response generation using OpenAI gpt-4o-mini model –
from openai import OpenAI
client = OpenAI()
response1 = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "Generate a summary based on the provided content. Be brief in your response. "
},
{
"role": "user",
"content": "The Game of Thrones was a great fantasy drama television series"
}
],
temperature=0.4,
max_tokens=256
)Output:

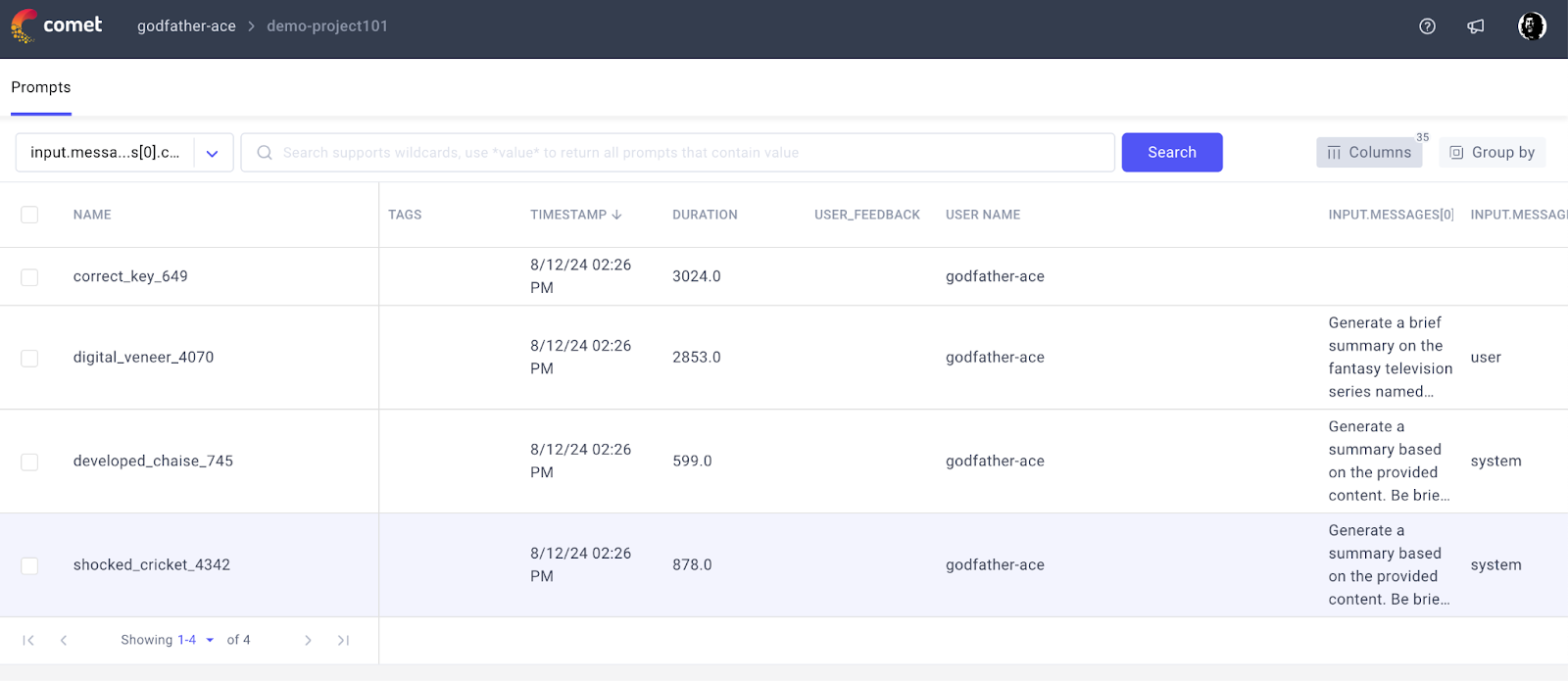
