
Large Language Models (LLMs) have changed how we work with data. While these AI tools are powerful, they usually require sending data to external servers – a major concern when dealing with sensitive information. Think about it: No company wants to share confidential data with third-party servers. Yet, traditional search methods, which simply match keywords, often fall short of finding exactly what we need. We need something better – a solution that combines AI’s intelligence with local security. This is where Ollama comes in. In this guide, we’ll show you how to build a search engine that keeps your data on your own computers, Understands questions in plain language, Finds precise answers from your documents, Protects your sensitive information. Let’s explore how to make AI search both smart and secure.
Let’s start with understanding what exactly local search engines are.
Local search engines powered by Large Language Models (LLMs) are revolutionizing how we find and use information on our computers. Unlike traditional online search tools, these AI-powered engines work entirely offline, allowing users to search their personal documents instantly without internet connectivity. They act like a smart personal assistant who understands natural language queries, grasps context, and finds exactly what you need from your files – all while keeping your data private and secure on your own computer.
This combination of advanced AI understanding and local processing makes them particularly valuable for professionals handling sensitive information, researchers working with private documents, or anyone who needs quick, secure access to their personal data. Whether you’re looking for specific details in meeting notes, searching through confidential reports, or simply wanting faster access to your files, local AI search offers a smarter, more secure way to work with your information.
Step 1: Setting Up Your Environment:
First, ensure you have the necessary libraries installed. You can install them using pip:
pip install numpy faiss-cpu sentence-transformers streamlit ollama Pillow python-docx python-pptx PyMuPDFAlso get Ollama up and running on your PC. Follow the instructions from the ADaSci’s blog’s “Hands-On Guide to Running LLMs Locally using Ollama“. Once you’ve completed the installation successfully, Ollama should be running on your PC this is essential for building your own Search Engine. You’ll be able to interact with it locally through your command prompt.
After installation, it should look something like this:
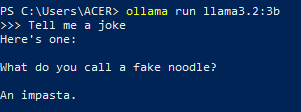
Step 2: Structuring Your Code:
Create a new Python file, for example, local_search.py, and start by importing the necessary modules.
import os
import json
import logging
from typing import List, Dict, Any, Optional, Tuple, Set
from pathlib import Path
from dataclasses import dataclass
import numpy as np
import faiss
from sentence_transformers import SentenceTransformer
import streamlit as st
import ollama
from PIL import Image
import fitz
from docx import Document
from pptx import Presentation
import io
from functools import lru_cache
from concurrent.futures import ThreadPoolExecutor, as_completed
import reThis code imports the required libraries for file handling, data processing, and creating a web interface. Each library serves a specific purpose, such as reading different document formats or handling embeddings.
Step 3: Configure Logging:
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)This sets up a basic logging configuration to output information and error messages, which helps in troubleshooting.
Step 4: Define Constants
Let’s set some constants that will be used throughout the application.
# Constants
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50
MODEL_NAME = 'sentence-transformers/all-MiniLM-L6-v2' # Faster, lighter model
INDEX_PATH = "document_index.faiss"
METADATA_PATH = "metadata.json"
MAX_WORKERS = 4 # Adjust based on your CPU coresThese constants define the chunk size for document processing, the model to be used for embeddings, and paths for saving the index and metadata.
Step 5: Create the DocumentProcessor Class
This class will handle all operations related to document processing, including indexing and searching.
@dataclass
class SearchResult:
id: int
path: str
content: str
score: float
class DocumentProcessor:
def __init__(self):
self.model = SentenceTransformer(MODEL_NAME)
self.dimension = self.model.get_sentence_embedding_dimension()
self.index = None
self.metadata: List[Dict[str, Any]] = []
self._initialize_index()
# Cache for document content
self.document_cache = {}Here SearchResult is a data class to hold the search results and DocumentProcessor Initializes the sentence transformer model and sets up an index for document embeddings.
Step 6: Initialize the Index
We need to create or load an existing FAISS index for fast retrieval.
def _initialize_index(self):
"""Initialize or load existing FAISS index"""
try:
if os.path.exists(INDEX_PATH) and os.path.exists(METADATA_PATH):
self.index = faiss.read_index(INDEX_PATH)
with open(METADATA_PATH, 'r') as f:
self.metadata = json.load(f)
logger.info("Loaded existing index and metadata")
else:
self.index = faiss.IndexFlatIP(self.dimension)
logger.info("Created new index")
except Exception as e:
logger.error(f"Error initializing index: {e}")
self.index = faiss.IndexFlatIP(self.dimension)
@lru_cache(maxsize=1000)
def chunk_text(self, text: str) -> List[str]:
"""Split text into manageable chunks with caching"""
words = text.split()
chunks = []
for i in range(0, len(words), CHUNK_SIZE - CHUNK_OVERLAP):
chunk = ' '.join(words[i:i + CHUNK_SIZE])
chunks.append(chunk)
return chunks This function checks if an index already exists. If it does, it loads it; otherwise, it creates a new index.
