
Large Language Models (LLMs) increasingly solve complex problems by breaking them into reasoning steps using methods like Chain-of-Thought (CoT). However, ensuring each intermediate step is logically valid remains a major challenge. Traditional Process Reward Models (PRMs) provide step-level feedback, but they act as black-box classifiers offering labels without explanations and often struggling to generalize. To address this, Meta and its collaborator researchers introduced StepWiser, a stepwise generative judge that reasons about reasoning. By producing analytical rationales before verdicts, StepWiser not only improves evaluation accuracy but also enhances training and inference-time performance
Let’s get started with an introduction to StepWiser.
Traditional PRMs are discriminative models that assign a score or label to each reasoning step, but they lack the ability to explain their judgment. This makes them opaque and difficult to debug. STEPWISER, on the other hand, is a generative judge. It’s trained to perform meta-reasoning, that is, it reasons about the reasoning steps of another model. The judge “shows its work,” which makes the review process more accurate and visible, by producing its own Chain-of-Thought (CoT) analysis prior to rendering a decision. By framing the evaluation as a reasoning problem, this paradigm shift makes use of LLMs’ innate capabilities to offer a more comprehensive and instructive type of feedback.
The StepWiser pipeline integrates reasoning and evaluation in three stages
Chunked CoT Generation
In order to self segment reasoning into meaningful, independent steps, base models are refined in a manner where every step has a distinct logical goal, preventing disjointed or duplicate reasoning and guaranteeing that the ideas are presented in logically sound, cohesive pieces.

Segmentation: Newlines vs Chunks
Stepwise Annotation
Each reasoning chunk is annotated through outcome comparisons made before and after the chunk, allowing the system to assess its contribution to the overall solution. Monte Carlo simulations are then used to estimate Q-values, providing a measure of step quality that captures the likelihood of success from that point forward.
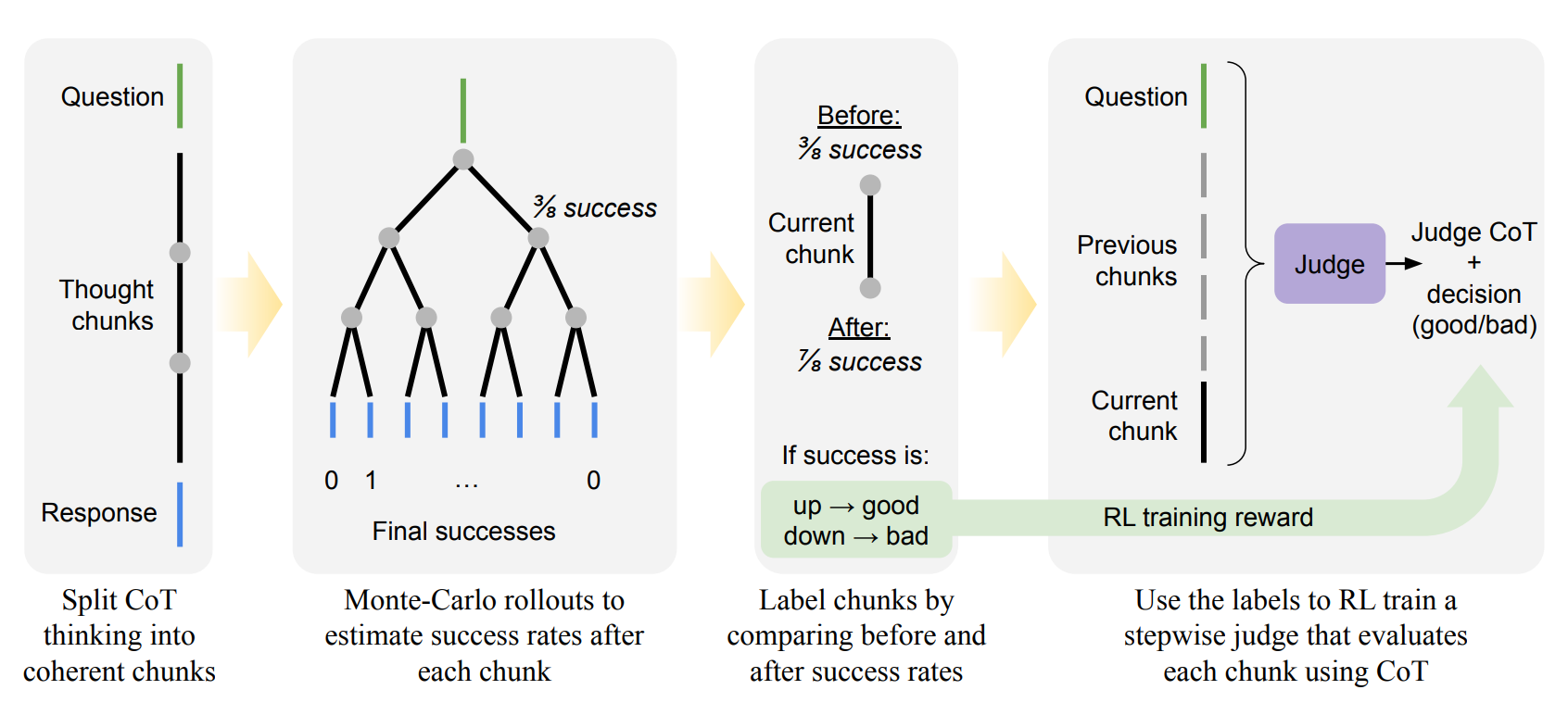
Overview of STEPWISER training method
Generative Judge Training
The judge model is trained with reinforcement learning to generate its own explanatory chain of thought before delivering a verdict. This approach of reasoning-about-reasoning, known as meta-reasoning, enhances transparency and yields significantly higher accuracy compared to traditional discriminative baselines.

Prompt Template for STEPWISER judge
STEPWISER presents a revolutionary self-segmentation strategy to overcome the drawbacks of common heuristic-based approaches, such as splitting by newlines, which frequently lead to stages in reasoning that are fragmented and illogical. The authors refer to this technique as “chunks-of-thought” because it automatically divides the fundamental policy model’s Chain-of-Thought (CoT) into manageable chunks. A single goal or an independent step in the problem-solving process is represented by these sections, which are intended to be logically comprehensive, instructive, and cohesive. In the end, this capacity improves evaluation accuracy and computing efficiency by giving the generative judge model that follows more contextually rich and relevant units to evaluate.
<chunk>
To solve for x, we isolate the variable by subtracting 2 from both sides.
</chunk>
<chunk>
Now we divide both sides by 3 to get the final result.
</chunk>
In a given trajectory, the approach compares the results of Monte Carlo rollouts before and after each reasoning piece to assign a binary label. The ultimate rewards of several completions produced from that point on are averaged to determine the step’s Q-value, which stands for the anticipated final reward. The step is designated as “Positive” if the Q-value is higher than zero. A value of 0 indicates that the step is ‘Negative’. The term Absolute Q-value thresholding (Abs-Q) describes this.
These labels are then used to perform online reinforcement learning (RL) to train the stepwise judge. The judge is formulated as a generative model that first produces an analytical rationale, or its own CoT reasoning, and then concludes with a final judgment, such as {Positive} or {Negative}. This approach, which uses GRPO as its optimization algorithm , forces the judge to “show its work” and provides a more transparent and accurate evaluation process.
A real-world implementation of the STEPWISER judge, which directs the policy model’s reasoning process throughout generation, is inference-time correction. Each “chunk-of-thought” that the model generates is assessed by the judge. A chunk is deleted and the policy model is prompted to generate a new chunk from the same place in the reasoning route if the judge finds it to be “bad” or faulty. This procedure, called chunk-reset reasoning, improves the quality of the final solution by enabling the model to self-correct and investigate more effective reasoning paths. On tasks like MATH500 and NuminaMath-Heldout-1K, the STEPWISER technique improves performance by 5-7% when compared to baselines, resulting in notable gains in final accuracy.
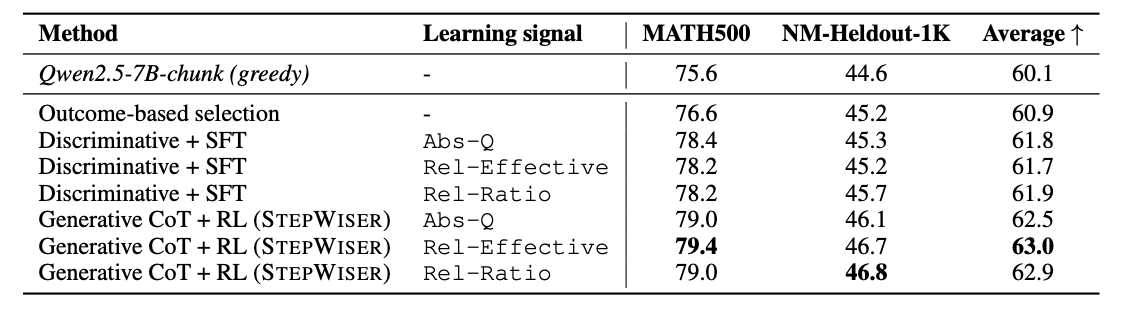
Evaluation Results
The authors conducted a series of ablation studies to demonstrate the importance of each component of the StepWiser framework.
Ablating RL
A judge trained with rejection sampling fine-tuning (RS-FT), an offline method, achieved an average score of only 23.1, substantially lower than the RL-trained StepWiser’s score of 36.2. This indicates that offline methods are insufficient and that online RL is a critical component for stable learning.
Ablating CoT
A discriminative judge trained with RL fell short of the full StepWiser model, achieving an average score of 34.3 compared to StepWiser’s 36.2. This shows that the generative CoT format provides a more expressive and informative structure for learning, especially with stronger base models.
Ablating Prompt Dataset Balancing
Removing this crucial balancing step caused a significant performance drop, with the average ProcessBench score for the 7B model dropping from 60.5 to 47.9. Without balancing, the model develops a strong bias toward predicting positive examples, leading to training instability and model collapse.
StepWiser’s data annotation technique is computationally costly; for the Qwen2.5-7B-chunk model, it takes about 14 days on 8 A100 GPUs. This is lessened by the self-segmentation fine-tuning, which drastically cuts down on the number of chunks that require annotation, saving a significant amount of computation and time.The authors also note a challenge with rapid entropy decrease during RL training, particularly for the 7B model, which they address with a “clip higher” technique. Future work could explore more advanced methods to alleviate this issue.
StepWiser marks a shift in how LLM reasoning is supervised. By making the evaluation process generative and interpretable, it outperforms traditional black-box judges while offering transparency and robustness. For practitioners, StepWiser is valuable not only in academic benchmarks but also in real-world AI systems where correctness, explainability, and adaptability are essential.




![[Upcoming Webinar] Autonomous Enterprises: How to leverage Agentic AI in Enterprises?](https://adasci.org/wp-content/uploads/2025/10/Adasci-Webinar-1-300x300.png)