Step 7: Check the Comet project page on the web for the prompt log and trace –
Output:
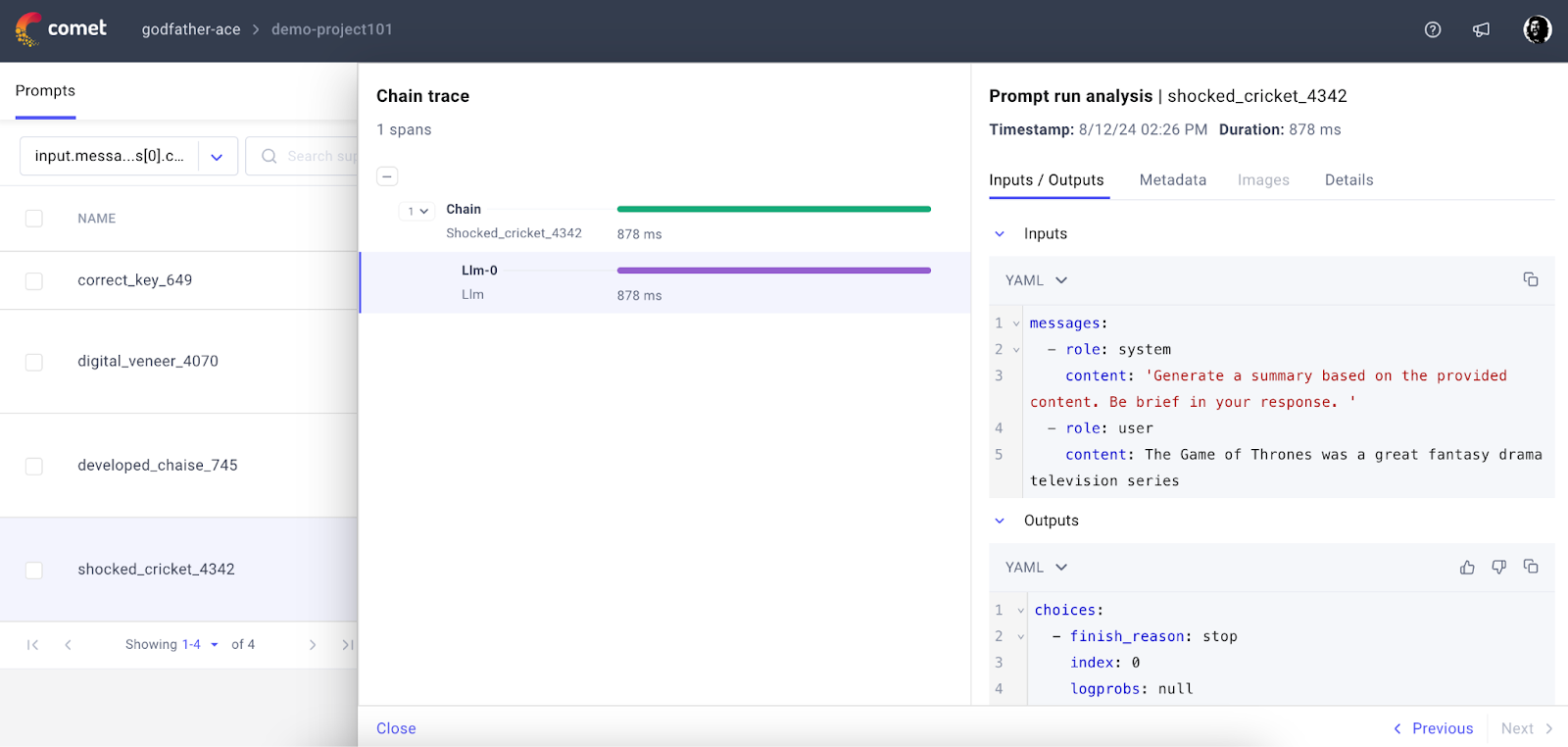
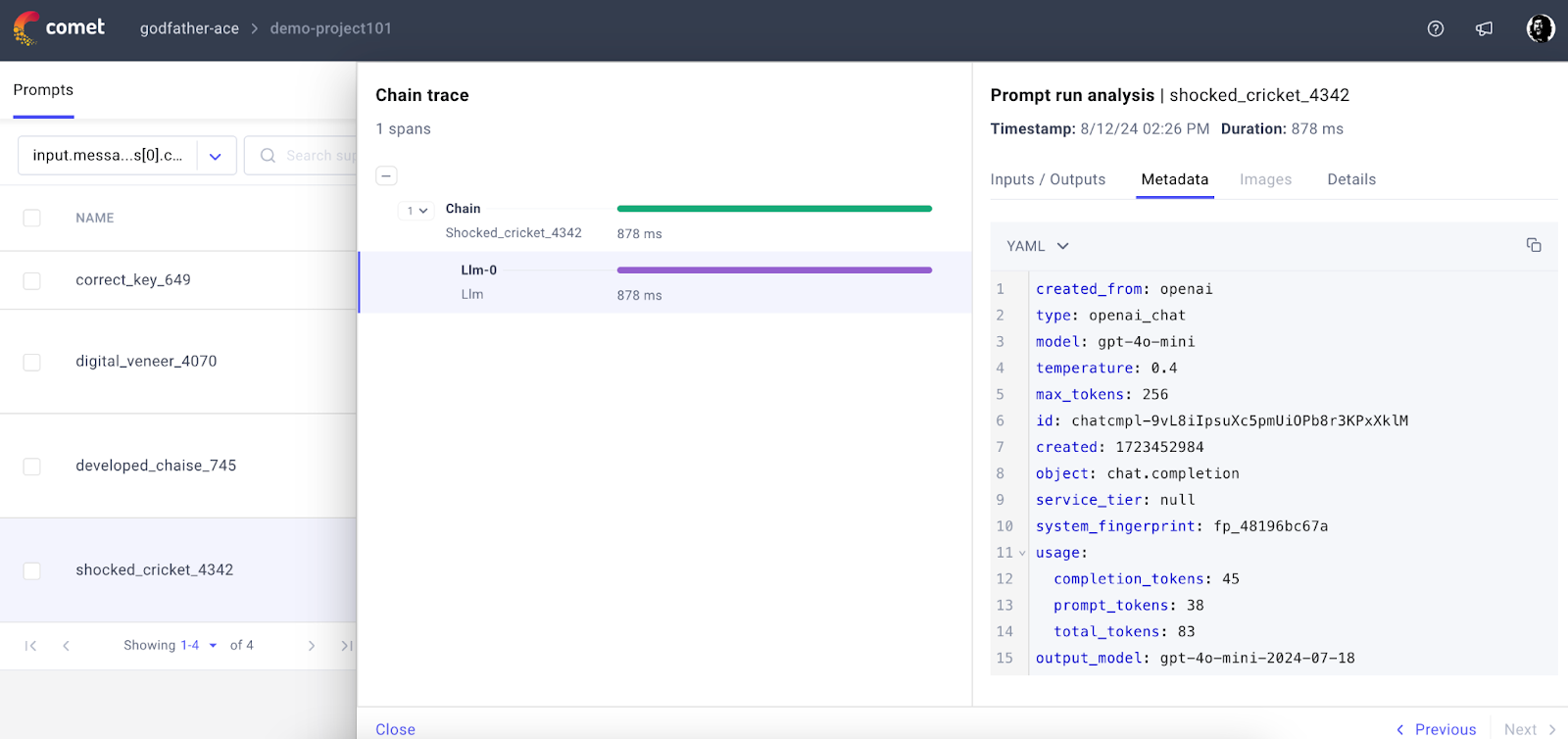
Step 8: Let’s implement a LangChain pipeline with CometTracer for tracing the operation –
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.callbacks.tracers.comet import CometTracer
# Define your LLM model, prompt, and chain
model = ChatOpenAI(temperature=0.4, model_name="gpt-4o-mini")