Step 7: Process Files and Index Documents
We need to read various document types and convert them into chunks that can be indexed.
def process_file(self, file_path: str) -> tuple:
"""Process a single file and return its chunks and metadata"""
content = self.read_file(str(file_path))
if not content:
return [], []
chunks = self.chunk_text(content)
file_metadata = [
{"path": str(file_path), "chunk_id": i}
for i in range(len(chunks))
]
return chunks, file_metadataThis method reads a file, splits it into manageable chunks, and prepares metadata for each chunk.
Step 8: Read Files of Various Formats
We will implement a function to read content from different document formats like text, PDF, DOCX, and PPTX.
def read_file(self, file_path: str) -> str:
"""Read content from different file types with caching"""
if file_path in self.document_cache:
return self.document_cache[file_path]
try:
ext = Path(file_path).suffix.lower()
content = ""
if ext == '.txt':
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
elif ext == '.pdf':
with fitz.open(file_path) as doc:
content = " ".join(page.get_text() for page in doc)
elif ext == '.docx':
doc = Document(file_path)
content = " ".join(p.text for p in doc.paragraphs)
elif ext == '.pptx':
prs = Presentation(file_path)
content = " ".join(shape.text
for slide in prs.slides
for shape in slide.shapes
if hasattr(shape, "text"))
self.document_cache[file_path] = content
return content
except Exception as e:
logger.error(f"Error reading file {file_path}: {e}")
return "This function checks the file extension and reads the content accordingly, caching it for efficiency.
Step 9: Index Documents from a Directory
Now we will create a method to index all documents from a specified directory.
def index_documents(self, directory: str) -> bool:
"""Index documents from directory using parallel processing"""
try:
# Collect all valid files
file_paths = []
for ext in ['.txt', '.pdf', '.docx', '.pptx']:
file_paths.extend(Path(directory).rglob(f'*{ext}'))
if not file_paths:
st.warning("No supported documents found")
return False
# Process files in parallel
documents = []
self.metadata = []
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
future_to_file = {
executor.submit(self.process_file, str(file_path)): file_path
for file_path in file_paths
}
for future in as_completed(future_to_file):
chunks, file_metadata = future.result()
documents.extend(chunks)
self.metadata.extend(file_metadata)
if not documents:
st.warning("No content extracted from documents")
return False
# Create embeddings in batches
batch_size = 32 # Adjust based on your memory
all_embeddings = []
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
embeddings = self.model.encode(
batch,
show_progress_bar=False,
batch_size=batch_size
)
all_embeddings.append(embeddings)
embeddings = np.vstack(all_embeddings)
# Create and save index
self.index = faiss.IndexFlatIP(self.dimension)
self.index.add(embeddings.astype('float32'))
# Save index and metadata
faiss.write_index(self.index, INDEX_PATH)
with open(METADATA_PATH, 'w') as f:
json.dump(self.metadata, f)
st.success(f"Indexed {len(documents)} text chunks from {len(file_paths)} files")
return True
except Exception as e:
logger.error(f"Indexing error: {e}")
st.error(f"Error during indexing: {str(e)}")
return FalseThis function collects files from the directory, processes them in parallel, and indexes the content. If no files are found, it displays a warning in the Streamlit app.
Step 10: Implement the Search Functionality
Let’s create a method to search for relevant documents based on user queries.
@lru_cache(maxsize=100)
def search(self, query: str, k: int = 5) -> List[SearchResult]:
"""Search for relevant documents with caching"""
try:
if not self.index or self.index.ntotal == 0:
st.warning("No documents indexed yet")
return []
# Encode query and search
query_vector = self.model.encode([query])[0]
distances, indices = self.index.search(
query_vector.reshape(1, -1).astype('float32'),
min(k, self.index.ntotal)
)
# Process results
results = []
for i, idx in enumerate(indices[0]):
if idx < len(self.metadata):
meta = self.metadata[idx]
try:
content = self.read_file(meta["path"])
chunks = self.chunk_text(content)
chunk_content = chunks[meta["chunk_id"]] if meta["chunk_id"] < len(chunks) else ""
results.append(SearchResult(
id=int(idx),
path=meta["path"],
content=chunk_content,
score=float(distances[0][i])
))
except Exception as e:
logger.error(f"Error reading chunk: {e}")
continue
return results
except Exception as e:
logger.error(f"Search error: {e}")
st.error(f"Error during search: {str(e)}")
return []This method encodes the user’s query, searches the index, and retrieves the most relevant documents along with their metadata.
Step 11: Generate Answers Using Context
We will now implement a function to generate answers based on the search results using the Ollama model.
