
Retrieval Augmented Generation (RAG) needs no introduction in the domain of large language models but its application to vision language modes is untapped. RAVEN is a newly researched framework which enhances vision language models through task-specific fine-tuning. RAVEN is implemented by integrating retrieval augmented samples without the need for additional retrieval-specific parameters which shows that the model acquires retrieval properties that are effective across multiple tasks. This article explores RAVEN and its underlying methodology.
Vision-Language Models (VLMs)
VLMs are designed to process both visual and textual data, enabling them to perform tasks like image captioning, visual question answering (VQA), and more. VLMs combine computer vision, which deals with visual interpretation of data, and natural language processing, which focuses on understanding and generating human language. This combination employs the use of a vision encoder, language encoder and a fusion layer.
Vision encoder analyzes the image, extracting features and turning them into numerical representations. Language encoder processes the textual input, transforming it into a similar numerical format thereby, capturing the meaning and intent conveyed by the words. The fusion layer, lastly, uses complex techniques such as attention mechanisms, on the merged encodings from both the image and text, allowing the VLM to understand the relationship between them.
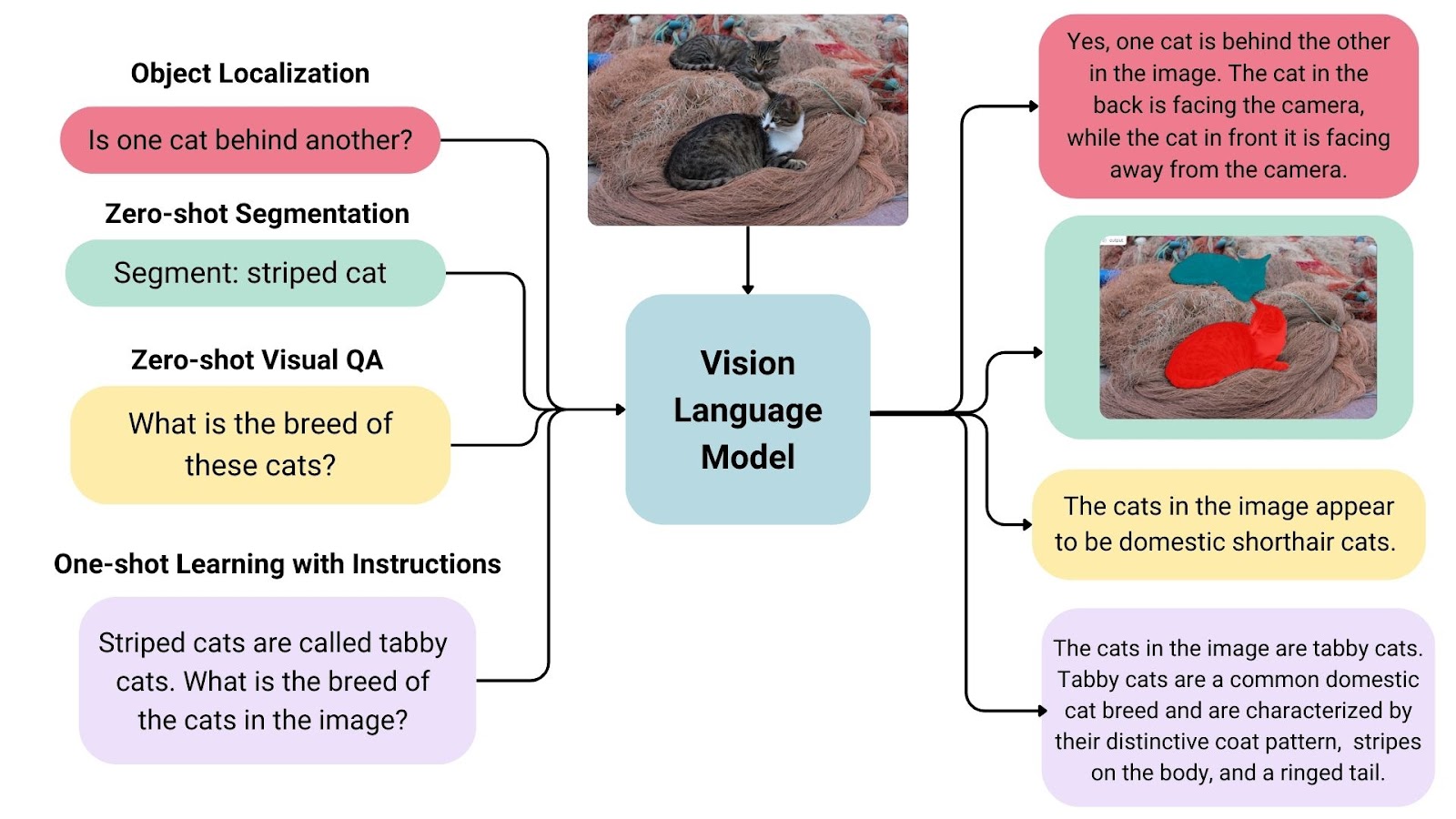
By understanding both images and text together, VLMs learn the relationship between them. This enables them to perform tasks like image captioning, or visual question answering.
