
Tokenization has long been the cornerstone of large language models (LLMs), but it introduces limitations in efficiency, robustness, and multilingual equity. Enter the Byte Latent Transformer (BLT), a revolutionary tokenizer-free architecture that learns directly from raw byte data. BLT matches token-based LLMs in performance while surpassing them in inference efficiency and robustness. In this article, we explore how BLT achieves this breakthrough, its key features, implementation details, and practical applications.
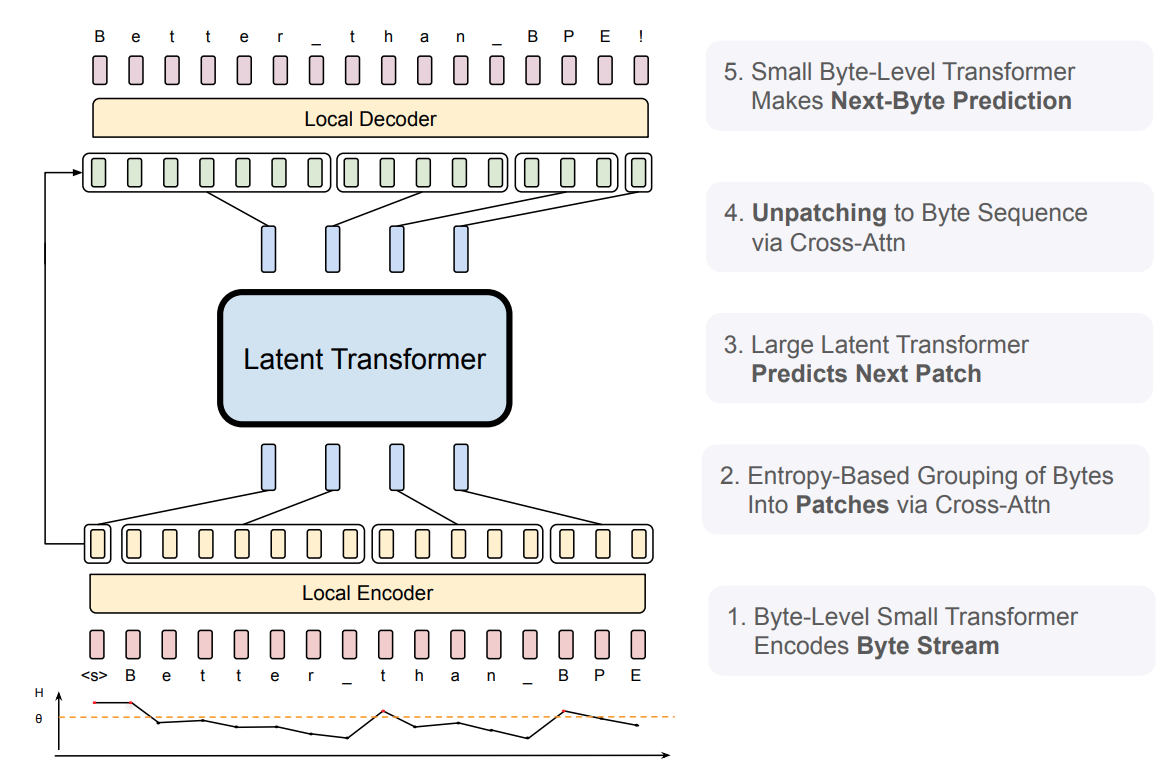
The Byte Latent Transformer is a novel architecture that dynamically groups bytes into patches, enabling efficient computation at scale. Unlike token-based models, BLT does not rely on fixed vocabularies, mitigating issues like input noise sensitivity and language biases. Its design introduces a new scaling axis—simultaneously increasing patch and model size—without additional inference costs.
Traditional LLMs allocate equal compute to all tokens, leading to inefficiencies. BLT’s dynamic patching allows compute allocation based on data complexity, resulting in a more robust model. This approach is particularly valuable in tasks requiring long-tail generalisation and noise handling.

Comparing Efficiency in LLMs
BLT segments raw bytes into entropy-based patches, ensuring computational resources are allocated where needed most. This approach reduces inference costs significantly compared to traditional token-based models.
BLT’s patching eliminates the need for tokenization, allowing it to directly model byte-level data. This results in improved robustness against noisy inputs and better handling of multilingual and domain-specific data.
BLT demonstrates superior scaling properties, maintaining performance parity with state-of-the-art token-based models like LLaMA 3 while offering up to 50% inference efficiency improvements.

Key Features of BLT
Data Preparation:
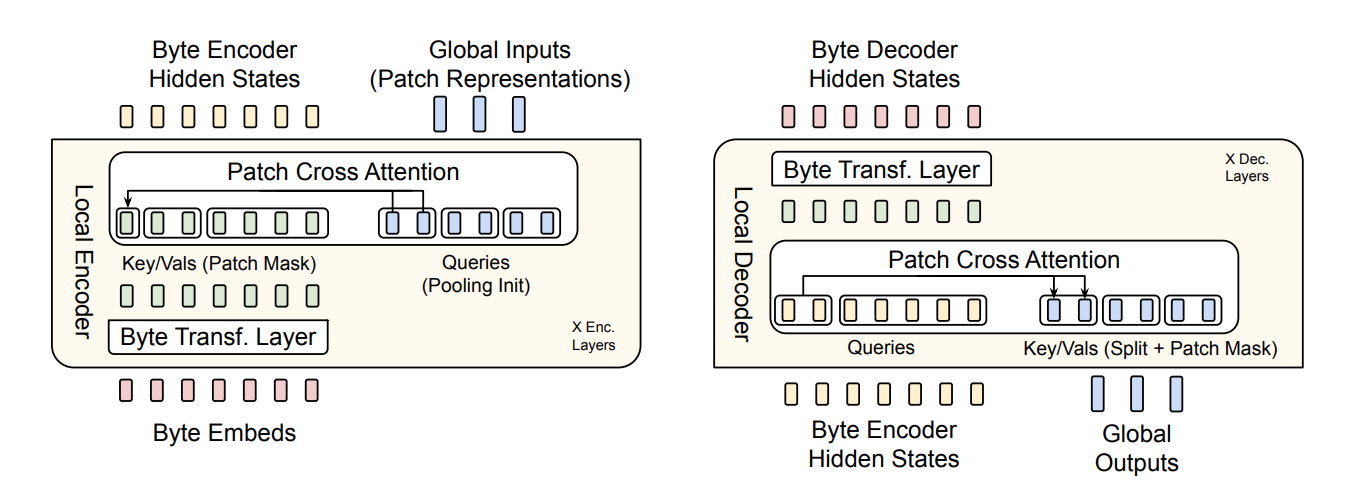
Model Architecture:
Training Configuration:
BLT’s flexibility and efficiency open up numerous applications:
Entropy-Based Patching:
Model Components:
Efficiency Optimization:
The Byte Latent Transformer redefines efficiency and scalability. Its innovative approach to dynamic byte patching and token-free modeling makes it a game-changer, especially for applications demanding robustness and low inference costs. As BLT continues to evolve, it promises to unlock new possibilities for large-scale language models.




