
NuMind released NuExtract, a foundation model designed specifically for structured data extraction from text. The model can be implemented in a zero-shot setting or fine-tuned for solving specific extraction problems. The open-source model is available on Hugging Face for experimentation and research. The following article explains NuExtract with a hands-on implementation.
NuExtract’s core function is transforming unstructured text into a structured format, specifically JSON. This means it can identify and extract key information from text documents like research papers. Structured data extraction is a process of automatically identifying and extracting specific pieces of information from unstructured text data and converting it into a well-organised format such as JSON or XML.
NuExtract goes beyond the simple conversion of text data into JSON, it understands the language to pinpoint the details (names, dates, locations, or any other data points depending on the text input) a user defines using templates.
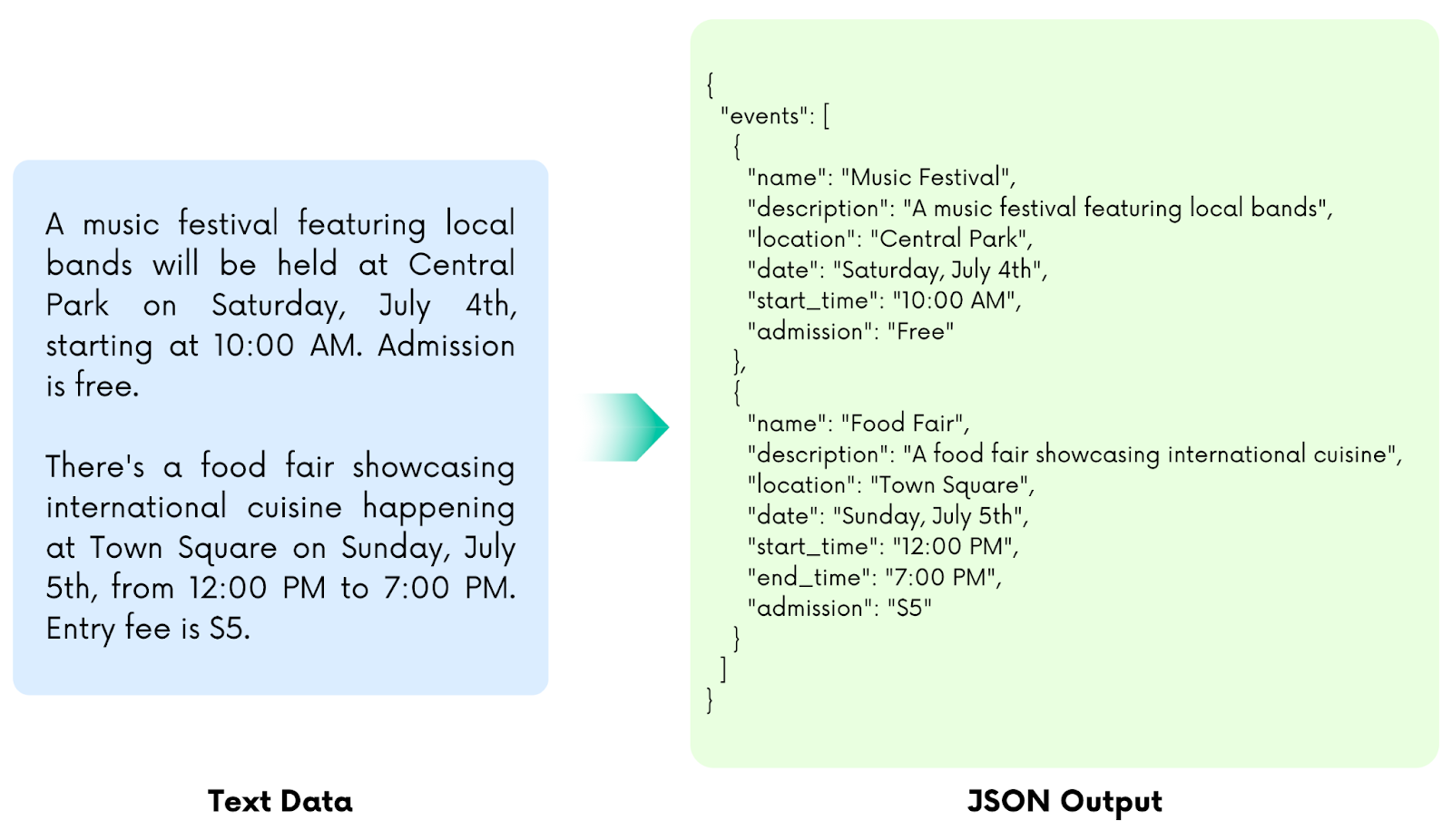
An Example of Structured Extraction
NuExtract was created using a Phi-3, a generic small language model, fine-tuned on synthetic data generated by Llama 3 large language model for obtaining a model specialised in the task of structured extraction. NuExtract can be implemented for zero-shot inference or be fine-tuned for specific tasks.