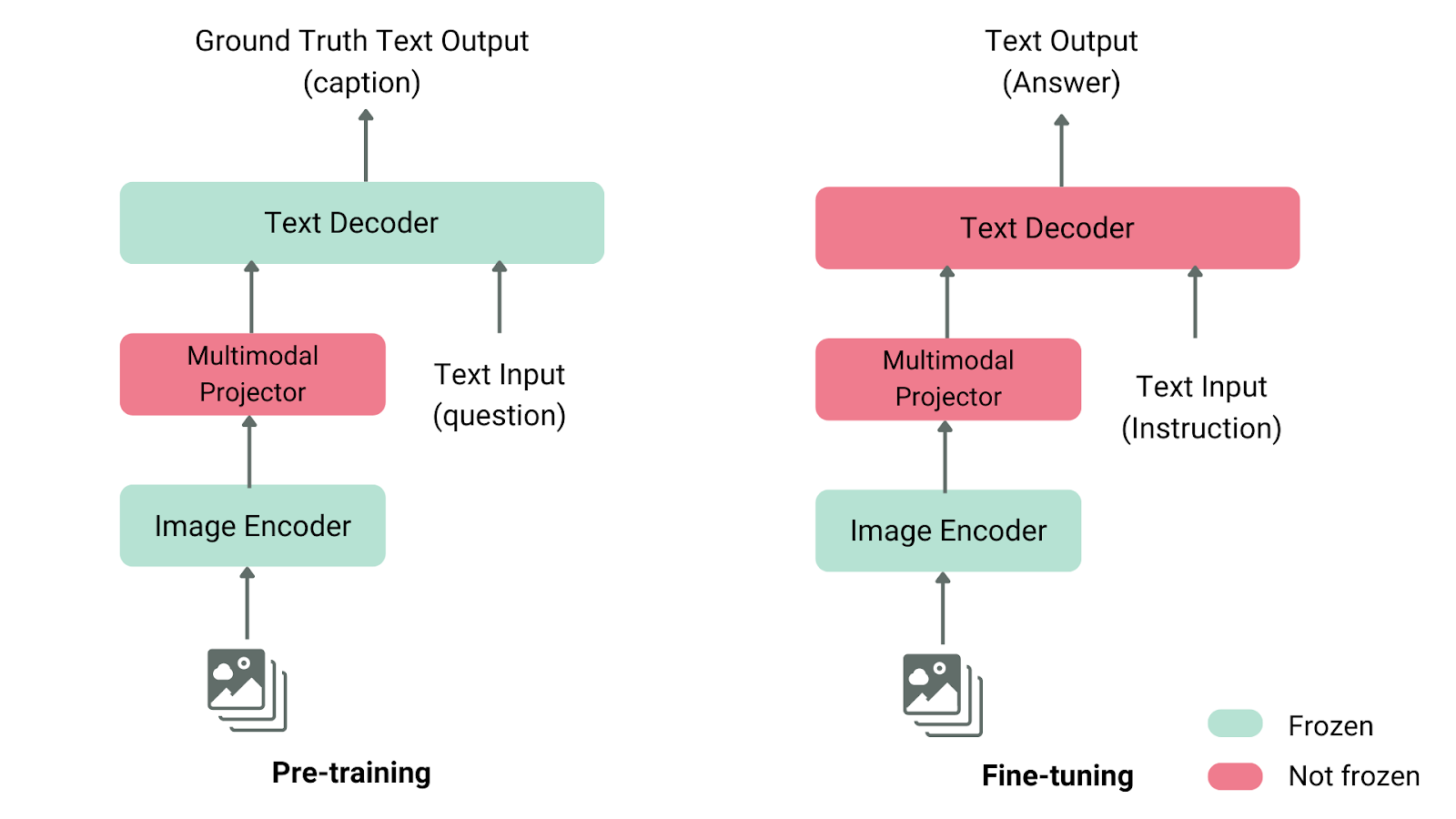
Models such as OFA, SimVLM, and BLIP have demonstrated considerable potential in these areas. However, they often require extensive resources for training and may lack the flexibility needed to handle diverse tasks effectively.
