
Encoder-based models like BERT have been the backbone of many natural language processing (NLP) applications. However, as new challenges in retrieval, classification, and efficiency emerge, modernized versions of these models are needed to meet growing demands. Enter ModernBERT, a state-of-the-art bidirectional encoder that combines modern architectural advancements with efficiency optimizations. In this article, we will be exploring the features, implementation, and use cases of ModernBERT.
ModernBERT is a modernized version of BERT, designed to improve both downstream performance and efficiency. Unlike its predecessor, it supports:
ModernBERT is available in two sizes:
These models outperform prior encoders in a range of benchmarks while maintaining computational efficiency.

ModernBERT uses rotary positional embeddings (RoPE), which outperform absolute embeddings, particularly in handling long-context scenarios.
Key architectural upgrades include:
ModernBERT avoids inefficiencies in padded sequences by utilizing unpadding techniques, significantly speeding up training and inference.
ModernBERT’s architecture maximizes GPU utilization, delivering faster inference speeds and supporting larger batch sizes.
Step 1: Install Necessary Libraries
Install the Hugging Face `transformers` library and Flash Attention for optimized inference.
!pip install git+https://github.com/huggingface/transformers.git
!pip install flash-attnStep 2: Import Libraries
Import essential libraries such as `torch`, `transformers`, and `pprint` for loading the model and running inference.
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM, pipeline
from pprint import pprintStep 3: Load the ModernBERT Model and Tokenizer
Specify the ModernBERT model ID and load both the tokenizer and model using the `transformers` library.
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id, torch_dtype=torch.bfloat16)Step 4: Check GPU Availability
Determine if a GPU is available and load the model onto the appropriate device for faster processing.
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)Step 5: Set Up the Fill-Mask Pipeline
Initialize a pipeline for masked language modeling using the ModernBERT model and tokenizer.
pipe = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer,
device=0 if device == "cuda" else -1
)Step 6: Provide Input Text
Define a text input containing a [MASK] token for the model to predict.
input_text = "He walked to the [MASK]."Step 7: Perform Inference
Use the pipeline to predict the token that should replace the [MASK] in the input text.
results = pipe(input_text)Step 8: Display Results
Output the model’s predictions for the masked token in a readable format.
pprint(results)Output:-
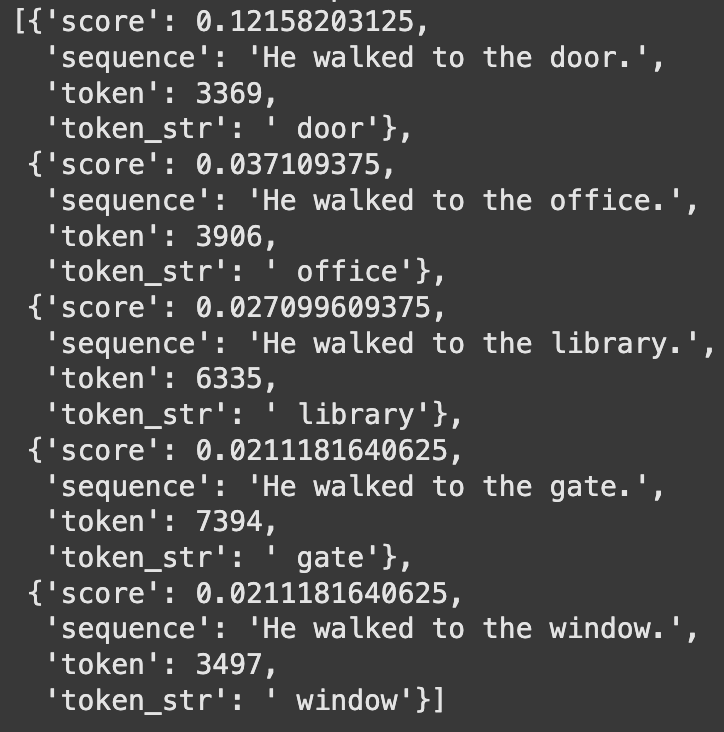
ModernBERT employs:
ModernBERT processes tokens nearly two times faster than previous models, with optimized memory usage enabling larger batch sizes.
ModernBERT sets new benchmarks in:
ModernBERT excels in information retrieval tasks, making it an ideal component for RAG pipelines. It efficiently retrieves relevant documents, improving the performance of large language models in downstream tasks.
With a sequence length of 8192 tokens, ModernBERT is well-suited for long-document retrieval applications, including legal and scientific research.
Pretrained on code datasets, ModernBERT supports code search and retrieval, aiding in programming and development workflows.
ModernBERT redefines what encoder-based models can achieve. With its hardware-aware design, long-context support, and state-of-the-art performance, it is poised to become a cornerstone for NLP and IR tasks. Whether you’re a researcher, developer, or AI enthusiast, ModernBERT offers the tools to tackle complex challenges efficiently and effectively.





