
Large Language Models (LLMs) are profoundly changing how we interact with technology and process information, offering unprecedented capabilities from generating creative text to answering complex questions. However, simply using a pre-trained LLM isn’t always enough; to make them truly excel at specific tasks or behave in desired ways, they need further refinement. Here, we dive into advanced fine-tuning techniques for LLMs that leverage Reinforcement Learning (RL). We’ll explore various methods, including the widely used PPO and the broader RLHF paradigm, as well as newer, more efficient alternatives like RLAIF and DPO.
Initially, fine-tuning LLMs involved showing them more examples of desired text (a process called supervised fine-tuning). While effective for teaching specific writing styles or facts, it struggled to instill complex behaviors like “be helpful but never offensive” or “always follow safety guidelines.” This is where the power of Reinforcement Learning comes in. RL allows an LLM to learn through trial and error, guided by feedback, much like how a child learns what’s right or wrong.
Imagine training a dog: you don’t just show it pictures of good behavior; you reward it when it does something correctly and sometimes give negative feedback when it does something wrong. Reinforcement Learning applies a similar concept to AI. Here, the LLM tries to perform a task, and then it receives a “reward signal” based on how good its output was. Over many attempts, the LLM learns to generate outputs that maximize its reward.
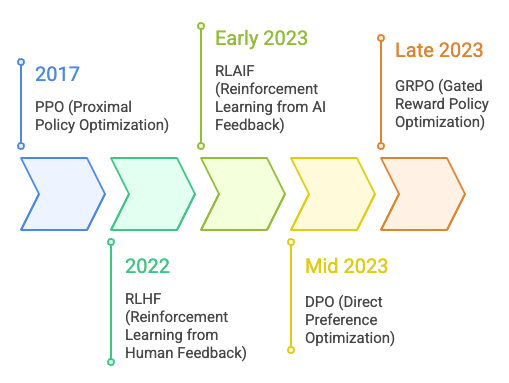
Evolution of Fine Tuning in LLM
PPO is a very popular and robust algorithm from the field of Reinforcement Learning. Think of PPO as a careful learner. When it tries to improve its “policy” (which is how the LLM decides what words to generate next), it takes small, controlled steps. These small steps are important because they prevent the learning process from becoming unstable or “jumping” too far in the wrong direction, which could make the LLM’s behavior worse instead of better. PPO is known for being quite stable and efficient in terms of how much data it needs to learn.
PPO gained significant fame because it was popularized by OpenAI in their fine-tuning pipeline for models like ‘GPT-3.5’ and ‘ChatGPT’. In these setups, PPO is used to optimize the LLM’s outputs based on a special “reward model.” This reward model acts like a strict teacher, giving the LLM a score for every response it generates. This score reflects human preferences, such as whether the response is helpful, harmless, honest, or well-written. The LLM then uses PPO to adjust its internal parameters so it generates responses that are more likely to get high scores from this reward model.
PPO relies heavily on a separate “reward model.” This reward model itself needs to be trained on vast amounts of human-labeled data, where humans have compared and ranked different LLM outputs based on preference. It is often applied after an initial phase of supervised fine-tuning (SFT), where the LLM is first taught basic conversational skills or task-specific knowledge from direct examples.
While stable, running PPO can be quite demanding on computing resources and complex to set up and scale effectively, especially with very large LLMs.
RLHF is not just a single algorithm, but a broader, powerful framework or “paradigm.” It’s about letting human preferences directly guide the reinforcement learning process. Instead of defining explicit rules for “good” behavior, humans simply provide feedback on which of several AI-generated outputs they prefer. This feedback is then converted into a reward signal that an RL algorithm (like PPO) can understand.
RLHF has been central to the alignment strategies for many leading conversational AI models, including ChatGPT. The process typically involves three main stages –
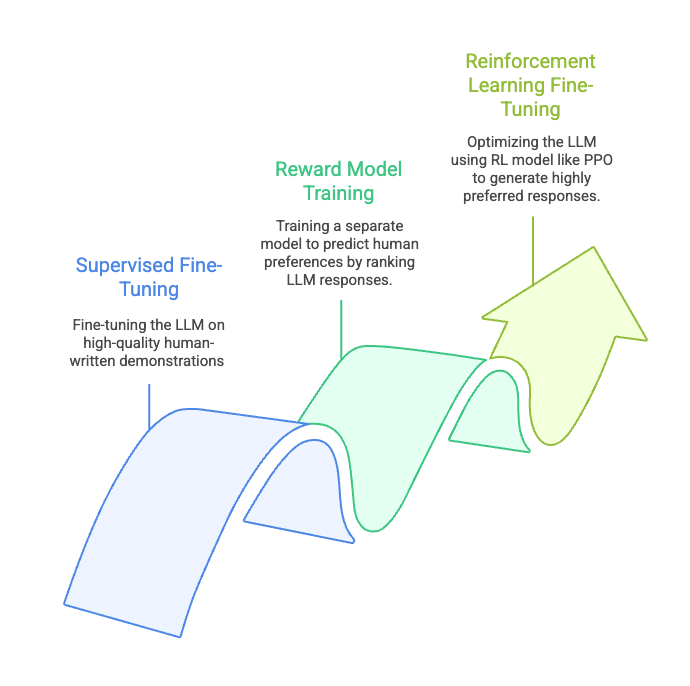
The stages of RLHF
In the first stage, i.e., Supervised Fine-Tuning LLM is first fine-tuned on a dataset of high-quality human-written demonstrations. This teaches the model to follow instructions and generate basic, coherent responses.