prompt = ChatPromptTemplate.from_messages([("human", "Generate a brief summary on the fantasy television series named {topic}")])
chain = prompt | model
# Invoke the chain with the CometTracer callback
chain.invoke({"topic": "The Witcher"}, config = {'callbacks' : [CometTracer()]})Output:
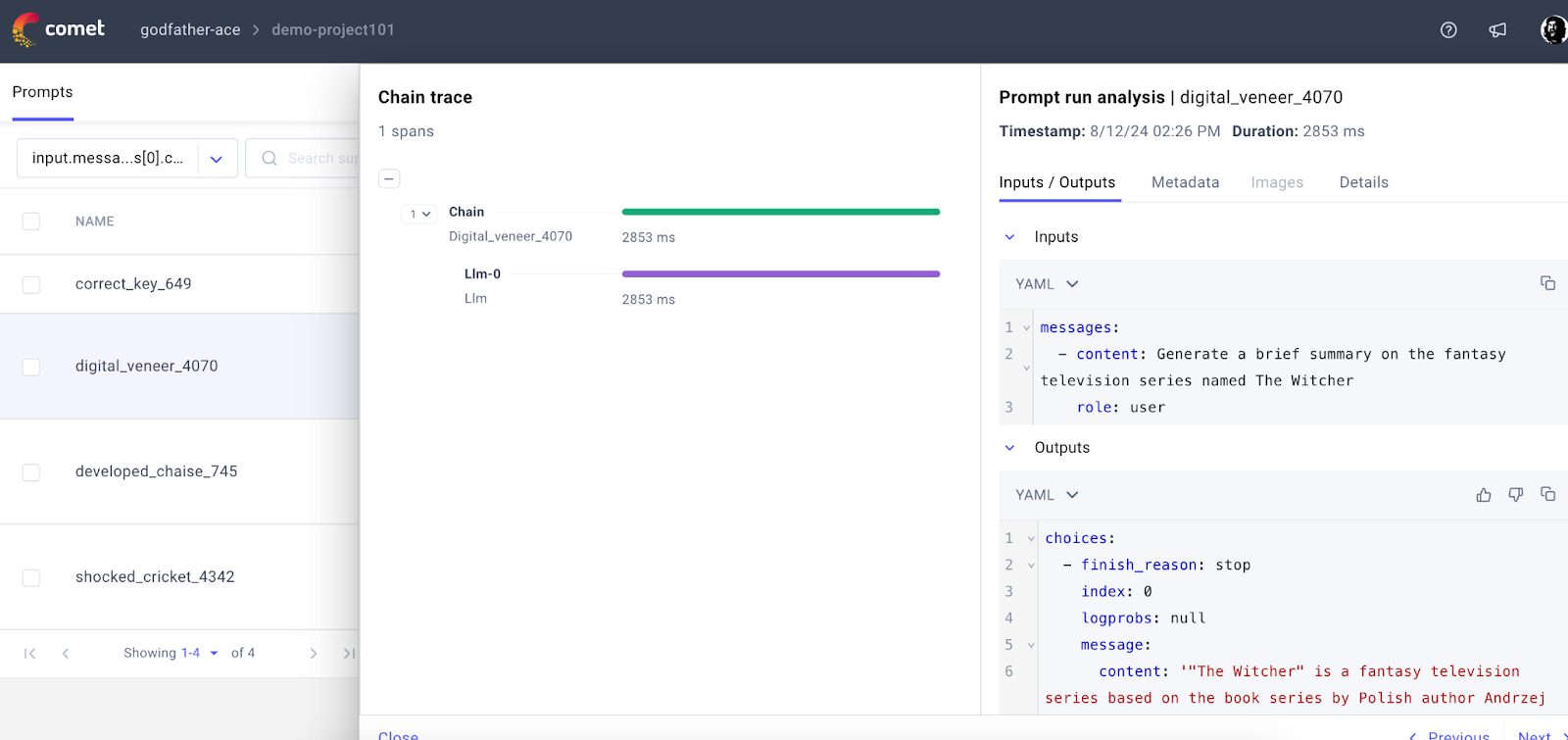
We can see that CometLLM has tracked our prompts and given a complete trace and span of LLM execution and inferencing.
CometLLM represents a good step in implementing explainability under LLMs, with features such as experiment tracking, prompt management and performance analysis. This ability to log, visualize and compare experiments not only streamlines the development process but also facilitates reproducibility which is important in both academic and industry settings.