
Large Language Models (LLMs) have become pivotal in driving innovation across industries. However, adapting these models to specific tasks or domains involves a critical decision: fine-tuning the entire model or leveraging parameter-efficient tuning (PET) techniques. Each approach offers unique trade-offs in computational cost, flexibility, and performance. This article explores these two strategies, helping you choose the best approach for your applications.
Fine-tuning is the process of adjusting all the parameters of a pre-trained LLM to optimize it for a specific task. This method involves retraining the model on a labeled dataset, effectively tailoring it to a new domain or use case.
Weighing Full Fine-Tuning’s Benefits and Costs
Parameter-efficient tuning (PET) focuses on modifying only a small subset of model parameters, such as adapter layers or prompt embeddings, while keeping the rest of the model frozen. This approach minimizes resource requirements and simplifies deployment.
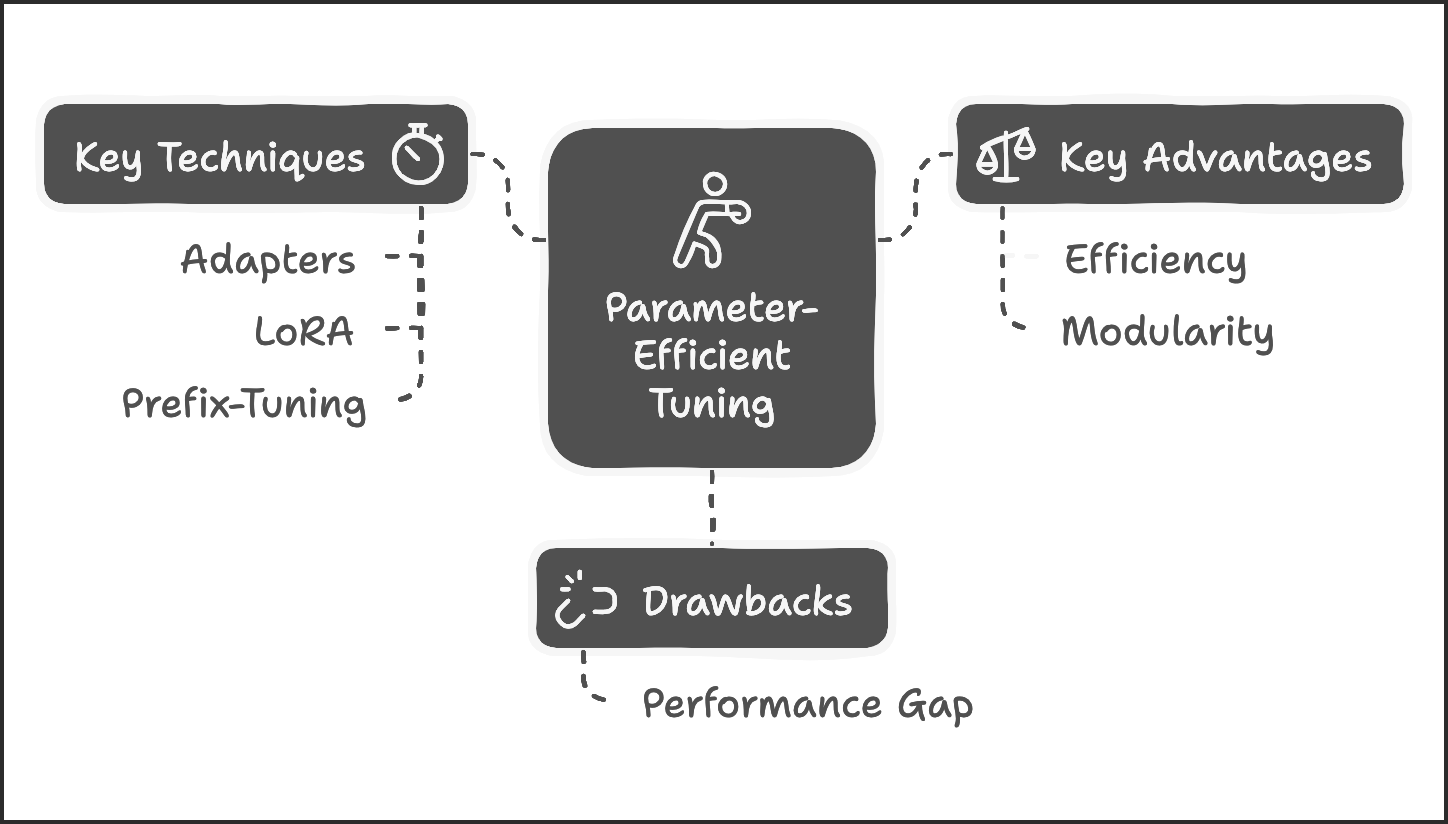
PEFT Techniques, Advantages and Drawbacks
| Feature | Full Fine-Tuning | Parameter-Efficient Fine-Tuning (PET) |
| Trainable Parameters | All parameters | Only adapter layers or low-rank matrices |
| Computational Cost | High | Low |
| Model Structure | Unchanged | Additional layers or matrices added |
| Training Time | Longer | Shorter |
| Inference Latency | Higher | Lower (if adapters are merged) |
The choice between Full fine-tuning and parameter-efficient tuning depends on your application’s specific needs, resources, and goals. By understanding the trade-offs and leveraging best practices, you can harness the power of LLMs effectively.