In the second stage, i.e., Reward Model Training, human annotators are presented with multiple responses generated by the SFT model for a given prompt. They rank these responses from best to worst. This human preference data is then used to train a separate “reward model” (usually a smaller neural network) that can predict a score for any given LLM output, reflecting human preference.
In the third stage, the SFT-trained LLM becomes the “policy” that we want to optimize. It interacts with its environment (generating text), and the newly trained reward model provides the “reward” signal. An RL algorithm (like PPO) then updates the LLM’s parameters to maximize these rewards, making it generate responses that are highly preferred by humans.
In an AI assistant that is not only informative but also genuinely helpful, polite, and avoids harmful content, RLHF is what teaches the AI to refuse inappropriate requests, apologize when mistaken, or engage in a friendly tone, even if these behaviors weren’t explicitly coded.
RLHF has been absolutely central to aligning modern conversational AI systems, making them behave in ways that are generally considered more helpful, harmless, and honest. It’s highly effective at reducing undesirable behaviors like generating toxic content, biases, or misinformation, while boosting helpfulness and adherence to instructions.
RLAIF is a fascinating and newer alternative to RLHF. As the name suggests, it replaces the human element in the feedback loop with feedback generated by another AI model. Instead of relying on costly and time-consuming human annotation, a powerful “teacher model” (often a larger, already well-aligned LLM) is used to generate the preferences or rankings for the outputs of a “student model.”
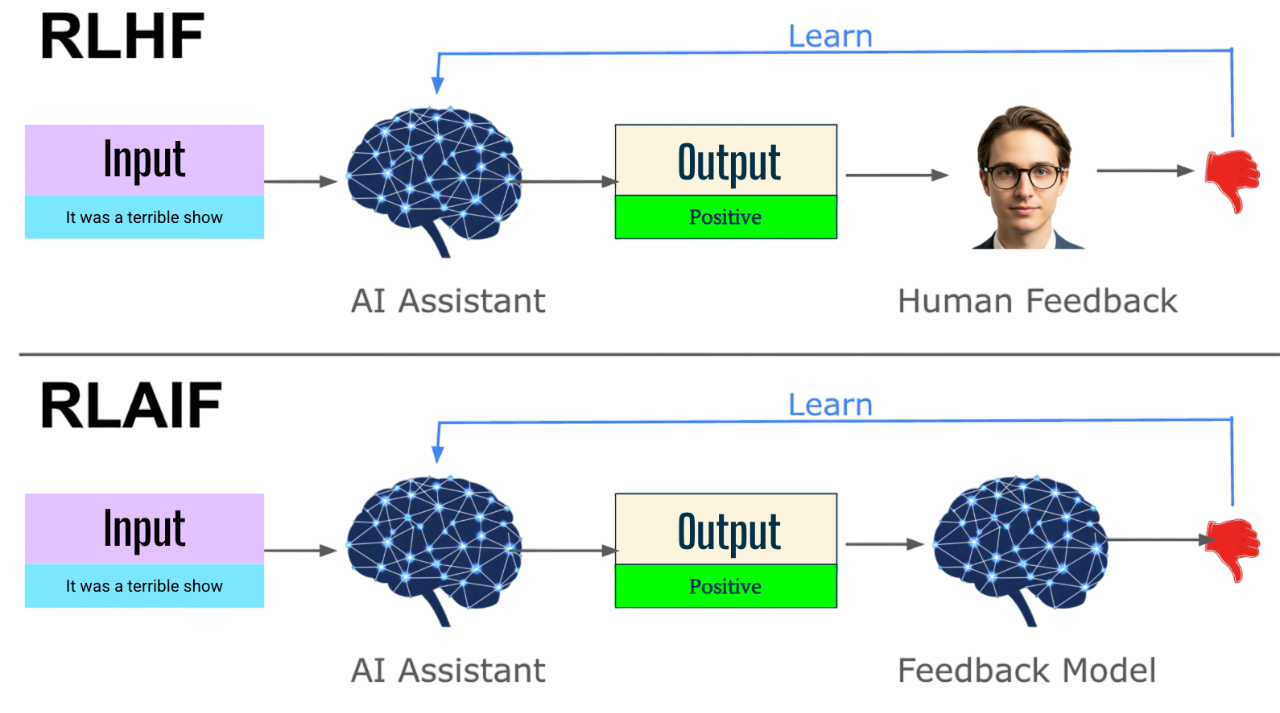
Workflow of RLHF vs RLAIF
The primary motivation for RLAIF is to reduce dependence on expensive human annotation. The process is similar to RLHF, but the crucial difference is in how the reward signal is obtained. The student LLM generates responses, and instead of humans ranking them, a strong, pre-trained teacher LLM evaluates and ranks these responses. This AI-generated feedback is then used to train the reward model (or directly as preference data for methods like DPO), which in turn fine-tunes the student LLM using RL. RLAIF can be particularly useful for quickly iterating on alignment or for “bootstrapping” alignment in new, smaller models based on the knowledge of a larger, well-aligned model.
For example, say you’ve trained a new, smaller LLM for a specific task. Instead of hiring many human annotators to align it, you use a very powerful, already aligned LLM (like GPT-4 or Gemini Advanced) to generate preference data for your smaller model’s outputs. This allows for faster and more scalable alignment.
By automating the feedback generation, RLAIF can significantly reduce the cost and time associated with human annotation, making alignment more scalable. It’s valuable for quickly transferring alignment principles from a powerful teacher model to less capable student models. The effectiveness and quality of RLAIF-based alignment are highly dependent on the quality and alignment of the teacher model used to generate the feedback. If the teacher model is biased or flawed, it can pass those issues on.
DPO represents a significant simplification in the alignment process. Unlike PPO and RLHF, which require training a separate reward model and then performing complex reinforcement learning, DPO is a non-RL method. It directly optimizes the LLM’s likelihood to prefer preferred outputs over dispreferred ones, using a cleverly designed loss function. It essentially learns preferences without needing an explicit reward model or the often-tricky sampling process from a policy.
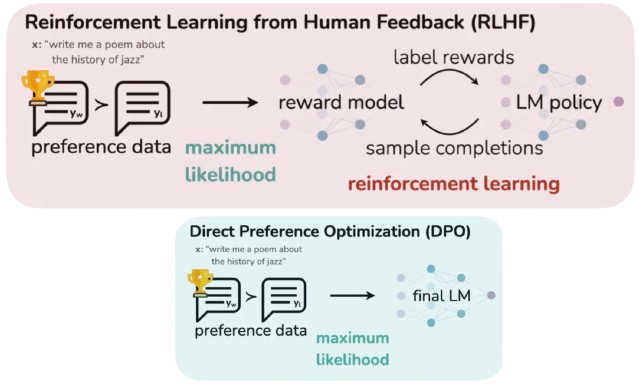
Workflow from DPO paper
DPO is emerging as a simpler, more stable, and often equally effective alternative to the multi-stage RLHF pipeline. Instead of having an LLM generate responses, a human (or AI, as in RLAIF) simply provides pairs of outputs, one preferred and one dispreferred for a given prompt. DPO then defines a loss function that directly encourages the LLM to assign a higher probability to the preferred response and a lower probability to the dispreferred response. This direct optimization eliminates the need to train a separate reward model and avoids the complexities and instability often associated with RL training.
For example assume you’ve collected a dataset where, for a given question, you have two possible answers, and you know which one is better. DPO can directly fine-tune your LLM to always choose the better answer, without you needing to build a reward model. This is excellent for simple safety alignments (e.g., preferred: harmless response, dispreferred: harmful response).
DPO is generally much easier to implement and train compared to PPO and the full RLHF pipeline, as it bypasses the need for a separate reward model and the complexities of RL training. It has been shown to achieve competitive (and sometimes even superior) results compared to RLHF with PPO on various alignment tasks. It only requires pairs of preferred and dispreferred outputs, directly optimizing the model’s behavior towards these preferences.
GRPO is a more generalized version of reinforcement learning fine-tuning. It aims to find a middle ground between maximizing a reward function (like PPO) and simply imitating a set of good demonstrations (imitation learning). It weights the “trajectories” (sequences of actions or generated text) based on how good their estimated “return” (total reward) is.

Workflow of GRPO
GRPO attempts to unify the benefits of PPO (reward maximization) and imitation learning (staying close to known good examples) within a single framework. It’s particularly suitable when the reward scores might be noisy, hard to get consistently, or when you have some good example outputs but also want the LLM to explore and improve beyond them based on a reward signal. It balances between aggressively maximizing the reward and staying within a reasonable “comfort zone” defined by demonstration data.
For example imagine you have some perfectly written sample-dialogues for a chatbot, but you also have a reward model that can score new, generated dialogues. GRPO can fine-tune the chatbot to produce responses that are both similar to your perfect examples and achieve high scores from the reward model.
It can make good use of available data while aiming to combine the strengths of maximizing rewards and staying close to demonstration data, which can be beneficial in complex alignment scenarios. GRPO is a newer and more academic technique compared to PPO or DPO, and it’s not yet as widely adopted in industry due to ongoing research and less mature tooling.
The journey of fine-tuning Large Language Models is constantly evolving, with a clear trend towards making them not just powerful, but also helpful, harmless, and aligned with human values. Techniques like PPO and the broader RLHF framework have been instrumental in this alignment revolution, enabling models like ChatGPT to respond safely and appropriately. Newer innovations like RLAIF and DPO are pushing the boundaries of efficiency and simplicity, making advanced fine-tuning more accessible and scalable. As these techniques continue to mature, they will play an increasingly vital role in shaping the behavior of future AI systems, ensuring they are not only intelligent but also responsible and beneficial for humanity.




![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