Retrieval-Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is an AI framework that improves the quality of generative AI by integrating external knowledge, enabling large-scale language models (LLM) to provide more accurate and contextually relevant answers. RAG combines information with text generation, allowing AI systems to use up-to-date and verifiable information from external sources without constant retraining.
The process includes a retrieval phase, where relevant information is obtained from external sources, and a content production phase, where this information is integrated into a language model to provide expert and meaningful responses.
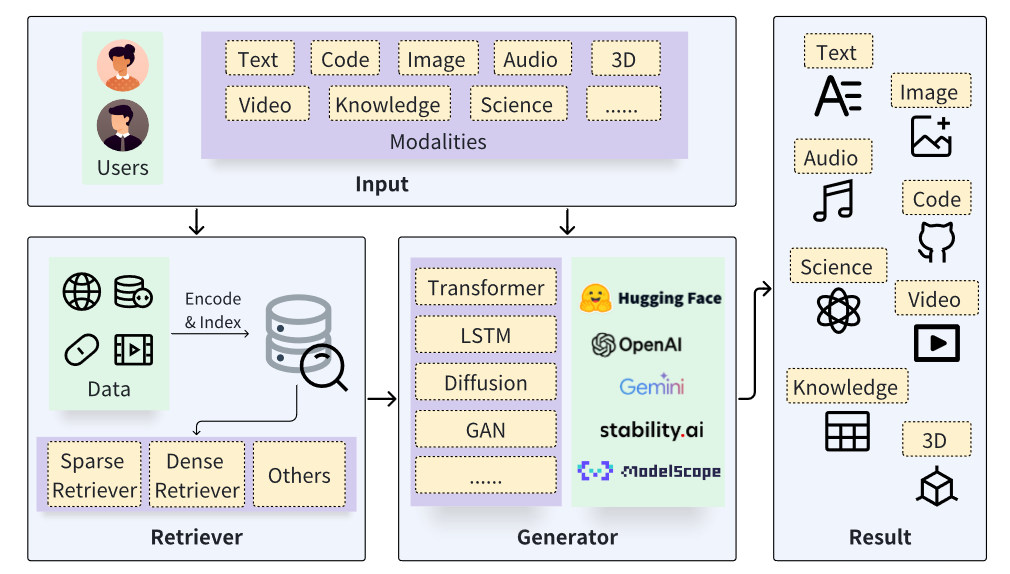
RAG enhances models by retrieving relevant external information, thereby improving their performance without expanding their parameter count. In the context of VLMs, this involves retrieving pertinent image-text pairs from a large external memory based on the input query, which can then be used to inform the model’s output.
RAVEN Framework
RAVEN stands for Retrieval-Augmented Vision-language Enhanced. This framework adapts the RAG approach specifically for multitask VLMs, integrating retrieved samples into the model’s processing pipeline. This enhancement allows the model to perform a variety of tasks more effectively. Crucially, RAVEN achieves this through task-specific fine-tuning rather than adding retrieval-specific parameters, thus maintaining efficiency and adaptability.
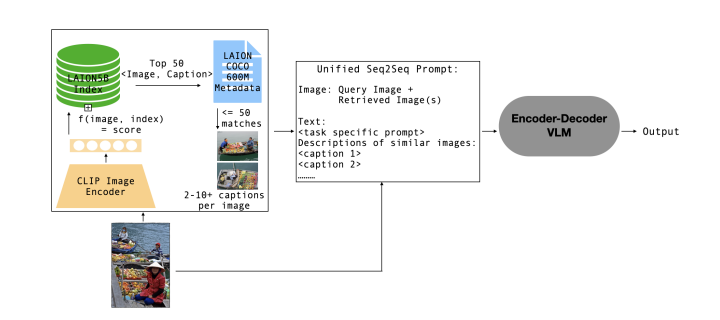
Multimodal Retrieval System
RAVEN employs the FAISS library, a tool for high-dimensional vector indexing, to retrieve relevant image-text pairs from extensive datasets like LAION-5B. The retrieval process is optimized for relevance, diversity, and consistency in style with the target datasets, ensuring that the retrieved samples are both relevant and useful.
