
Colpali presents a novel approach to improving document retrieval by leveraging Vision-Language Models (VLMs) for extracting insights from PDFs. Instead of using traditional methods like OCR or document segmentation, it embeds entire page images directly. This method utilizes advanced techniques like Vision Transformers and late interaction mechanisms, which enhance querying efficiency and semantic matching. Colpali streamlines both indexing and retrieval processes, optimizing the retrieval pipeline for real-time document analysis and search tasks, all while reducing errors typically encountered with traditional methods.
Colpali revolutionizes document retrieval by harnessing the power of Vision-Language Models (VLMs) to extract insights directly from PDF page images. By embedding entire pages as image representations, it eliminates the need for traditional OCR and document segmentation, which are prone to errors and inefficiencies. Leveraging advanced models like PaliGemma and late interaction mechanisms, Colpali enhances semantic matching and retrieval accuracy. This approach simplifies indexing while optimizing query processing, offering a streamlined and robust solution for real-time document analysis and search tasks.
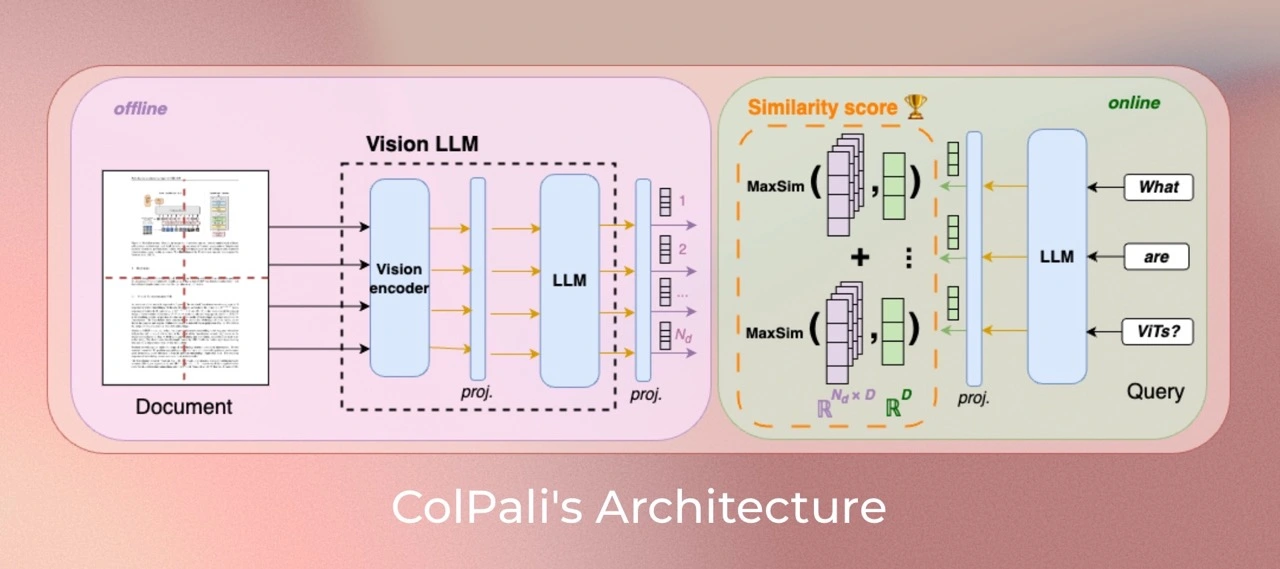
Colpali’s Architecture
Before diving into our document analysis system, we need to set up Qwen2, a powerful large language model designed for multimodal tasks. Qwen2 serves as the backbone of our system, capable of understanding both text and visual information with remarkable accuracy. We’ll be using the 1.5B-Instruct variant, which offers an excellent balance between performance and resource efficiency. The model comes pre-optimized with Flash Attention 2.0 technology, ensuring faster processing speeds and reduced memory usage – crucial features for handling complex document analysis tasks.
Step 1: Installing Dependencies
Let’s start by installing all necessary packages:
# Install core requirements
pip install -qU byaldi
pip install -qU accelerate
pip install -qU flash_attn
pip install -qU qwen_vl_utils
pip install -qU pdf2image
# Install transformers from source
python -m pip install git+https://github.com/huggingface/transformers
# Install system dependencies
sudo apt-get update
apt-get install poppler-utilsStep 2: Setting Up the Models
Import required libraries and initialize our models:
from byaldi import RAGMultiModalModel
from transformers import Qwen2VLForConditionalGeneration
import torch
from pdf2image import convert_from_path
# Initialize the RAG model
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali")
# Initialize Qwen model with optimizations
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-1.5B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="cuda"
)Step 3: Document Indexing
Index your PDF document for efficient information retrieval:
# Index the PDF document
RAG.index(
input_path="/content/bh1.pdf", # Replace with your PDF path
index_name="multimodal_rag",
store_collection_with_index=False,
overwrite=True
)
# Perform search for "Skilling Programme"
text_query = "Skilling Programme"
results = RAG.search(text_query, k=3)
# Print search results
print(results)Output
[{'doc_id': 0, 'page_num': 5, 'score': 15.3125, 'metadata': {}, 'base64': None},
{'doc_id': 0, 'page_num': 3, 'score': 13.1875, 'metadata': {}, 'base64': None},
{'doc_id': 0, 'page_num': 7, 'score': 11.4375, 'metadata': {}, 'base64': None}]Step 4: Image Extraction and Processing
Extract and save the relevant image from the PDF:
# Convert PDF to images
images = convert_from_path("/content/bh1.pdf") # Replace with your PDF path
# Get the specific page based on search results
image_index = results[0]["page_num"] - 1
# Save the relevant image
images[image_index].save('image1.jpg')
from IPython.display import Image,display
display(images[image_index])Output
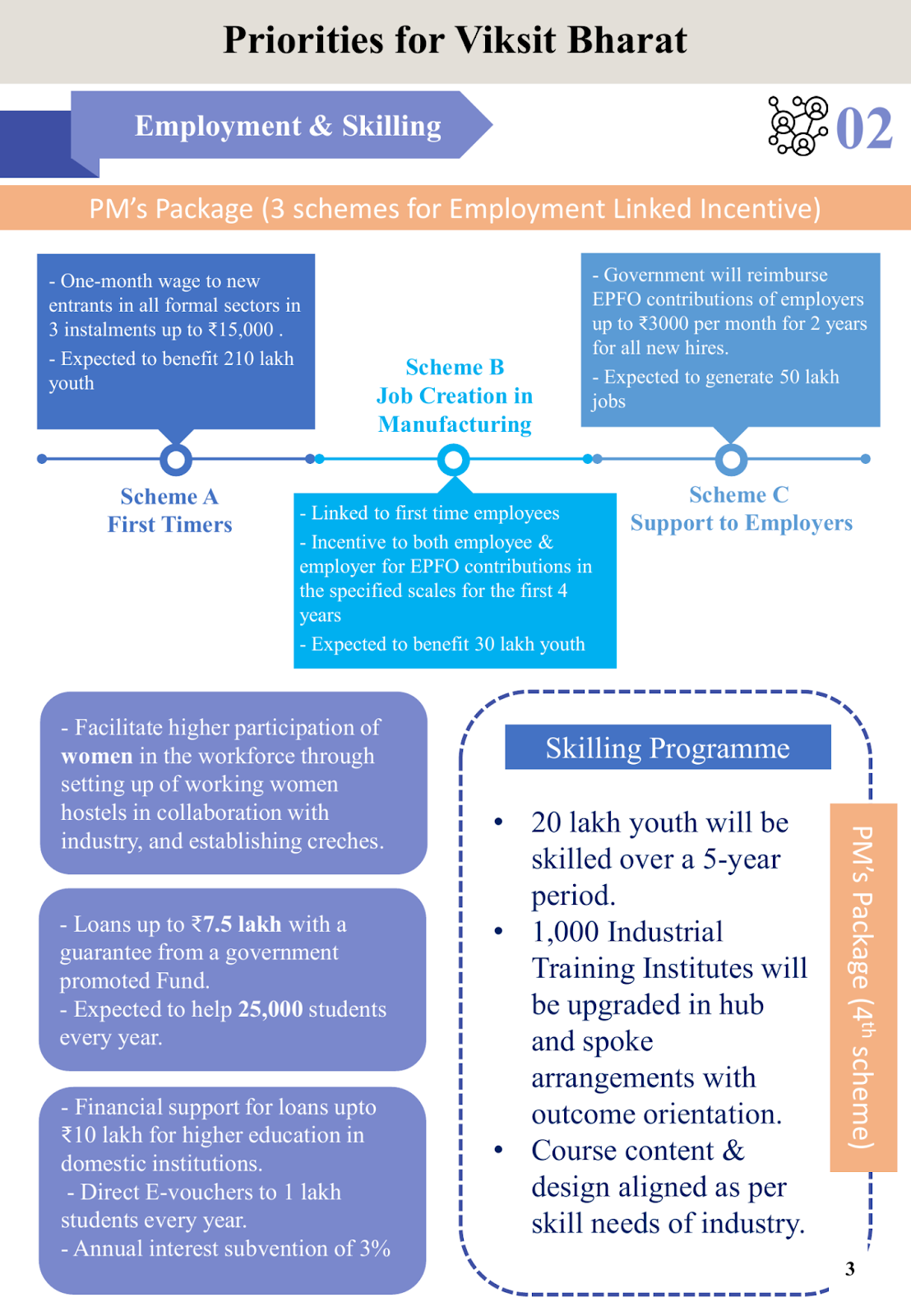
Step 5: Setting Up Vision Analysis
Install additional requirements and set up the Groq client for vision analysis:
# Install required packages
pip install tiktoken
pip install -qU groq
# Set up Groq client
import groq
from groq import Groq
import base64
# Configure API key
import os
os.environ["GROQ_API_KEY"] = "your_groq_api_key" # Replace with your API key
client = Groq()Step 6: Image Analysis Implementation
Create the image analysis pipeline:
# Function to encode images
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Encode the saved image
image_path = "/content/image1.jpg"
base64_image = encode_image(image_path)
# Create chat completion with both text and image
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": text_query},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
}
],
model="llama-3.2-11b-vision-preview"
)
# Print the analysis results
print(chat_completion.choices[0].message.content)Output
To develop and upgrade the skills of the workforce, the Government launched the Skill Development Programme to provide training and employment opportunities for individuals across various sectors.
**Key Objectives:**
* Support for apprentices
* Encourage youth to develop skills over a five-year period
* Improve job opportunities in the manufacturing sector
**Programme Components:**
* **Skill Development Program**: Up to 1 lakh students will be trained every year
* **Employment and Skilling**: One-month wage to new entrants in all formal sectors in 3 metropolitan areas (1 lakh youth)
* **Focus Areas**: Job creation in Manufacturing, Support to Employers, and Skill Development
**Benefits:**
* Loans up to 7.5 lakh with a guarantee from a government-promoted fund
* Financial support for loans up to 10 lakh for education in domestic institutions
* Automatic interest subvention of 3%
* Direct E-vouchers to 1 lakh students every year
* Annual interest subvention of 3% targeted for loans up to 10 lakh for higher education in domestic institutions
**Industry Support:**
* Industrial Training Institutes to be upgraded in hub and spoke arrangements with outcome orientation
* Course content and design aligned as per skill needs of industry
**Overall Impact:**
The Skilling Programme aims to develop and upgrade the skills of the workforce, particularly targeting youth and women. It provides financial support for education and training, and encourages individuals to develop skills over a five-year period. The programme's objectives are to create job opportunities in the manufacturing sector, support employers, and develop skills that meet the needs of industry.This implementation showcases the synergy between cutting-edge technologies in modern document analysis. By combining Colpali’s multimodal RAG capabilities with Qwen2’s advanced language processing and Groq’s vision analysis, we’ve created a versatile document intelligence system. The seamless integration of PDF processing, text retrieval, and image analysis demonstrates how enterprise-level document understanding can be achieved through well-orchestrated AI components.




![[Upcoming Webinar] MCP and A2A – The AI Protocols for Next-Gen Agent Ecosystems](https://adasci.org/wp-content/uploads/2025/04/adasci-featured-300x300.png)

