
As the AI landscape around LLMs continues to evolve and grow, several no-code platforms have been designed to assist users in developing LLM applications and utilising their enormous benefits. Airtrain AI is one such no-code compute platform designed to streamline the process of data curation and LLM fine-tuning by providing a user-friendly interface alongside several high-quality LLMs, empowering users to create more effective and specialized LLMs. This article explores Airtrain AI and its implementation in detail.
Let’s start with understanding the Airtrain AI.
Airtrain AI is a no-code platform no-compute platform that enables users to generate high-quality datasets by combining data with human-generated content, or explore and gather insights on existing datasets, finetune LLMs to domain-specific use cases, experiment and compare different LLMs and evaluate them on different evaluation sets.
The platform’s no-code interface makes it accessible to users who do not have programming experience, and its scalability allows it to handle large datasets and complex models. Additionally, Airtrain AI can be integrated with LLM orchestration frameworks such as LlamaIndex for easy and efficient data loading capabilities.
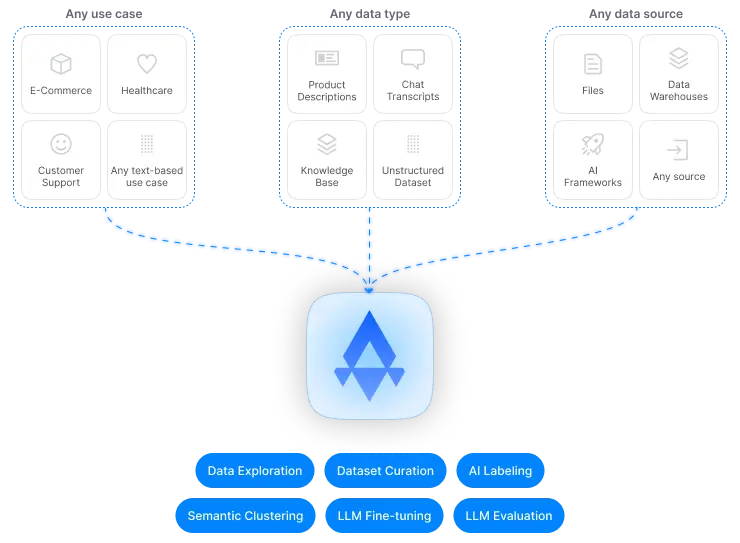
Airtrain AI Features (Source)
Airtrain AI uses Airtrain Python SDK with three primary integrations – Pandas, Polars and LlamaIndex. The users need to log into the Airtrain AI’s web UI and obtain an API key which can then be used for dataset uploads through integrations. Airtrain can ingest the data, primarily in jsonl and parquet format, and produce a wide array of insights based on the data automatically. Some of these generated insights are based on data embeddings, so Airtrain also has a provision of embedding data automatically if not done manually by the user.
Airtrain is composed of four primary compute workloads:
Dataset exploration and curation – The Airtrain AI dataset explorer lets users explore, segment, curate, visualize and generate insights based on the provided dataset. Semantic clusters and cluster filtration are some unique features that assist users in data exploration and segmentation with ease.
Offline batch evaluation of LLMs – Batch evaluation enables users to generate evaluation metrics on an entire dataset for different models. The users can use web UI to configure different LLMs and select metrics for evaluation with customized properties and attributes. Top LLMs such as OpenAI, Claude, Gemini, Mistral, and Llama3 are supported by Airtrain AI along with custom models. Airtrain offers different evaluation techniques as well, such as JSON schema validation, reference-based metrics, AI scoring and unsupervised metrics.
Fine-tuning LLMs – The web interface of Airtrain allows the users to execute a fine-tune job based on their uploaded dataset and then exporting the resulting model for further model serving. The model weights exported from Airtrain are compatible with the Hugging Face ecosystem and can be served via an inference server.
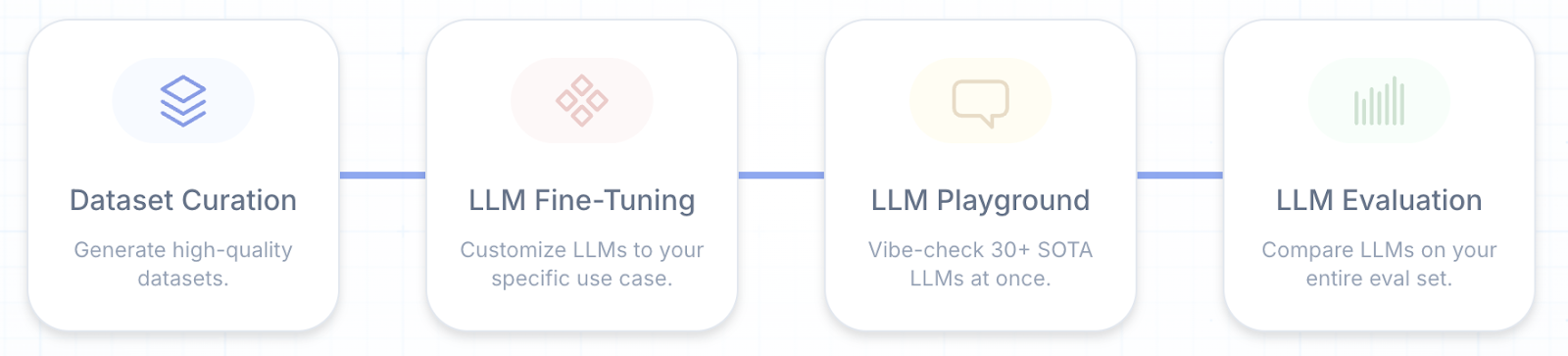
Airtrain AI Compute Workloads (Source)
LLM Playground – Airtrain web UI also provides a prompt playground for users to query their selected models and compare the generated responses simultaneously. Once the free user credits expire, the LLM playground is charged as per the inference tokens based on a set pricing per model.
Let’s implement Airtrain AI for dataset curation, exploration and evaluation. For this practical exercise, we will use LlamaIndex integration to upload the MMLU data onto Airtrain AI and inspect the insights generated by it.
Step 1: Create an account on Airtrain AI. It offers 10$ free credits to work on its playground while the dataset curation and exploration are free until 10k rows. Once the account is created, copy the API key. This API key will be used in integration with LlamaIndex for dataset upload using LlamaIndex data loaders such as Simple Directory Reader, Web Reader, etc.
Step 2: Now we will use a Jupyter Notebook to code and get our data into Airtrain AI. Install the necessary packages –
%pip install llama-index llama-index-embeddings-openai airtrain-py[llama-index]Step 3: Import the packages –
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import SimpleDirectoryReader
from google.colab import userdata
import airtrain as at
import osStep 4: Initialize the OpenAI and Airtrain APIs –
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
os.environ["AIRTRAIN_API_KEY"] = userdata.get("AIRTRAIN_API_KEY")Step 5: Load the data, we will be using the MMLU-Pro dataset for implementing automatic semantic clustering through Airtrain AI (https://huggingface.co/datasets/TIGER-Lab/MMLU-Pro)
reader = SimpleDirectoryReader(
input_dir= "data/"
)
documents = reader.load_data()Step 6: Embed the data using OpenAI Embeddings (this step is optional, Airtrain AI has inbuilt embedding as well)
embed_model = OpenAIEmbedding()
splitter = SemanticSplitterNodeParser(
buffer_size=1, breakpoint_percentile_threshold=95, embed_model=embed_model
)
nodes = splitter.get_nodes_from_documents(documents)Step 7: Once the embedding is done, upload the generated nodes on Airtrain Web UI
result = at.upload_from_llama_nodes(
nodes,
name="MMLU-Pro"
)Step 8: Check the Airtrain AI datasets section for the automatically generated dashboard providing insights based on the ingested data (the data ingestion can take some time based on the data size and latency) –
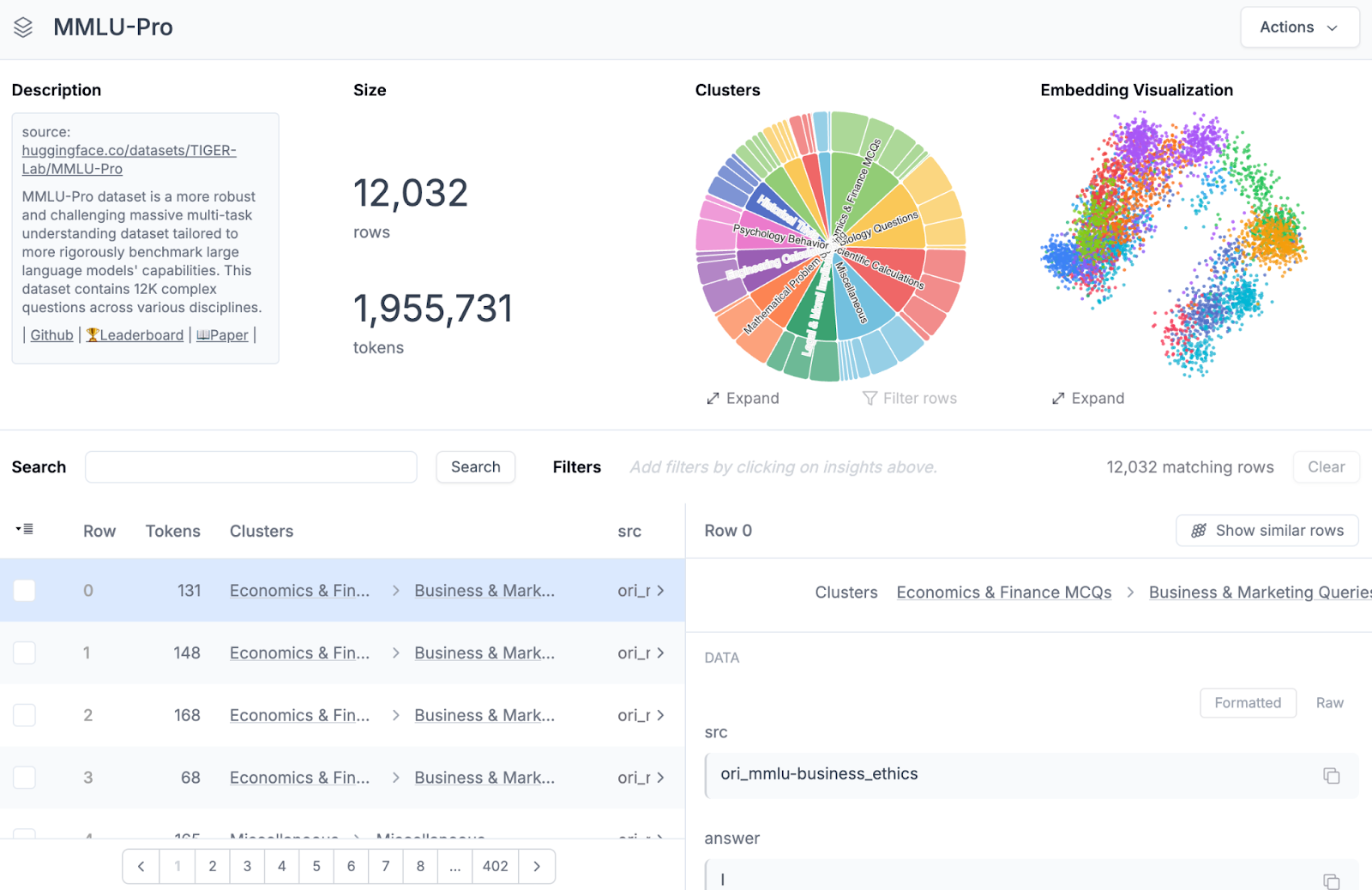
We can interact with the generated visualizations on semantic clustering and embeddings –
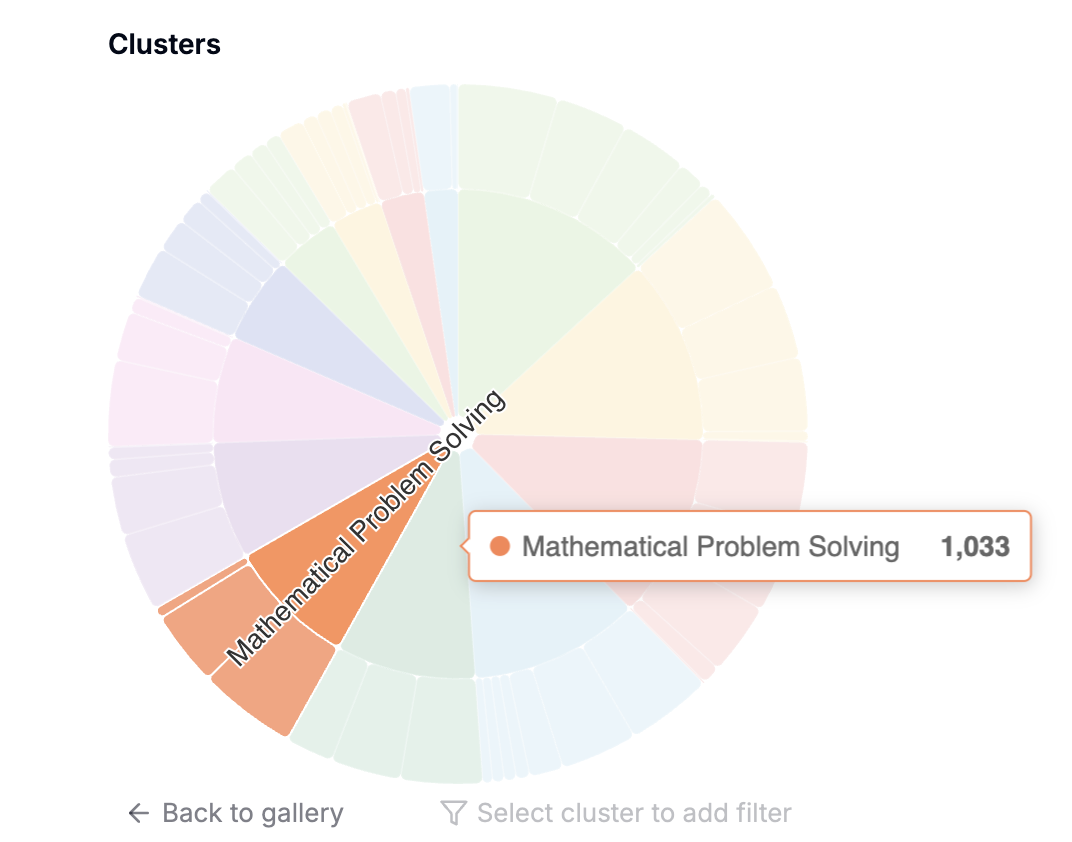
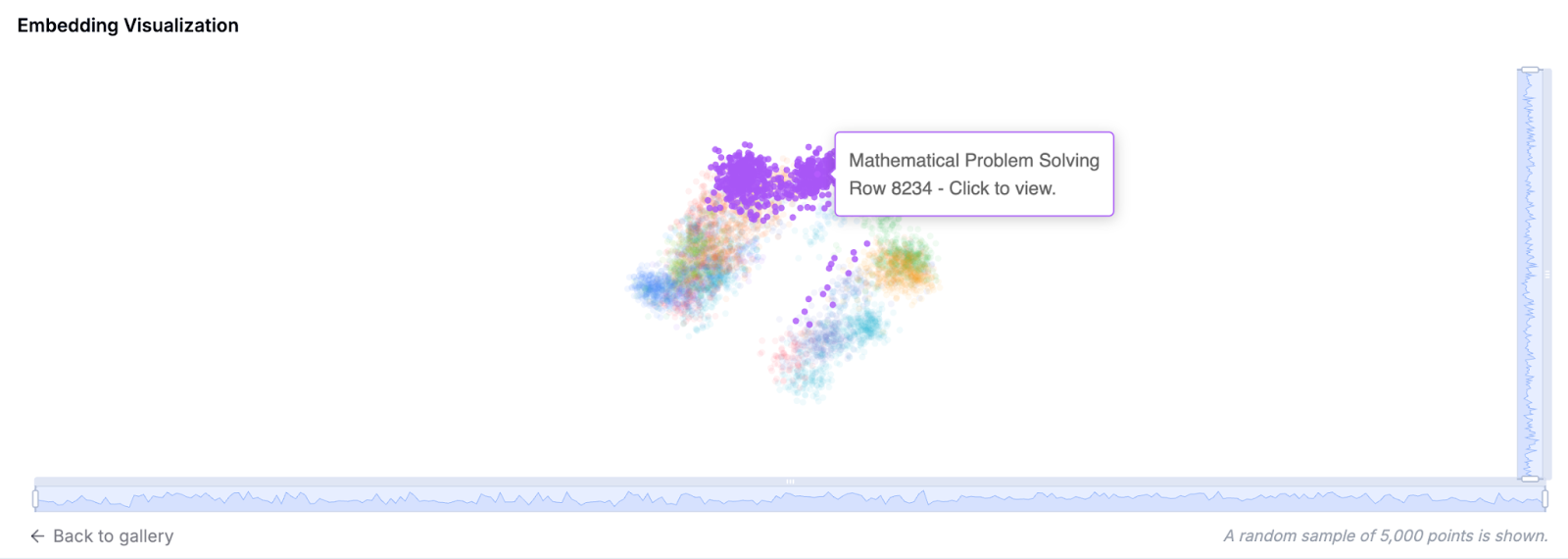
Filtering can also be applied to check similar rows –
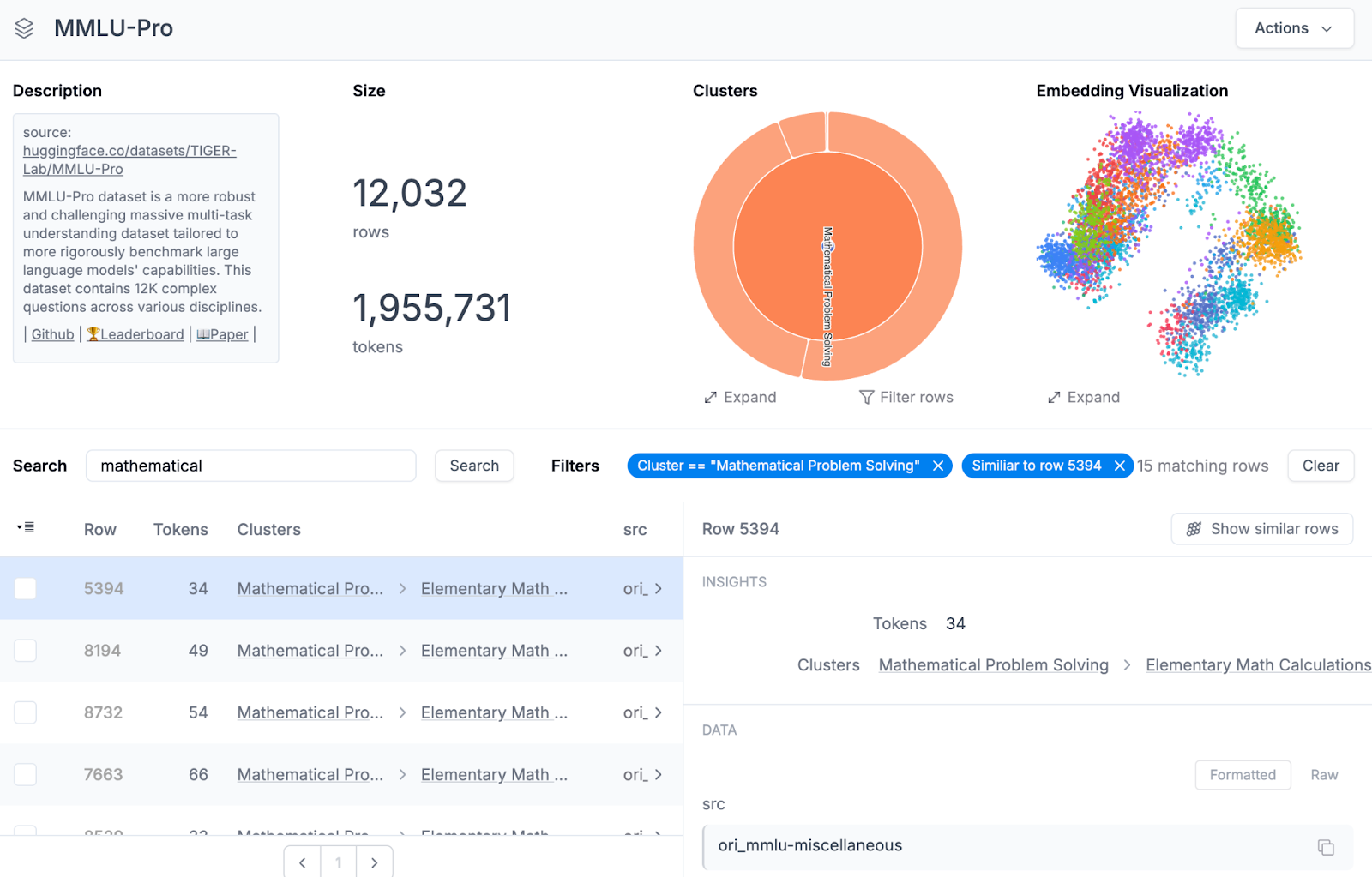
The entire dataset can be used for finetuning or evaluating LLMs using Airtrain AI’s web interface as well.
Step 9: Let’s evaluate our data on Llama 2-7B and Llama 3-8B models through the model evaluation job in Airtrain AI. We will use the following prompt template and correctness property-
Prompt Template –
Here is a question on the topic of {{topic}}.
Question: {{question}}
Which of the following answers is correct?
A. {{answer_a}}
B. {{answer_b}}
C. {{answer_c}}
D. {{answer_d}}
State the letter corresponding to the correct answer.Correctness Property –
This score describes whether the chatbot selected the correct answer.
The correct answer is {{correct_answer}}.
Here is a scoring rubric to use:
1. The chatbot's answer is not {{correct_answer}}, therefore the chatbot is incorrect.
5. The chatbot's answer is {{correct_answer}}, therefore the chatbot is correct.
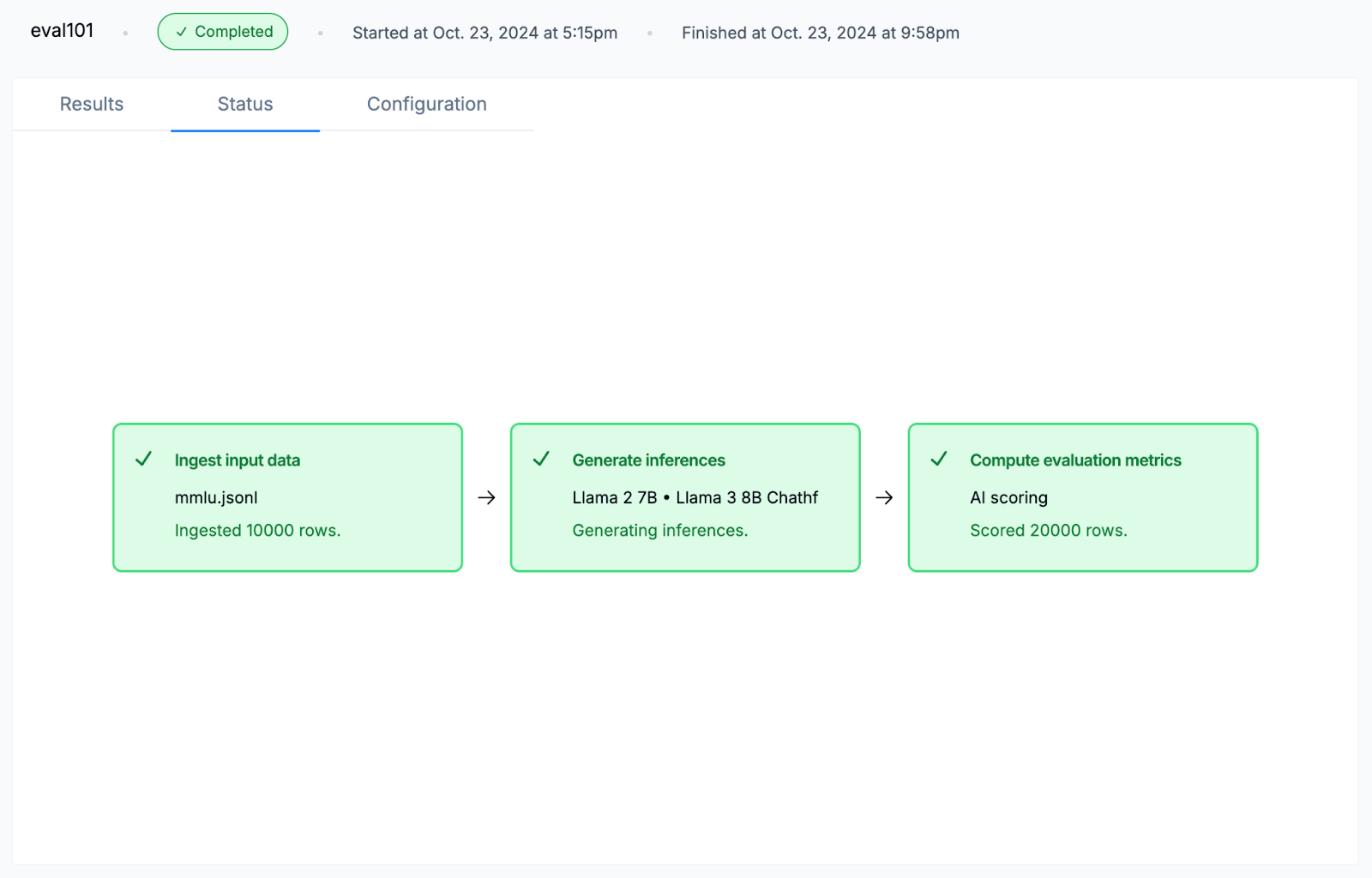
Final Outcome of our evaluation –
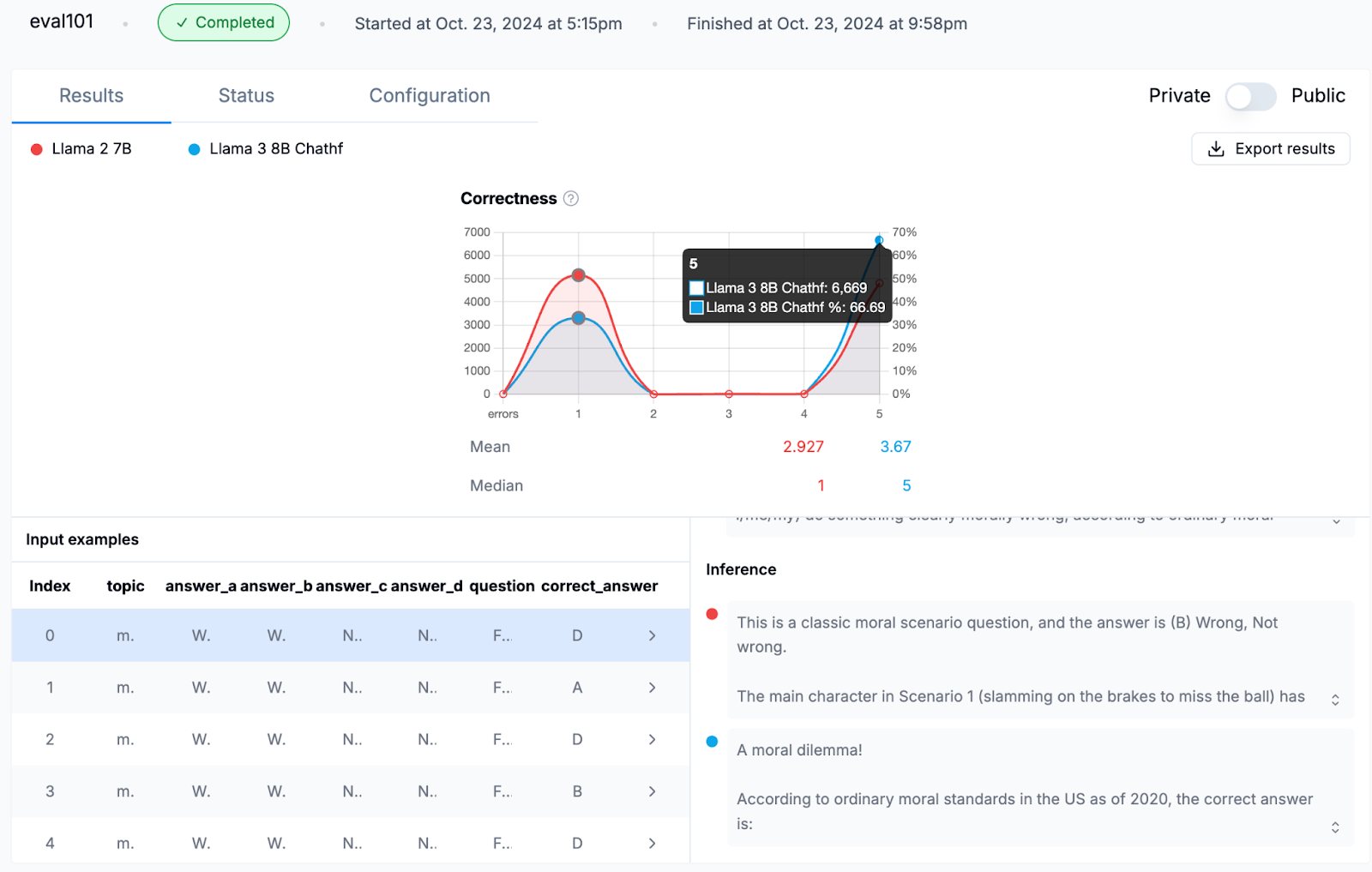
We can see that Airtrain’s MMLU correctness score for Llama2 7B is 48.08% whereas Llama3 8B-ChatHF model leads with 66.69% which is closer to the official MMLU correctness benchmark scores as shown below:
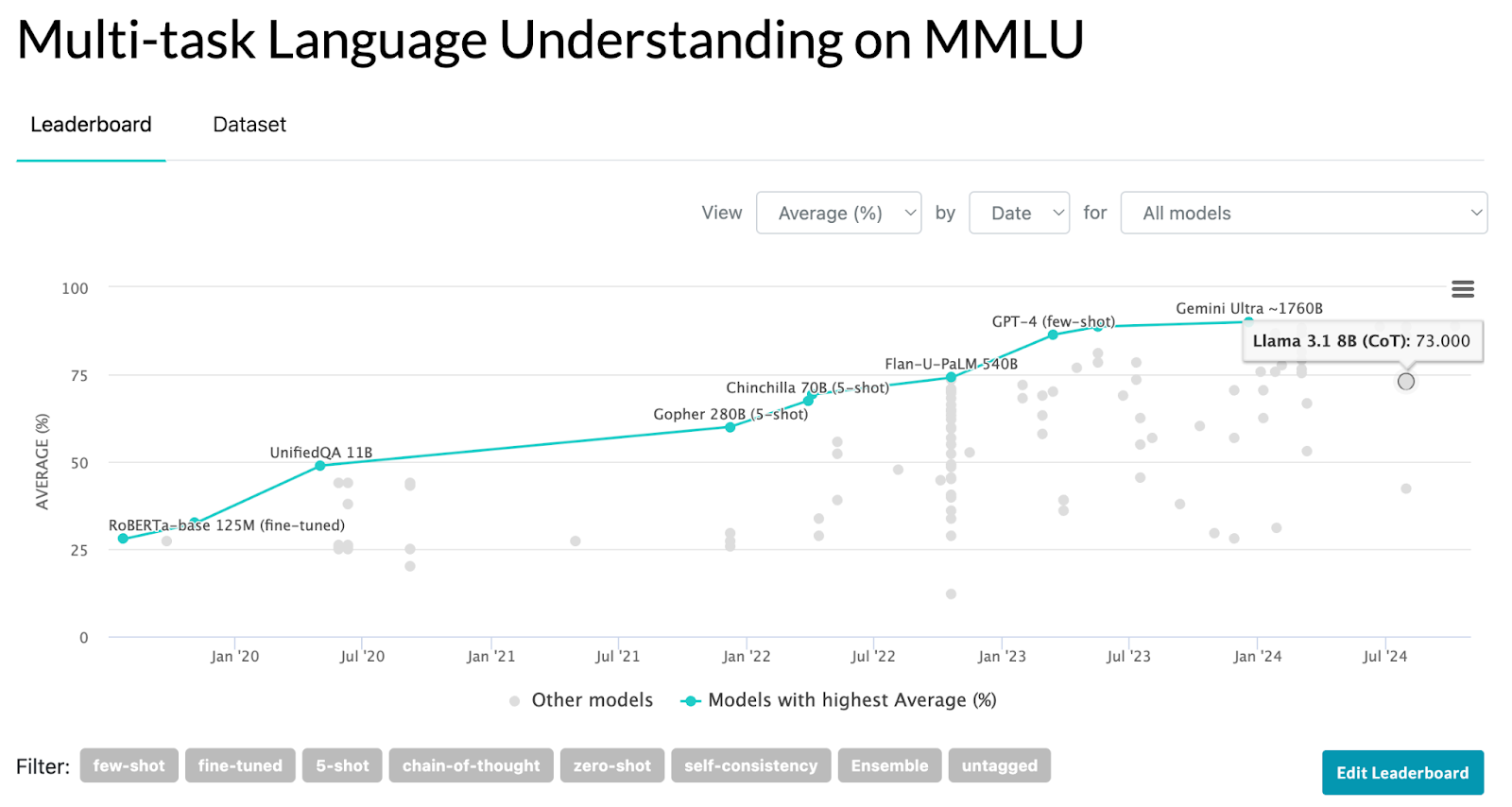
Actual MMLU Benchmark (Source)
Airtrain AI provides a user-friendly platform for data curation, LLM fine-tuning, batch evaluations and a sophisticated LLM playground for comparing models. Its ability to curate and generate high-quality datasets and tailor LLMs to specific domains is a valuable asset in terms of AI advancement in different areas based on a no-code platform. Tools like Airtrain AI will play a huge role in shaping the future of LLM usage and capability increment.