Base Vision-Language Model
The framework utilizes OFA, a multitask encoder-decoder model renowned for its efficiency in handling diverse vision-language tasks. OFA encodes input images and text, and then decodes the retrieved context along with the query to generate the final output.
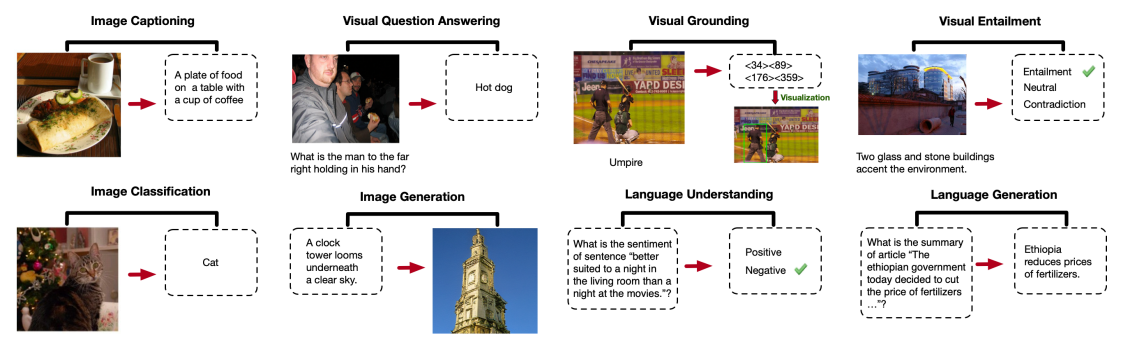
Examples of OFA Supported Tasks
Task-Specific Fine-Tuning
RAVEN fine-tunes the base VLM on specific tasks using retrieval-augmented samples. This approach enhances the model’s retrieval capabilities and applies them across multiple tasks without necessitating additional parameters. This fine-tuning is done on tasks such as image captioning and VQA to ensure the model’s enhanced performance is applicable to real-world scenarios.
RAVEN was rigorously tested on two primary vision-language tasks: image captioning and visual question answering (VQA). The framework demonstrated significant improvements over traditional non-retrieval baselines:
Image Captioning
On the MSCOCO dataset, RAVEN achieved a +1 CIDEr score improvement, a notable enhancement given the benchmark’s stringent evaluation criteria. On the NoCaps dataset, the improvement was even more pronounced, with a +4 CIDEr score increase, indicating RAVEN’s ability to handle diverse and challenging image captioning scenarios.’

Examples of retriever output based on query image
Visual Question Answering (VQA)
RAVEN exhibited a nearly +3% increase in accuracy on specific question types, underscoring its capability to effectively retrieve and integrate relevant information to answer complex visual questions accurately.
These results highlight RAVEN’s effectiveness in leveraging retrieval augmentation to enhance performance across different vision-language tasks. The improvements were achieved with fewer parameters compared to previous methods, showcasing the framework’s efficiency and potential for scalability.
The introduction of RAVEN marks a significant advancement in the application of retrieval-augmented techniques to vision-language models. Its multitask framework offers several key advantages:
RAVEN’s multitask retrieval-augmented learning framework presents a promising direction for future research in vision-language models. Its ability to enhance performance efficiently and sustainably positions it as a valuable tool for advancing multimodal AI systems. The framework’s effectiveness in leveraging external knowledge sources to improve task performance without expanding parameter count sets a new standard for VLMs. As the field continues to explore the integration of external knowledge sources, RAVEN’s approach provides a robust foundation for developing more capable and resource-efficient vision-language models.
By addressing the limitations of traditional VLMs and introducing an innovative retrieval-augmented approach, RAVEN paves the way for the next generation of AI systems that are both powerful and sustainable. Its impact on the field of vision-language processing is poised to be significant, offering new possibilities for applications that require the seamless integration of visual and textual information.
Learn more about Generative AI and Large Language Models through our hand-picked modules:









