
Retrieval augmented generation (RAG) is one of the most important developments in the discipline of Gen AI and large language models, but as the complexity of RAG systems increase, there is need for effective observability and evaluation techniques. Literal AI is one such comprehensive solution for monitoring, analysing and optimising RAG pipelines through a suite of tools and techniques. In this article, we will understand Literal AI and its working through a practical implementation.
Let’s understand the workings of Literal AI based on its integration with LlamaIndex.
Literal AI is a collaborative platform designed specifically to assist users in building and optimising LLM applications. It is an essential tool for ensuring the reliability, efficiency and effectiveness of AI-powered solutions built using LLMs. Literal AI offers multimodal logging, that involves recording and storage of data from different sources or modalities such as vision, video and audio. This approach enables users to gain a deeper understanding in terms of observability and tracing of LLM response generations.
The primary USP of Literal AI is its collaborative platform which employs the use of various LLM-based techniques and concepts such as prompt management, logging, and evaluation based on a variety of functionalities such as experimentation, integrations, versioning, monitoring, analytics, etc.

Collaborative Flow on Literal AI (Source)
Literal AI supports different LLM application use cases such as text generation, information extraction, reasoning, RAG, agentic applications, conversation threads and copilots along with application building based on Python and Typescript.

Literal AI Platform Overview (Source)
The key features and functionalities of Literal AI can be shown using the image below:

LLM observability is one of the critical aspects in managing and improving the performance of LLMs. Literal AI provides three primary components for this purpose, namely, prompt tracking, performance monitoring and error analysis. Prompt tracking allows users to monitor the evolution of prompts over time. It is a part of prompt management which allows users to identify trends, optimise prompts and understand model drift based on prompt modifications.
Performance monitoring under LLM observability provides real-time insights into the operational efficiency of LLMs. It utilises different metrics such as latency, throughput, resource utilization, and cost efficiency. Error analysis on the other hand is essential for identifying and addressing issues in LLM outputs. Common errors include hallucinations, bias and factual inaccuracies.
LLM evaluation is another crucial component in the development and deployment of LLMs. It involves assessing the quality, reliability and performance of models. Literal AI allows different evaluation techniques such as benchmarking, human evaluation and A/B testing. Benchmarking in evaluation is a standard process of comparing the performance of an LLM against a certain established benchmark. These benchmarks are designed to assess important capabilities such as text generation, question answering, translation and language understanding.
Human evaluation, on the other hand, involves human experts or users to assess the quality of LLM outputs. This approach is essential for tasks requiring subjective judgement, such as creativity, factual accuracy, relevance or coherence. A/B testing is another evaluation method, that is, a controlled experiment involving two versions of an LLM to determine which performs better.
Collaboration and Teamwork in LLM development are another set of important features provided under Literal AI. These functionalities comprise shared workspace and versioning. A shared workspace is a centralised feature where different users can collaborate on LLM projects, providing a common ground for shared access and real-time collaboration whereas, versioning allows tracking of modifications and changes over time, allowing teams to manage multiple versions, experiment with different approaches and apply code merging seamlessly.
Literal AI allows users to improve their LLM applications over time with continuous improvement. Since Literal AI consists of different evaluation techniques, users need to first establish a robust evaluation framework based on the required evaluation level, evaluation metrics and methods.
Once the building of an evaluation framework is complete, the user can now work on the improvement process based on pre-production iteration, production monitoring and evaluation based on human review, annotation queues, feedback loops, etc. This can further be used under the continuous improvement cycle (CI/CD) integration.
Once the integration is complete, the users can use different global metrics offered through Literal AI UI with ease and assess the overall impact of LLM application for future improvements.
Let’s implement RAG observability and evaluation through Literal AI based on LlamaIndex integration.
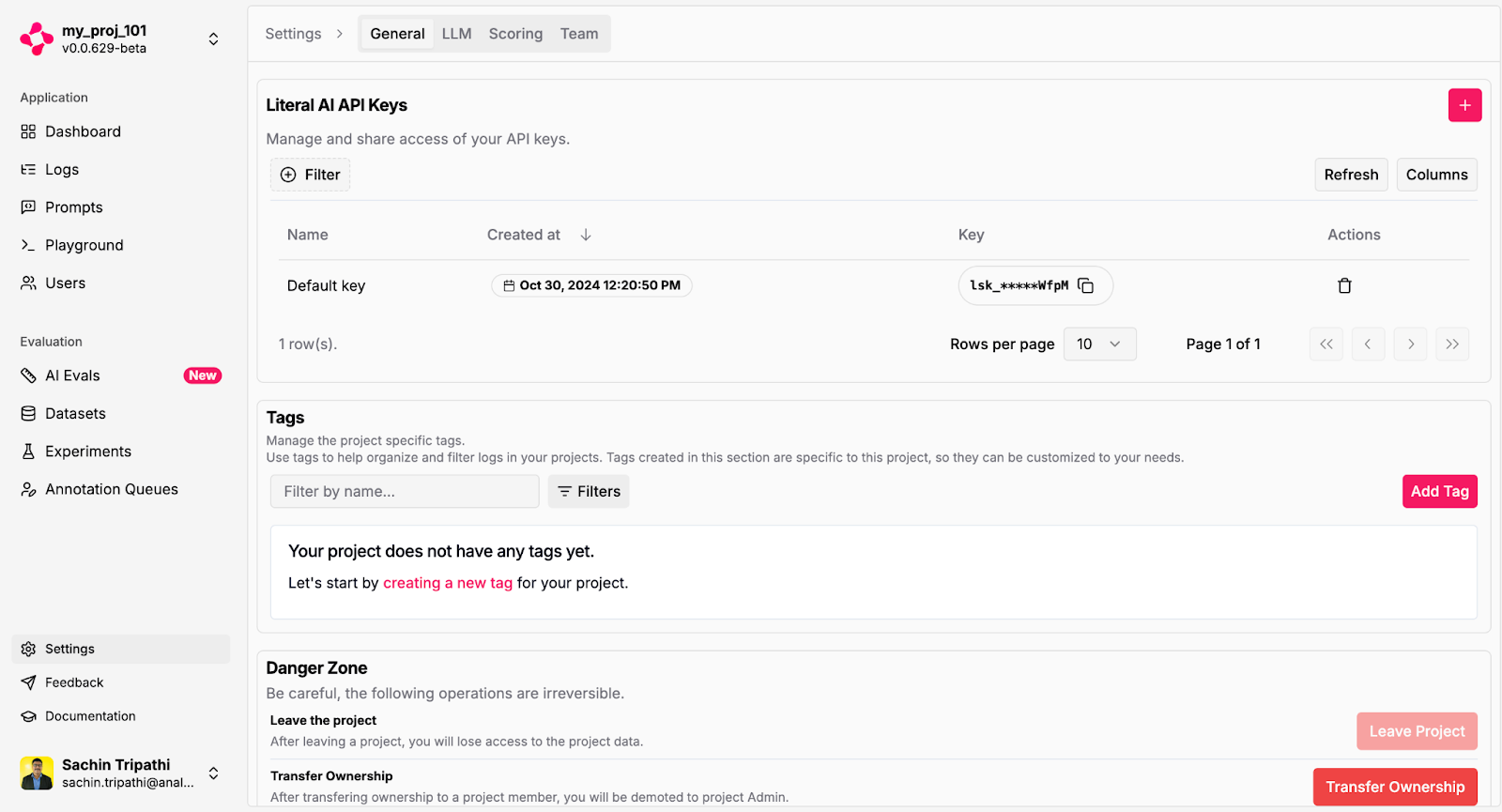
Step 1: Create an account on Literal AI’s website (https://literalai.com/) and generate an API key which will be used for observing and evaluating our RAG pipeline –
Step 2: Create a RAG pipeline using your data through LlamaIndex based on Groq’s llama3-8b-8192 model and HuggingFace embedding BAAI/bge-small-en-v1.5 –
Step 2.1: Installing libraries –
%pip install -qU llama-index llama-index-llms-groq llama-index-embeddings-huggingface literalaiStep 2.2: Importing libraries –
from llama_index.core import (
Settings,
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.groq import Groq
from literalai import LiteralClient
from google.colab import userdata
import osStep 2.3: Initialising API’s –
os.environ['GROQ_API_KEY'] = userdata.get('GROQ_API_KEY')
os.environ['LITERAL_API_KEY'] = userdata.get('LITERAL_API_KEY')Step 2.4: Configuring LlamaIndex settings –
llm = Groq(model = "llama3-8b-8192")
embed_model = HuggingFaceEmbedding(model_name = "BAAI/bge-small-en-v1.5")
Settings.llm = llm
Settings.embed_model = embed_modelStep 2.5: Setting Literal AI’s client instrument for LlamaIndex –
client = LiteralClient()
client.instrument_llamaindex()Step 2.6: Loading and indexing data –
documents = SimpleDirectoryReader("data/").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()Step 2.7: Creating RAG threads, a collection of runs that are part of a single conversation, for logging on Literal AI. Here we are creating four different threads having multiple questions.
with client.thread(name="My thread 101") as thread:
query_engine.query("What is the data talking about?")
query_engine.query("What is the designation of Ned Stark?")
with client.thread(name="My thread 102") as thread:
query_engine.query("Who wants to assassinate Daenerys Targaryn?")
query_engine.query("Who needs bloodmagic for geting saved?")
with client.thread(name="My thread 103") as thread:
query_engine.query("What are the names of Ned Stark’s five children, and which pup do they each get?")
query_engine.query("Who is the reigning king in Westeros at the start of the series, and how does he know Ned Stark?")
query_engine.query("Who is Khal Drogo, and why is Daenerys married to him?")
with client.thread(name="My thread 104") as thread:
query_engine.query("Which House holds Winterfell?")Output: Literal AI’s web UI will log our threads with the entire trace –


We can check individual thread traces by selecting them –


Step 3: Let’s create a scoring evaluation based on human feedback using two categories – Correct (1) and Incorrect (0). Select a thread and click on add scores to create a score schema –


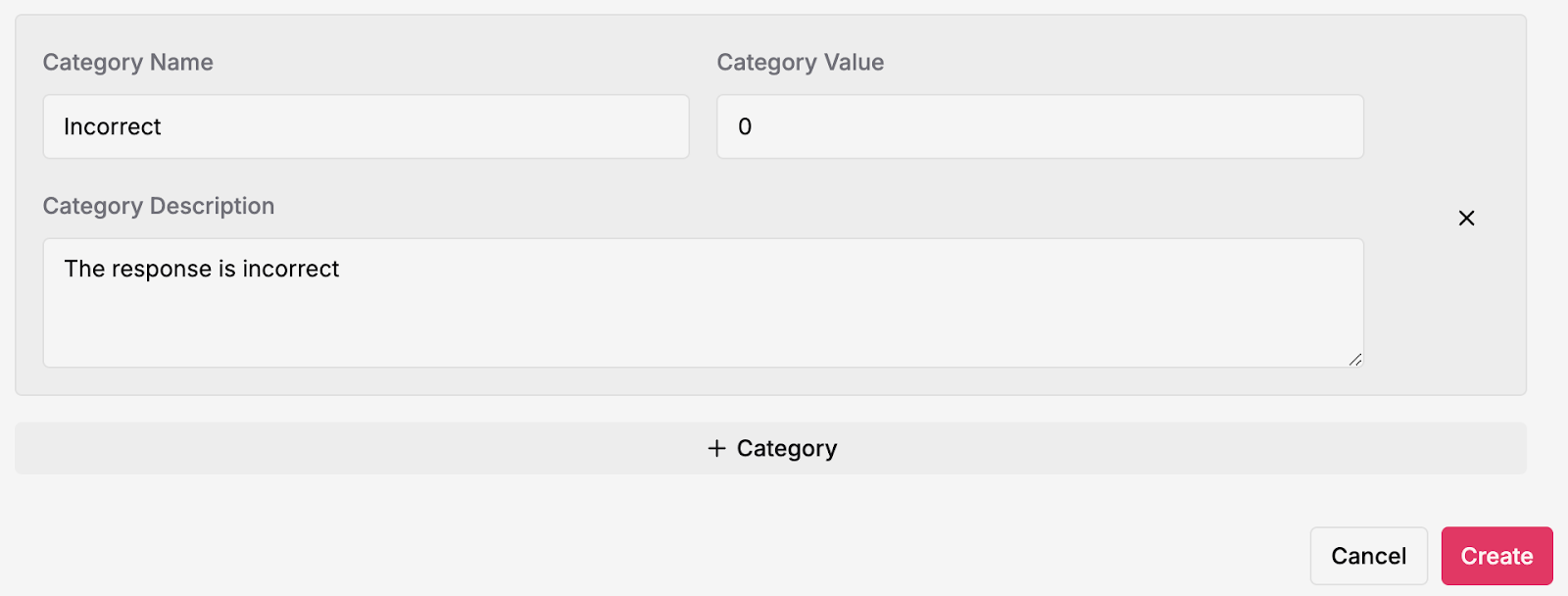

Output: Once the score is set, crosscheck the thread and see if the score is applied –


Literal AI emerges as a powerful tool for users seeking a comprehensive suite of LLM observability, evaluation, tracing and collaborative functionalities. It can enable users to trace their RAG pipelines based on different LLMs, rigorously test and evaluate models to ensure consistent and reliable outputs and streamline workflows to reduce development times. Observing and evaluating LLMs is still a big challenge in LLM development, but Literal AI can assist and support users in providing important functionalities in the aforementioned domains.