@lru_cache(maxsize=100)
def generate_answer(query: str, context: str) -> Tuple[str, Set[int]]:
"""
Generate answer using Ollama with caching and return referenced citations
Args:
query (str): The user's question
context (str): The context information from documents
Returns:
Tuple[str, Set[int]]: A tuple containing the generated answer and a set of citation indices
"""
try:
prompt = f"""
Answer based on the context below. Be concise.
You must cite your sources using [0], [1], etc. for EVERY claim you make.
Make sure to use the citations explicitly in your answer.
Context:
{context}
Question: {query}
Answer:"""
response = ollama.generate(
model='llama3.2:3b',
prompt=prompt
)
answer = response['response']
# Extract citation numbers from the answer
citations = set(int(num) for num in re.findall(r'\[(\d+)\]', answer))
return answer, citations
except Exception as e:
logger.error(f"Answer generation error: {e}")
return "Sorry, I couldn't generate an answer at this time.", set()This function constructs a prompt using the context and query, utilizes the Ollama model to generate answers, and caches results to optimize performance.
Step 12: Create the Streamlit User Interface
Finally, let’s set up a user-friendly interface using Streamlit.
def main():
st.set_page_config(page_title="Local Search", layout="wide")
# Initialize processor
if 'processor' not in st.session_state:
st.session_state.processor = DocumentProcessor()
# Simple UI
st.title("Local Document Search")
# Document indexing
docs_path = st.text_input("Documents folder path:")
if st.button("Index Documents") and docs_path:
with st.spinner("Indexing documents..."):
st.session_state.processor.index_documents(docs_path)
# Search interface
query = st.text_input("Enter your question:")
if st.button("Search") and query:
with st.spinner("Searching..."):
results = st.session_state.processor.search(query)
if results:
# Generate answer and get cited references
context = "\n\n".join(
f"[{i}] {r.content}"
for i, r in enumerate(results)
)
answer, citations = generate_answer(query, context)
# Display results
st.subheader("Answer")
st.write(answer)
# Only show cited documents
if citations:
st.subheader("Referenced Documents")
for citation_num in sorted(citations):
if citation_num < len(results):
result = results[citation_num]
with st.expander(f"Reference [{citation_num}] - {Path(result.path).name}"):
st.write(result.content)
else:
st.info("No specific documents were cited in the answer.")
else:
st.warning("No relevant documents found")
if __name__ == "__main__":
main()This is the main function that drives the application. It provides a text input for the directory to index documents and a search bar for user queries.
From a given folder path containing various text files on different topics, this system processes and indexes the documents intelligently. When a user poses a question, it not only generates a relevant answer but also provides references to the source documents used to construct that answer. This approach ensures transparency and allows users to verify information directly from the source materials. The system leverages advanced natural language processing to understand queries and document content, enabling accurate matching between questions and the most relevant document sections.
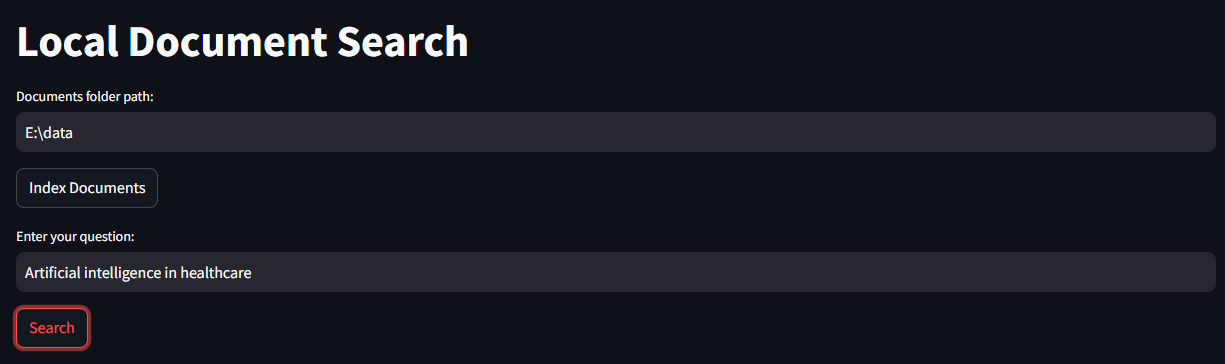

Congratulations on building your own Local Document Search Engine with Ollama! Your tool now can efficiently process and index various document formats, delivering relevant results based on user queries. This achievement marks just the beginning – you can enhance its capabilities by adding support for more document types, implementing advanced search features like semantic grouping and fuzzy matching, or building a more intuitive user interface with document previews and result highlighting. Consider boosting performance through caching and batch processing, and don’t forget about maintenance: keep your dependencies updated, monitor system performance. Whether you’re handling PDFs, spreadsheets, or complex databases, each enhancement you add will make your tool more powerful and user-friendly, creating a truly personalized search experience that respects data privacy while delivering intelligent results.