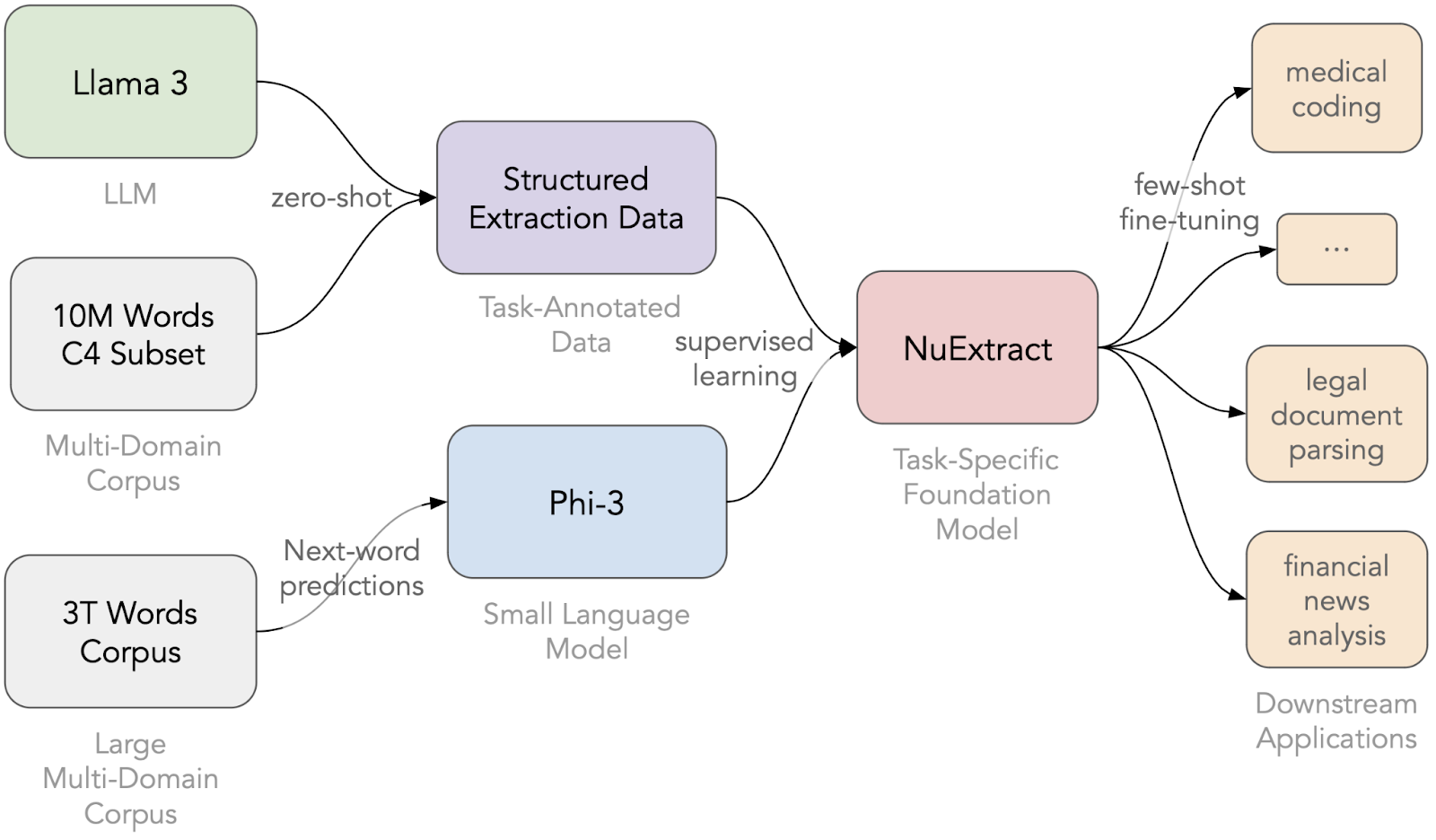
NuExtract offers three model variants – NuExtract-tiny, NuExtract and NuExtract-large which is a result of 0.5B to 7B parameter language models being trained on an LLM-generated structured extraction dataset.
NuExtract-tiny, NuExtract and NuExtract-large are a version of Qwen1.5-0.5, Phi-3-mini and Phi-3-small LLMs respectively, which are fine-tuned on a private high-quality synthetic dataset for information extraction.
As per the zero-shot setting comparison – NuExtract-tiny is better than GPT-3.5, while being 100 times smaller, NuExtract outperforms Llama3-70B while being 35 times smaller and NuExtract-large is reaching GPT-4o levels while being 100 times smaller as shown below:
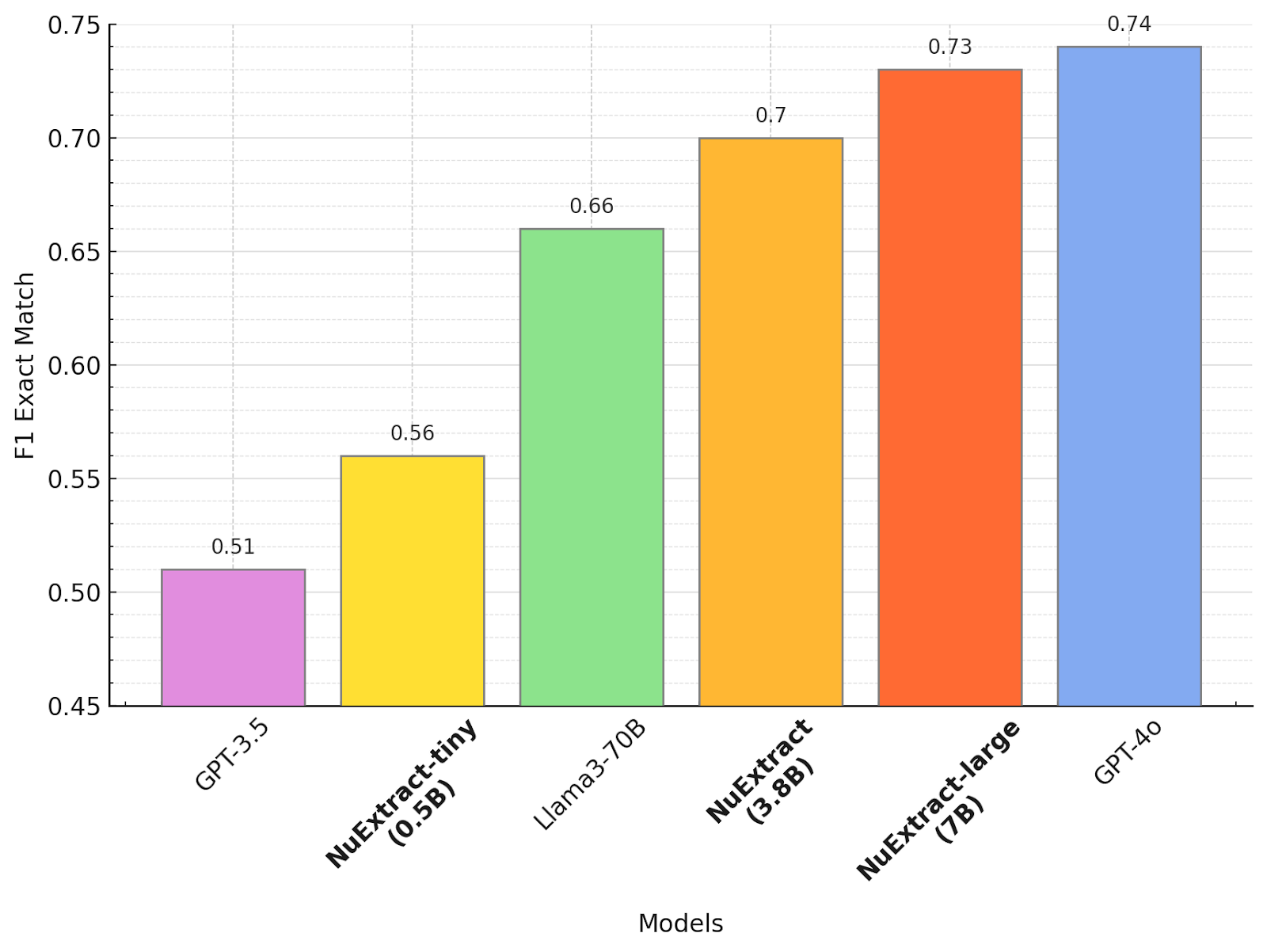
Comparison in Zero-Shot Setting
Fine-tuning NuExtract models based on chemical extraction problem, substantially outperform fine-tuned GPT-4o while being at least 100 times smaller as shown in the image below
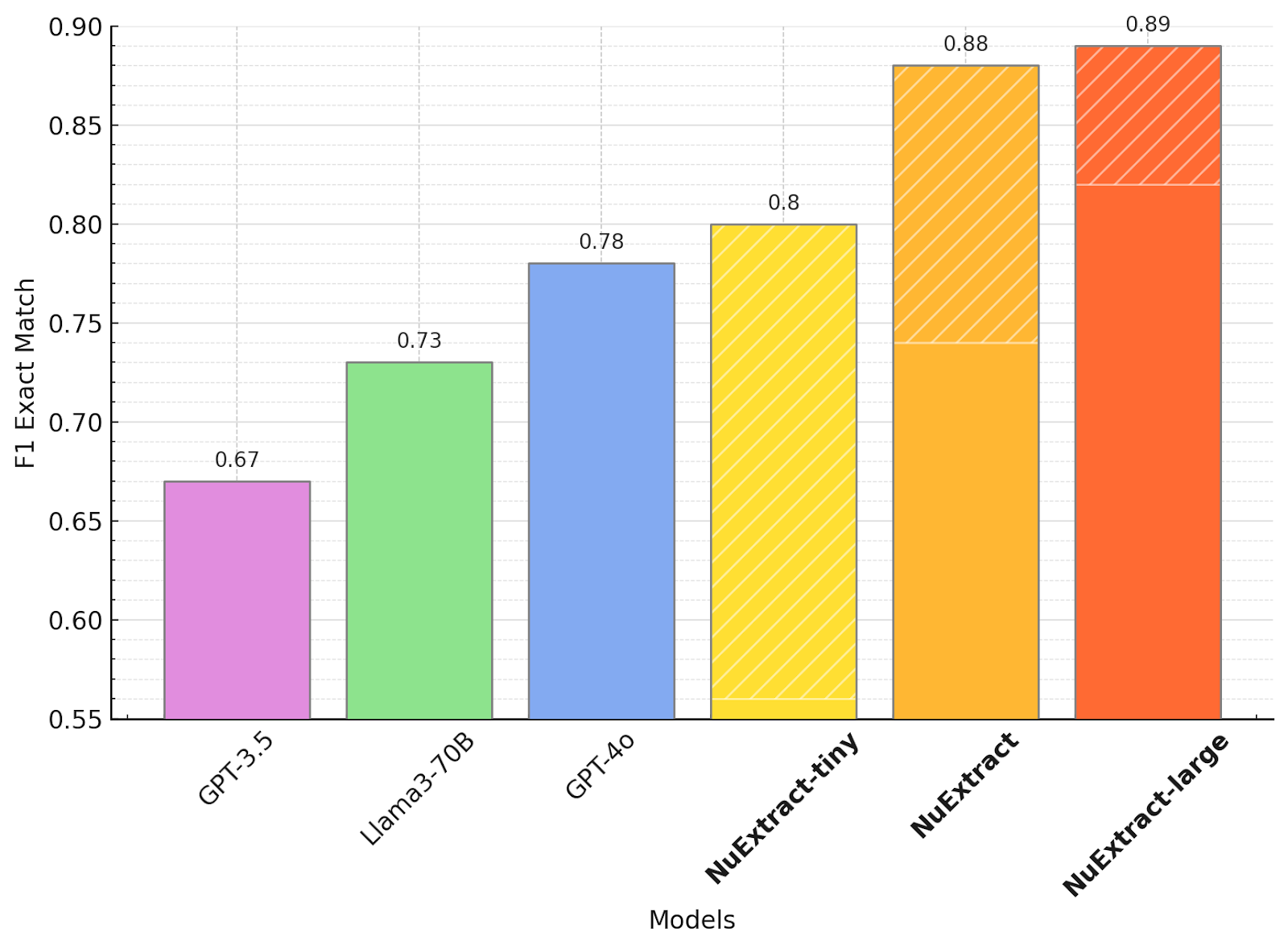
Comparison in Fine-tuned Setting
Step 1: Importing the required libraries –
import json
from transformers import AutoModelForCausalLM, AutoTokenizerStep 2: Using the function predict_NuExtract for simulating the functionality of NuExtract. The function preprocesses the input, performs tokenization, model inference and extracts the predicted output from the text according the given user schema.
def predict_NuExtract(model, tokenizer, text, schema, example=["","",""]):
schema = json.dumps(json.loads(schema), indent=4)
input_llm = "<|input|>\n### Template:\n" + schema + "\n"
for i in example:
if i != "":
input_llm += "### Example:\n"+ json.dumps(json.loads(i), indent=4)+"\n"
input_llm += "### Text:\n"+text +"\n<|output|>\n"
input_ids = tokenizer(input_llm, return_tensors="pt", truncation=True, max_length=4000).to("cuda")
output = tokenizer.decode(model.generate(**input_ids)[0], skip_special_tokens=True)
return output.split("<|output|>")[1].split("<|end-output|>")[0]Step 3: Loading the NuExtract model and tokenizer from the transformers model hub and setting parameters – model.to(“Cuda”) for moving the loaded model to the CUDA device, if available, for speeding up the computations. model.eval() sets the model to evaluation mode as model is training is not done, only predictions are made based on the data.
model = AutoModelForCausalLM.from_pretrained("numind/NuExtract-tiny", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("numind/NuExtract-tiny", trust_remote_code=True)
model.to("cuda")
model.eval()Step 4: Passing the input text and schema for structured extraction. The schema dictates the JSON keys for structuring.
text = """A music festival featuring local bands will be held at Central Park on Saturday, July 4th, starting at 10:00 AM. Admission is free."""
schema = """{
"Events": {
"Name": "",
"Description": "",
"Location": "",
"Date": "",
"Start_Time": "",
"Admission": ""
}
}"""
prediction = predict_NuExtract(model, tokenizer, text, schema)
print(prediction)Output
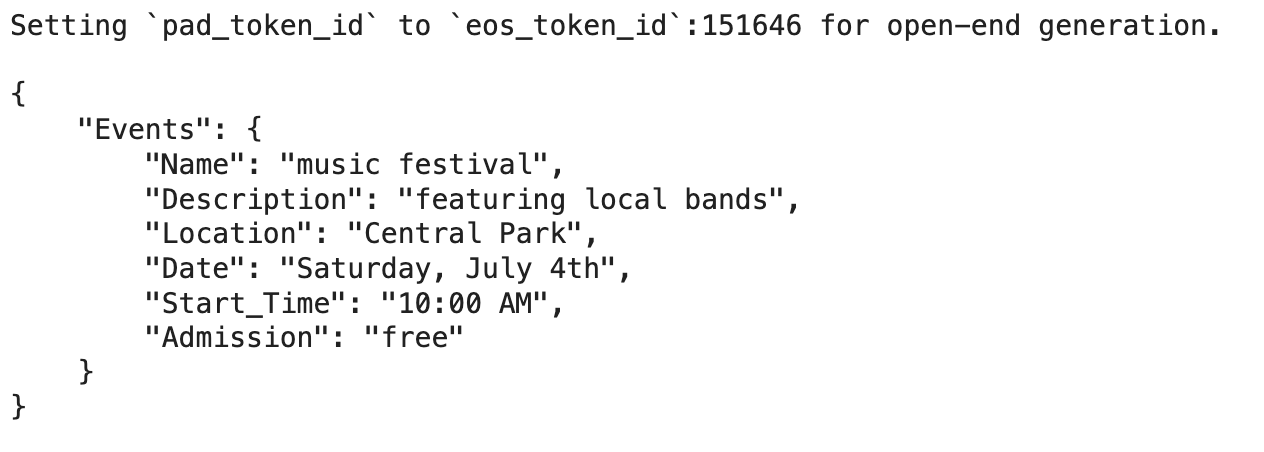
The output gives the accurate JSON output based on the input text and schema template. NuExtract was able to identify and extract information about each key from the text based on the template.
NuExtract is a promising step towards effortless information extraction. The lightweight design, zero-shot learning capabilities and open-source release makes it a viable solution for structured extraction requirements. However, further research and development is required for exploring NuExtract’s limitations and refine its accuracy.
Learn more about generative AI and large language models through our hand-picked courses:








